 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAPO: Flawed-Aware Policy Optimization for Efficient and Reliable Reasoning
Oct 26, 2025Reinforcement learning with verifiable rewards (RLVR) has emerged as a promising paradigm for enhancing the reasoning capabilities of large language models (LLMs). In this context, models explore reasoning trajectories and exploit rollouts with correct answers as positive signals for policy optimization. However, these rollouts might involve flawed patterns such as answer-guessing and jump-in-reasoning. Such flawed-positive rollouts are rewarded identically to fully correct ones, causing policy models to internalize these unreliable reasoning patterns. In this work, we first conduct a systematic study of flawed-positive rollouts in RL and find that they enable rapid capability gains during the early optimization stage, while constraining reasoning capability later by reinforcing unreliable patterns. Building on these insights, we propose Flawed-Aware Policy Optimization (FAPO), which presents a parameter-free reward penalty for flawed-positive rollouts, enabling the policy to leverage them as useful shortcuts in the warm-up stage, securing stable early gains, while gradually shifting optimization toward reliable reasoning in the later refinement stage. To accurately and comprehensively detect flawed-positive rollouts, we introduce a generative reward model (GenRM) with a process-level reward that precisely localizes reasoning errors. Experiments show that FAPO is effective in broad domains, improving outcome correctness, process reliability, and training stability without increasing the token budget.
Towards DS-NER: Unveiling and Addressing Latent Noise in Distant Annotations
May 18, 2025Distantly supervised named entity recognition (DS-NER) has emerged as a cheap and convenient alternative to traditional human annotation methods, enabling the automatic generation of training data by aligning text with external resources. Despite the many efforts in noise measurement methods, few works focus on the latent noise distribution between different distant annotation methods. In this work, we explore the effectiveness and robustness of DS-NER by two aspects: (1) distant annotation techniques, which encompasses both traditional rule-based methods and the innovative large language model supervision approach, and (2) noise assessment, for which we introduce a novel framework. This framework addresses the challenges by distinctly categorizing them into the unlabeled-entity problem (UEP) and the noisy-entity problem (NEP), subsequently providing specialized solutions for each. Our proposed method achieves significant improvements on eight real-world distant supervision datasets originating from three different data sources and involving four distinct annotation techniques, confirming its superiority over current state-of-the-art methods.
A Survey of Slow Thinking-based Reasoning LLMs using Reinforced Learning and Inference-time Scaling Law
May 05, 2025



This survey explores recent advancements in reasoning large language models (LLMs) designed to mimic "slow thinking" - a reasoning process inspired by human cognition, as described in Kahneman's Thinking, Fast and Slow. These models, like OpenAI's o1, focus on scaling computational resources dynamically during complex tasks, such as math reasoning, visual reasoning, medical diagnosis, and multi-agent debates. We present the development of reasoning LLMs and list their key technologies. By synthesizing over 100 studies, it charts a path toward LLMs that combine human-like deep thinking with scalable efficiency for reasoning. The review breaks down methods into three categories: (1) test-time scaling dynamically adjusts computation based on task complexity via search and sampling, dynamic verification; (2) reinforced learning refines decision-making through iterative improvement leveraging policy networks, reward models, and self-evolution strategies; and (3) slow-thinking frameworks (e.g., long CoT, hierarchical processes) that structure problem-solving with manageable steps. The survey highlights the challenges and further directions of this domain. Understanding and advancing the reasoning abilities of LLMs is crucial for unlocking their full potential in real-world applications, from scientific discovery to decision support systems.
Unleashing Reasoning Capability of LLMs via Scalable Question Synthesis from Scratch
Oct 24, 2024



The availability of high-quality data is one of the most important factors in improving the reasoning capability of LLMs. Existing works have demonstrated the effectiveness of creating more instruction data from seed questions or knowledge bases. Recent research indicates that continually scaling up data synthesis from strong models (e.g., GPT-4) can further elicit reasoning performance. Though promising, the open-sourced community still lacks high-quality data at scale and scalable data synthesis methods with affordable costs. To address this, we introduce ScaleQuest, a scalable and novel data synthesis method that utilizes "small-size" (e.g., 7B) open-source models to generate questions from scratch without the need for seed data with complex augmentation constraints. With the efficient ScaleQuest, we automatically constructed a mathematical reasoning dataset consisting of 1 million problem-solution pairs, which are more effective than existing open-sourced datasets. It can universally increase the performance of mainstream open-source models (i.e., Mistral, Llama3, DeepSeekMath, and Qwen2-Math) by achieving 29.2% to 46.4% gains on MATH. Notably, simply fine-tuning the Qwen2-Math-7B-Base model with our dataset can even surpass Qwen2-Math-7B-Instruct, a strong and well-aligned model on closed-source data, and proprietary models such as GPT-4-Turbo and Claude-3.5 Sonnet.
Boosting Large Language Models with Socratic Method for Conversational Mathematics Teaching
Jul 24, 2024



With the introduction of large language models (LLMs), automatic math reasoning has seen tremendous success. However, current methods primarily focus on providing solutions or using techniques like Chain-of-Thought to enhance problem-solving accuracy. In this paper, we focus on improving the capability of mathematics teaching via a Socratic teaching-based LLM (\texttt{SocraticLLM}), which guides learners toward profound thinking with clarity and self-discovery via conversation. We collect and release a high-quality mathematical teaching dataset, named \texttt{SocraticMATH}, which provides Socratic-style conversations of problems with extra knowledge. Also, we propose a knowledge-enhanced LLM as a strong baseline to generate reliable responses with review, guidance/heuristic, rectification, and summarization. Experimental results show the great advantages of \texttt{SocraticLLM} by comparing it with several strong generative models. The codes and datasets are available on \url{https://github.com/ECNU-ICALK/SocraticMath}.
OpenBA-V2: Reaching 77.3% High Compression Ratio with Fast Multi-Stage Pruning
May 09, 2024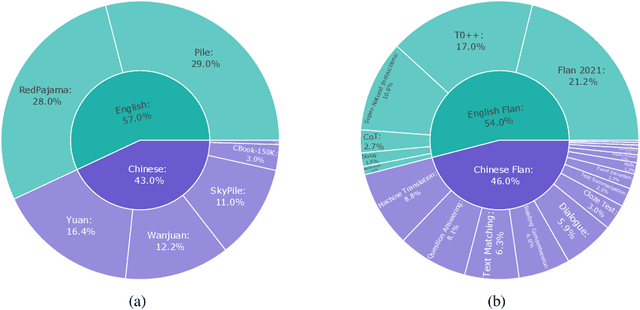

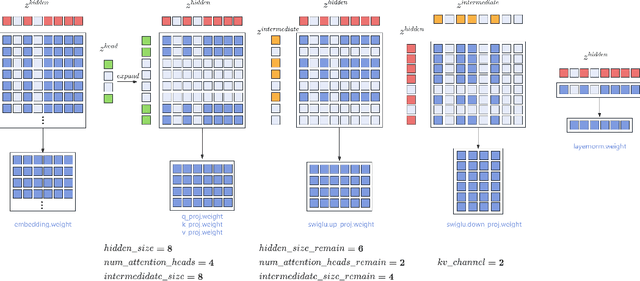
Large Language Models (LLMs) have played an important role in many fields due to their powerful capabilities.However, their massive number of parameters leads to high deployment requirements and incurs significant inference costs, which impedes their practical applications. Training smaller models is an effective way to address this problem. Therefore, we introduce OpenBA-V2, a 3.4B model derived from multi-stage compression and continual pre-training from the original 15B OpenBA model. OpenBA-V2 utilizes more data, more flexible training objectives, and techniques such as layer pruning, neural pruning, and vocabulary pruning to achieve a compression rate of 77.3\% with minimal performance loss. OpenBA-V2 demonstrates competitive performance compared to other open-source models of similar size, achieving results close to or on par with the 15B OpenBA model in downstream tasks such as common sense reasoning and Named Entity Recognition (NER). OpenBA-V2 illustrates that LLMs can be compressed into smaller ones with minimal performance loss by employing advanced training objectives and data strategies, which may help deploy LLMs in resource-limited scenarios.
Rethinking Negative Instances for Generative Named Entity Recognition
Feb 26, 2024



Large Language Models (LLMs) have demonstrated impressive capabilities for generalizing in unseen tasks. In the Named Entity Recognition (NER) task, recent advancements have seen the remarkable improvement of LLMs in a broad range of entity domains via instruction tuning, by adopting entity-centric schema. In this work, we explore the potential enhancement of the existing methods by incorporating negative instances into training. Our experiments reveal that negative instances contribute to remarkable improvements by (1) introducing contextual information, and (2) clearly delineating label boundaries. Furthermore, we introduce a novel and efficient algorithm named Hierarchical Matching, which is tailored to transform unstructured predictions into structured entities. By integrating these components, we present GNER, a Generative NER system that shows improved zero-shot performance across unseen entity domains. Our comprehensive evaluation illustrates our system's superiority, surpassing state-of-the-art (SoTA) methods by 11 $F_1$ score in zero-shot evaluation.
Mathematical Language Models: A Survey
Dec 14, 2023



In recent years, there has been remarkable progress in leveraging Language Models (LMs), encompassing Pre-trained Language Models (PLMs) and Large-scale Language Models (LLMs), within the domain of mathematics. This paper conducts a comprehensive survey of mathematical LMs, systematically categorizing pivotal research endeavors from two distinct perspectives: tasks and methodologies. The landscape reveals a large number of proposed mathematical LLMs, which are further delineated into instruction learning, tool-based methods, fundamental CoT techniques, and advanced CoT methodologies. In addition, our survey entails the compilation of over 60 mathematical datasets, including training datasets, benchmark datasets, and augmented datasets. Addressing the primary challenges and delineating future trajectories within the field of mathematical LMs, this survey is positioned as a valuable resource, poised to facilitate and inspire future innovation among researchers invested in advancing this domain.
OpenBA: An Open-sourced 15B Bilingual Asymmetric seq2seq Model Pre-trained from Scratch
Oct 01, 2023



Large language models (LLMs) with billions of parameters have demonstrated outstanding performance on various natural language processing tasks. This report presents OpenBA, an open-sourced 15B bilingual asymmetric seq2seq model, to contribute an LLM variant to the Chinese-oriented open-source model community. We enhance OpenBA with effective and efficient techniques as well as adopt a three-stage training strategy to train the model from scratch. Our solution can also achieve very competitive performance with only 380B tokens, which is better than LLaMA-70B on the BELEBELE benchmark, BLOOM-176B on the MMLU benchmark, GLM-130B on the C-Eval (hard) benchmark. This report provides the main details to pre-train an analogous model, including pre-training data processing, Bilingual Flan data collection, the empirical observations that inspire our model architecture design, training objectives of different stages, and other enhancement techniques. Additionally, we also provide the fine-tuning details of OpenBA on four downstream tasks. We have refactored our code to follow the design principles of the Huggingface Transformers Library, making it more convenient for developers to use, and released checkpoints of different training stages at https://huggingface.co/openBA. More details of our project are available at https://github.com/OpenNLG/openBA.git.
Detoxify Language Model Step-by-Step
Aug 16, 2023



Detoxification for LLMs is challenging since it requires models to avoid generating harmful content while maintaining the generation capability. To ensure the safety of generations, previous detoxification methods detoxify the models by changing the data distributions or constraining the generations from different aspects in a single-step manner. However, these approaches will dramatically affect the generation quality of LLMs, e.g., discourse coherence and semantic consistency, since language models tend to generate along the toxic prompt while detoxification methods work in the opposite direction. To handle such a conflict, we decompose the detoxification process into different sub-steps, where the detoxification is concentrated in the input stage and the subsequent continual generation is based on the non-toxic prompt. Besides, we also calibrate the strong reasoning ability of LLMs by designing a Detox-Chain to connect the above sub-steps in an orderly manner, which allows LLMs to detoxify the text step-by-step. Automatic and human evaluation on two benchmarks reveals that by training with Detox-Chain, six LLMs scaling from 1B to 33B can obtain significant detoxification and generation improvement. Our code and data are available at https://github.com/CODINNLG/Detox-CoT. Warning: examples in the paper may contain uncensored offensive content.