 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Channel Charting: An LSTM-AE-based Approach
Jan 26, 2026With the development of the sixth-generation (6G) communication system, Channel State Information (CSI) plays a crucial role in improving network performance. Traditional Channel Charting (CC) methods map high-dimensional CSI data to low-dimensional spaces to help reveal the geometric structure of wireless channels. However, most existing CC methods focus on learning static geometric structures and ignore the dynamic nature of the channel over time, leading to instability and poor topological consistency of the channel charting in complex environments. To address this issue, this paper proposes a novel time-series channel charting approach based on the integration of Long Short-Term Memory (LSTM) networks and Auto encoders (AE) (LSTM-AE-CC). This method incorporates a temporal modeling mechanism into the traditional CC framework, capturing temporal dependencies in CSI using LSTM and learning continuous latent representations with AE. The proposed method ensures both geometric consistency of the channel and explicit modeling of the time-varying properties. Experimental results demonstrate that the proposed method outperforms traditional CC methods in various real-world communication scenarios, particularly in terms of channel charting stability, trajectory continuity, and long-term predictability.
Efficient UAV trajectory prediction: A multi-modal deep diffusion framework
Jan 26, 2026To meet the requirements for managing unauthorized UAVs in the low-altitude economy, a multi-modal UAV trajectory prediction method based on the fusion of LiDAR and millimeter-wave radar information is proposed. A deep fusion network for multi-modal UAV trajectory prediction, termed the Multi-Modal Deep Fusion Framework, is designed. The overall architecture consists of two modality-specific feature extraction networks and a bidirectional cross-attention fusion module, aiming to fully exploit the complementary information of LiDAR and radar point clouds in spatial geometric structure and dynamic reflection characteristics. In the feature extraction stage, the model employs independent but structurally identical feature encoders for LiDAR and radar. After feature extraction, the model enters the Bidirectional Cross-Attention Mechanism stage to achieve information complementarity and semantic alignment between the two modalities. To verify the effectiveness of the proposed model, the MMAUD dataset used in the CVPR 2024 UG2+ UAV Tracking and Pose-Estimation Challenge is adopted as the training and testing dataset. Experimental results show that the proposed multi-modal fusion model significantly improves trajectory prediction accuracy, achieving a 40% improvement compared to the baseline model. In addition, ablation experiments are conducted to demonstrate the effectiveness of different loss functions and post-processing strategies in improving model performance. The proposed model can effectively utilize multi-modal data and provides an efficient solution for unauthorized UAV trajectory prediction in the low-altitude economy.
Effective outdoor pathloss prediction: A multi-layer segmentation approach with weighting map
Jan 13, 2026Predicting pathloss by considering the physical environment is crucial for effective wireless network planning. Traditional methods, such as ray tracing and model-based approaches, often face challenges due to high computational complexity and discrepancies between models and real-world environments. In contrast, deep learning has emerged as a promising alternative, offering accurate path loss predictions with reduced computational complexity. In our research, we introduce a ResNet-based model designed to enhance path loss prediction. We employ innovative techniques to capture key features of the environment by generating transmission (Tx) and reception (Rx) depth maps, as well as a distance map from the geographic data. Recognizing the significant attenuation caused by signal reflection and diffraction, particularly at high frequencies, we have developed a weighting map that emphasizes the areas adjacent to the direct path between Tx and Rx for path loss prediction. {Extensive simulations demonstrate that our model outperforms PPNet, RPNet, and Vision Transformer (ViT) by 1.2-3.0 dB using dataset of ITU challenge 2024 and ICASSP 2023. In addition, the floating point operations (FLOPs) of the proposed model is 60\% less than those of benchmarks.} Additionally, ablation studies confirm that the inclusion of the weighting map significantly enhances prediction performance.
Grade Like a Human: Rethinking Automated Assessment with Large Language Models
May 30, 2024



While large language models (LLMs) have been used for automated grading, they have not yet achieved the same level of performance as humans, especially when it comes to grading complex questions. Existing research on this topic focuses on a particular step in the grading procedure: grading using predefined rubrics. However, grading is a multifaceted procedure that encompasses other crucial steps, such as grading rubrics design and post-grading review. There has been a lack of systematic research exploring the potential of LLMs to enhance the entire grading~process. In this paper, we propose an LLM-based grading system that addresses the entire grading procedure, including the following key components: 1) Developing grading rubrics that not only consider the questions but also the student answers, which can more accurately reflect students' performance. 2) Under the guidance of grading rubrics, providing accurate and consistent scores for each student, along with customized feedback. 3) Conducting post-grading review to better ensure accuracy and fairness. Additionally, we collected a new dataset named OS from a university operating system course and conducted extensive experiments on both our new dataset and the widely used Mohler dataset. Experiments demonstrate the effectiveness of our proposed approach, providing some new insights for developing automated grading systems based on LLMs.
OpenBA-V2: Reaching 77.3% High Compression Ratio with Fast Multi-Stage Pruning
May 09, 2024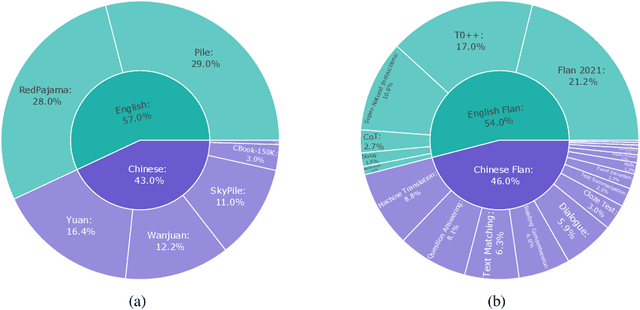

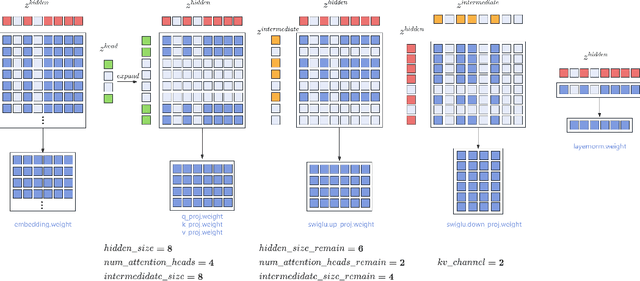
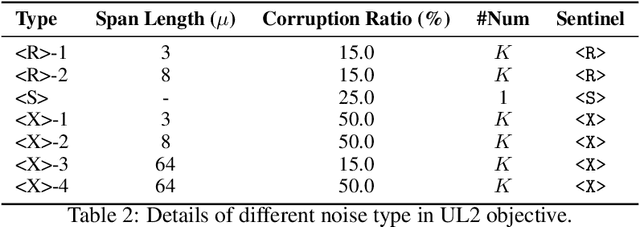
Large Language Models (LLMs) have played an important role in many fields due to their powerful capabilities.However, their massive number of parameters leads to high deployment requirements and incurs significant inference costs, which impedes their practical applications. Training smaller models is an effective way to address this problem. Therefore, we introduce OpenBA-V2, a 3.4B model derived from multi-stage compression and continual pre-training from the original 15B OpenBA model. OpenBA-V2 utilizes more data, more flexible training objectives, and techniques such as layer pruning, neural pruning, and vocabulary pruning to achieve a compression rate of 77.3\% with minimal performance loss. OpenBA-V2 demonstrates competitive performance compared to other open-source models of similar size, achieving results close to or on par with the 15B OpenBA model in downstream tasks such as common sense reasoning and Named Entity Recognition (NER). OpenBA-V2 illustrates that LLMs can be compressed into smaller ones with minimal performance loss by employing advanced training objectives and data strategies, which may help deploy LLMs in resource-limited scenarios.
Timely Fusion of Surround Radar/Lidar for Object Detection in Autonomous Driving Systems
Sep 09, 2023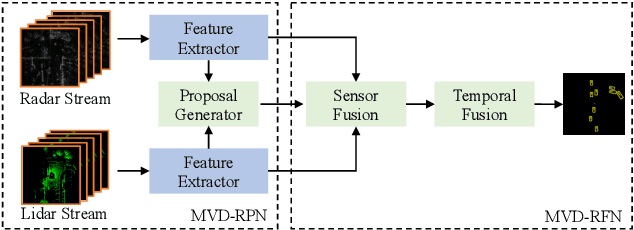
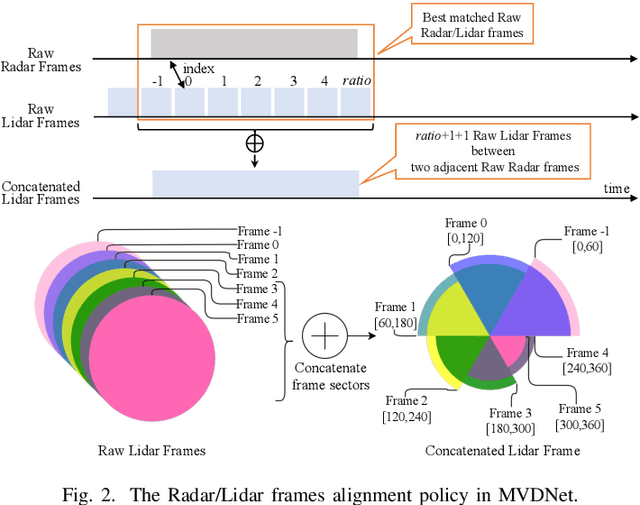
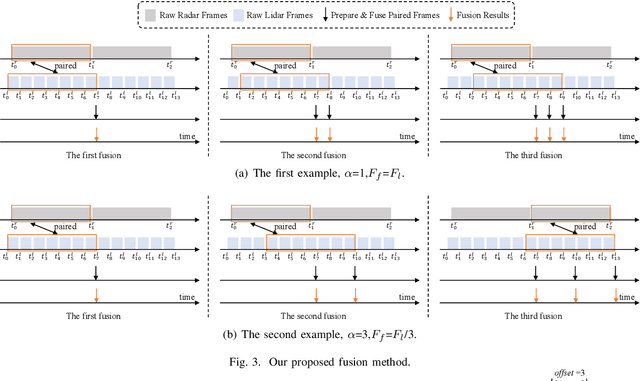
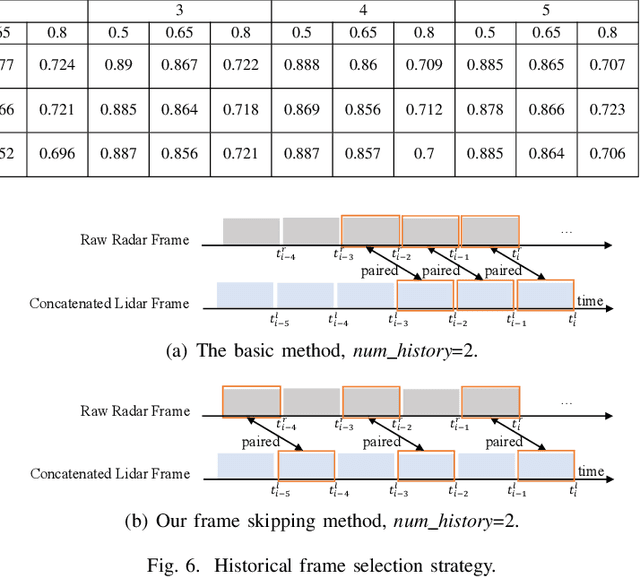
Fusing Radar and Lidar sensor data can fully utilize their complementary advantages and provide more accurate reconstruction of the surrounding for autonomous driving systems. Surround Radar/Lidar can provide 360-degree view sampling with the minimal cost, which are promising sensing hardware solutions for autonomous driving systems. However, due to the intrinsic physical constraints, the rotating speed of surround Radar, and thus the frequency to generate Radar data frames, is much lower than surround Lidar. Existing Radar/Lidar fusion methods have to work at the low frequency of surround Radar, which cannot meet the high responsiveness requirement of autonomous driving systems.This paper develops techniques to fuse surround Radar/Lidar with working frequency only limited by the faster surround Lidar instead of the slower surround Radar, based on the state-of-the-art object detection model MVDNet. The basic idea of our approach is simple: we let MVDNet work with temporally unaligned data from Radar/Lidar, so that fusion can take place at any time when a new Lidar data frame arrives, instead of waiting for the slow Radar data frame. However, directly applying MVDNet to temporally unaligned Radar/Lidar data greatly degrades its object detection accuracy. The key information revealed in this paper is that we can achieve high output frequency with little accuracy loss by enhancing the training procedure to explore the temporal redundancy in MVDNet so that it can tolerate the temporal unalignment of input data. We explore several different ways of training enhancement and compare them quantitatively with experiments.