 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniOQA: A Unified Framework for Knowledge Graph Question Answering with Large Language Models
Jun 04, 2024OwnThink stands as the most extensive Chinese open-domain knowledge graph introduced in recent times. Despite prior attempts in question answering over OwnThink (OQA), existing studies have faced limitations in model representation capabilities, posing challenges in further enhancing overall accuracy in question answering. In this paper, we introduce UniOQA, a unified framework that integrates two complementary parallel workflows. Unlike conventional approaches, UniOQA harnesses large language models (LLMs) for precise question answering and incorporates a direct-answer-prediction process as a cost-effective complement. Initially, to bolster representation capacity, we fine-tune an LLM to translate questions into the Cypher query language (CQL), tackling issues associated with restricted semantic understanding and hallucinations. Subsequently, we introduce the Entity and Relation Replacement algorithm to ensure the executability of the generated CQL. Concurrently, to augment overall accuracy in question answering, we further adapt the Retrieval-Augmented Generation (RAG) process to the knowledge graph. Ultimately, we optimize answer accuracy through a dynamic decision algorithm. Experimental findings illustrate that UniOQA notably advances SpCQL Logical Accuracy to 21.2% and Execution Accuracy to 54.9%, achieving the new state-of-the-art results on this benchmark. Through ablation experiments, we delve into the superior representation capacity of UniOQA and quantify its performance breakthrough.
AdaSpring: Context-adaptive and Runtime-evolutionary Deep Model Compression for Mobile Applications
Jan 28, 2021

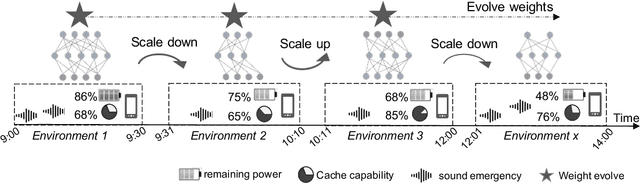
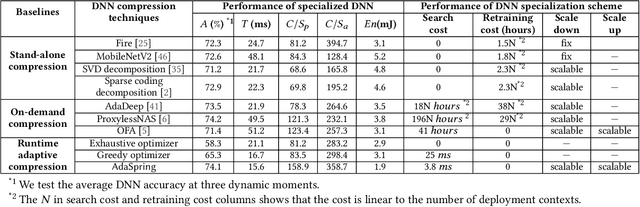
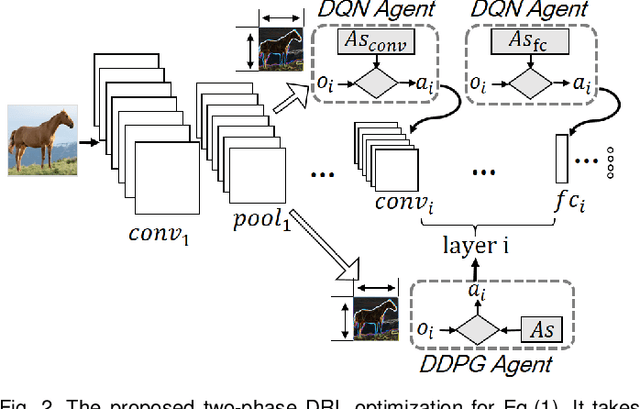
There are many deep learning (e.g., DNN) powered mobile and wearable applications today continuously and unobtrusively sensing the ambient surroundings to enhance all aspects of human lives. To enable robust and private mobile sensing, DNN tends to be deployed locally on the resource-constrained mobile devices via model compression. The current practice either hand-crafted DNN compression techniques, i.e., for optimizing DNN-relative performance (e.g., parameter size), or on-demand DNN compression methods, i.e., for optimizing hardware-dependent metrics (e.g., latency), cannot be locally online because they require offline retraining to ensure accuracy. Also, none of them have correlated their efforts with runtime adaptive compression to consider the dynamic nature of the deployment context of mobile applications. To address those challenges, we present AdaSpring, a context-adaptive and self-evolutionary DNN compression framework. It enables the runtime adaptive DNN compression locally online. Specifically, it presents the ensemble training of a retraining-free and self-evolutionary network to integrate multiple alternative DNN compression configurations (i.e., compressed architectures and weights). It then introduces the runtime search strategy to quickly search for the most suitable compression configurations and evolve the corresponding weights. With evaluation on five tasks across three platforms and a real-world case study, experiment outcomes show that AdaSpring obtains up to 3.1x latency reduction, 4.2 x energy efficiency improvement in DNNs, compared to hand-crafted compression techniques, while only incurring <= 6.2ms runtime-evolution latency.
AdaDeep: A Usage-Driven, Automated Deep Model Compression Framework for Enabling Ubiquitous Intelligent Mobiles
Jun 08, 2020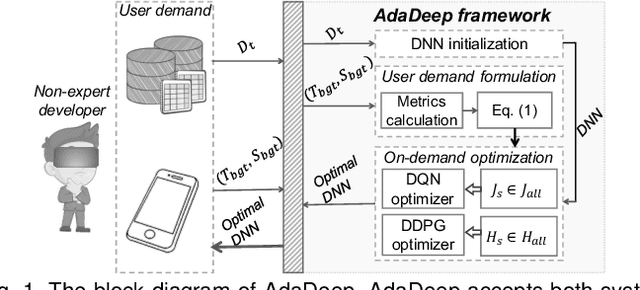

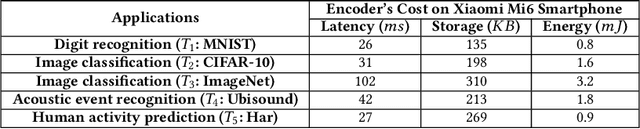
Recent breakthroughs in Deep Neural Networks (DNNs) have fueled a tremendously growing demand for bringing DNN-powered intelligence into mobile platforms. While the potential of deploying DNNs on resource-constrained platforms has been demonstrated by DNN compression techniques, the current practice suffers from two limitations: 1) merely stand-alone compression schemes are investigated even though each compression technique only suit for certain types of DNN layers; and 2) mostly compression techniques are optimized for DNNs' inference accuracy, without explicitly considering other application-driven system performance (e.g., latency and energy cost) and the varying resource availability across platforms (e.g., storage and processing capability). To this end, we propose AdaDeep, a usage-driven, automated DNN compression framework for systematically exploring the desired trade-off between performance and resource constraints, from a holistic system level. Specifically, in a layer-wise manner, AdaDeep automatically selects the most suitable combination of compression techniques and the corresponding compression hyperparameters for a given DNN. Thorough evaluations on six datasets and across twelve devices demonstrate that AdaDeep can achieve up to $18.6\times$ latency reduction, $9.8\times$ energy-efficiency improvement, and $37.3\times$ storage reduction in DNNs while incurring negligible accuracy loss. Furthermore, AdaDeep also uncovers multiple novel combinations of compression techniques.
Privacy Adversarial Network: Representation Learning for Mobile Data Privacy
Jun 08, 2020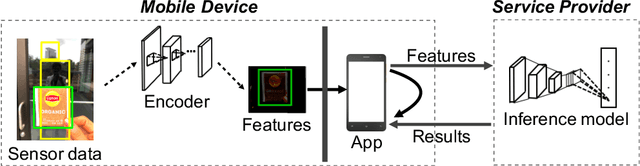

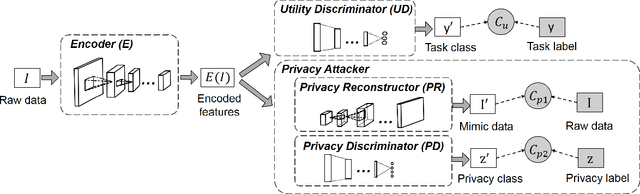
The remarkable success of machine learning has fostered a growing number of cloud-based intelligent services for mobile users. Such a service requires a user to send data, e.g. image, voice and video, to the provider, which presents a serious challenge to user privacy. To address this, prior works either obfuscate the data, e.g. add noise and remove identity information, or send representations extracted from the data, e.g. anonymized features. They struggle to balance between the service utility and data privacy because obfuscated data reduces utility and extracted representation may still reveal sensitive information. This work departs from prior works in methodology: we leverage adversarial learning to a better balance between privacy and utility. We design a \textit{representation encoder} that generates the feature representations to optimize against the privacy disclosure risk of sensitive information (a measure of privacy) by the \textit{privacy adversaries}, and concurrently optimize with the task inference accuracy (a measure of utility) by the \textit{utility discriminator}. The result is the privacy adversarial network (\systemname), a novel deep model with the new training algorithm, that can automatically learn representations from the raw data. Intuitively, PAN adversarially forces the extracted representations to only convey the information required by the target task. Surprisingly, this constitutes an implicit regularization that actually improves task accuracy. As a result, PAN achieves better utility and better privacy at the same time! We report extensive experiments on six popular datasets and demonstrate the superiority of \systemname compared with alternative methods reported in prior work.
Better accuracy with quantified privacy: representations learned via reconstructive adversarial network
Jan 25, 2019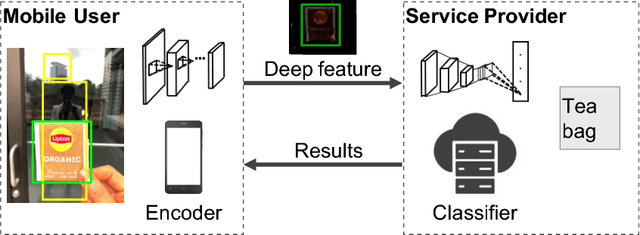
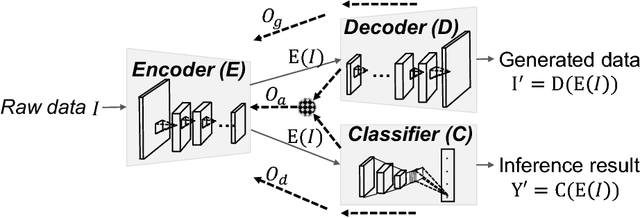
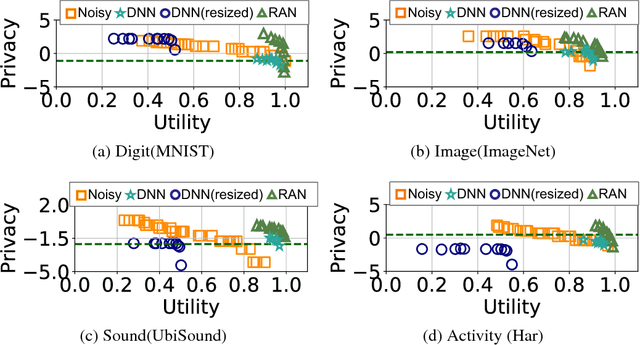
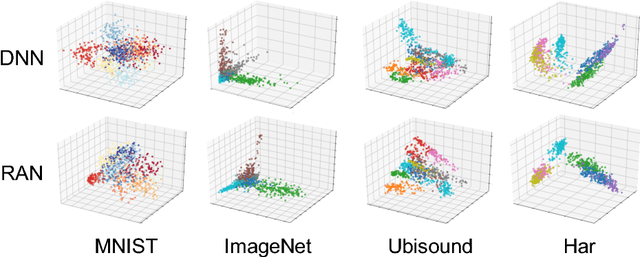
The remarkable success of machine learning, especially deep learning, has produced a variety of cloud-based services for mobile users. Such services require an end user to send data to the service provider, which presents a serious challenge to end-user privacy. To address this concern, prior works either add noise to the data or send features extracted from the raw data. They struggle to balance between the utility and privacy because added noise reduces utility and raw data can be reconstructed from extracted features. This work represents a methodical departure from prior works: we balance between a measure of privacy and another of utility by leveraging adversarial learning to find a sweeter tradeoff. We design an encoder that optimizes against the reconstruction error (a measure of privacy), adversarially by a Decoder, and the inference accuracy (a measure of utility) by a Classifier. The result is RAN, a novel deep model with a new training algorithm that automatically extracts features for classification that are both private and useful. It turns out that adversarially forcing the extracted features to only conveys the intended information required by classification leads to an implicit regularization leading to better classification accuracy than the original model which completely ignores privacy. Thus, we achieve better privacy with better utility, a surprising possibility in machine learning! We conducted extensive experiments on five popular datasets over four training schemes, and demonstrate the superiority of RAN compared with existing alternatives.