 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsynchronous LLM Function Calling
Dec 09, 2024Large language models (LLMs) use function calls to interface with external tools and data source. However, the current approach to LLM function calling is inherently synchronous, where each call blocks LLM inference, limiting LLM operation and concurrent function execution. In this work, we propose AsyncLM, a system for asynchronous LLM function calling. AsyncLM improves LLM's operational efficiency by enabling LLMs to generate and execute function calls concurrently. Instead of waiting for each call's completion, AsyncLM introduces an interrupt mechanism to asynchronously notify the LLM in-flight when function calls return. We design an in-context protocol for function calls and interrupts, provide fine-tuning strategy to adapt LLMs to the interrupt semantics, and implement these mechanisms efficiently on LLM inference process. We demonstrate that AsyncLM can reduce end-to-end task completion latency from 1.6x-5.4x compared to synchronous function calling on a set of benchmark tasks in the Berkeley function calling leaderboard (BFCL). Furthermore, we discuss how interrupt mechanisms can be extended to enable novel human-LLM or LLM-LLM interactions.
Confidential Prompting: Protecting User Prompts from Cloud LLM Providers
Sep 27, 2024

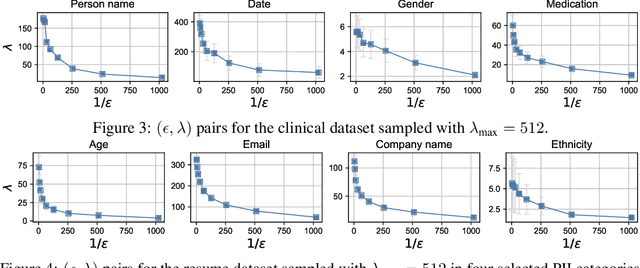
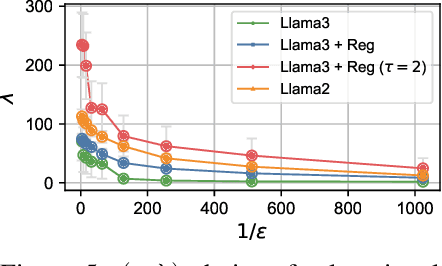
Our work tackles the challenge of securing user inputs in cloud-based large language model (LLM) services while ensuring output consistency, model confidentiality, and compute efficiency. We introduce Secure Multi-party Decoding (SMD), which leverages confidential computing to confine user prompts to a trusted execution environment, namely a confidential virtual machine (CVM), while allowing service providers to generate tokens efficiently. We also introduce a novel cryptographic method, Prompt Obfuscation (PO), to ensure robustness against reconstruction attacks on SMD. We demonstrate that our approach preserves both prompt confidentiality and LLM serving efficiency. Our solution can enable privacy-preserving cloud LLM services that handle sensitive prompts, such as clinical records, financial data, and personal information.
Prompt Cache: Modular Attention Reuse for Low-Latency Inference
Nov 07, 2023



We present Prompt Cache, an approach for accelerating inference for large language models (LLM) by reusing attention states across different LLM prompts. Many input prompts have overlapping text segments, such as system messages, prompt templates, and documents provided for context. Our key insight is that by precomputing and storing the attention states of these frequently occurring text segments on the inference server, we can efficiently reuse them when these segments appear in user prompts. Prompt Cache employs a schema to explicitly define such reusable text segments, called prompt modules. The schema ensures positional accuracy during attention state reuse and provides users with an interface to access cached states in their prompt. Using a prototype implementation, we evaluate Prompt Cache across several LLMs. We show that Prompt Cache significantly reduce latency in time-to-first-token, especially for longer prompts such as document-based question answering and recommendations. The improvements range from 8x for GPU-based inference to 60x for CPU-based inference, all while maintaining output accuracy and without the need for model parameter modifications.