 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidential Prompting: Protecting User Prompts from Cloud LLM Providers
Paper and Code
Sep 27, 2024

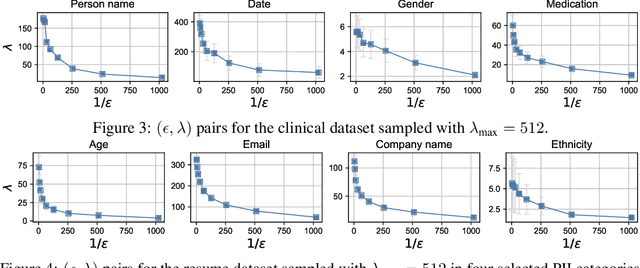
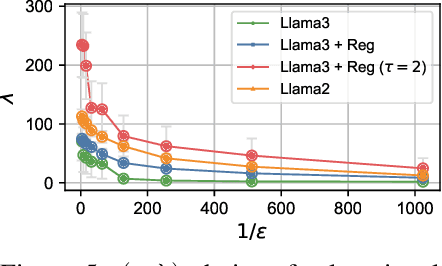
Our work tackles the challenge of securing user inputs in cloud-based large language model (LLM) services while ensuring output consistency, model confidentiality, and compute efficiency. We introduce Secure Multi-party Decoding (SMD), which leverages confidential computing to confine user prompts to a trusted execution environment, namely a confidential virtual machine (CVM), while allowing service providers to generate tokens efficiently. We also introduce a novel cryptographic method, Prompt Obfuscation (PO), to ensure robustness against reconstruction attacks on SMD. We demonstrate that our approach preserves both prompt confidentiality and LLM serving efficiency. Our solution can enable privacy-preserving cloud LLM services that handle sensitive prompts, such as clinical records, financial data, and personal information.