 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElastic Attention: Test-time Adaptive Sparsity Ratios for Efficient Transformers
Jan 24, 2026The quadratic complexity of standard attention mechanisms poses a significant scalability bottleneck for large language models (LLMs) in long-context scenarios. While hybrid attention strategies that combine sparse and full attention within a single model offer a viable solution, they typically employ static computation ratios (i.e., fixed proportions of sparse versus full attention) and fail to adapt to the varying sparsity sensitivities of downstream tasks during inference. To address this issue, we propose Elastic Attention, which allows the model to dynamically adjust its overall sparsity based on the input. This is achieved by integrating a lightweight Attention Router into the existing pretrained model, which dynamically assigns each attention head to different computation modes. Within only 12 hours of training on 8xA800 GPUs, our method enables models to achieve both strong performance and efficient inference. Experiments across three long-context benchmarks on widely-used LLMs demonstrate the superiority of our method.
MemoryRewardBench: Benchmarking Reward Models for Long-Term Memory Management in Large Language Models
Jan 24, 2026Existing works increasingly adopt memory-centric mechanisms to process long contexts in a segment manner, and effective memory management is one of the key capabilities that enables large language models to effectively propagate information across the entire sequence. Therefore, leveraging reward models (RMs) to automatically and reliably evaluate memory quality is critical. In this work, we introduce MemoryRewardBench, the first benchmark to systematically study the ability of RMs to evaluate long-term memory management processes. MemoryRewardBench covers both long-context comprehension and long-form generation tasks, featuring 10 distinct settings with different memory management patterns, with context length ranging from 8K to 128K tokens. Evaluations on 13 cutting-edge RMs indicate a diminishing performance gap between open-source and proprietary models, with newer-generation models consistently outperforming their predecessors regardless of parameter count. We further expose the capabilities and fundamental limitations of current RMs in evaluating LLM memory management across diverse settings.
$\texttt{MemoryRewardBench}$: Benchmarking Reward Models for Long-Term Memory Management in Large Language Models
Jan 17, 2026Existing works increasingly adopt memory-centric mechanisms to process long contexts in a segment manner, and effective memory management is one of the key capabilities that enables large language models to effectively propagate information across the entire sequence. Therefore, leveraging reward models (RMs) to automatically and reliably evaluate memory quality is critical. In this work, we introduce $\texttt{MemoryRewardBench}$, the first benchmark to systematically study the ability of RMs to evaluate long-term memory management processes. $\texttt{MemoryRewardBench}$ covers both long-context comprehension and long-form generation tasks, featuring 10 distinct settings with different memory management patterns, with context length ranging from 8K to 128K tokens. Evaluations on 13 cutting-edge RMs indicate a diminishing performance gap between open-source and proprietary models, with newer-generation models consistently outperforming their predecessors regardless of parameter count. We further expose the capabilities and fundamental limitations of current RMs in evaluating LLM memory management across diverse settings.
TalkPhoto: A Versatile Training-Free Conversational Assistant for Intelligent Image Editing
Jan 05, 2026Thanks to the powerful language comprehension capabilities of Large Language Models (LLMs), existing instruction-based image editing methods have introduced Multimodal Large Language Models (MLLMs) to promote information exchange between instructions and images, ensuring the controllability and flexibility of image editing. However, these frameworks often build a multi-instruction dataset to train the model to handle multiple editing tasks, which is not only time-consuming and labor-intensive but also fails to achieve satisfactory results. In this paper, we present TalkPhoto, a versatile training-free image editing framework that facilitates precise image manipulation through conversational interaction. We instruct the open-source LLM with a specially designed prompt template to analyze user needs after receiving instructions and hierarchically invoke existing advanced editing methods, all without additional training. Moreover, we implement a plug-and-play and efficient invocation of image editing methods, allowing complex and unseen editing tasks to be integrated into the current framework, achieving stable and high-quality editing results. Extensive experiments demonstrate that our method not only provides more accurate invocation with fewer token consumption but also achieves higher editing quality across various image editing tasks.
Qwen-Image-Layered: Towards Inherent Editability via Layer Decomposition
Dec 17, 2025Recent visual generative models often struggle with consistency during image editing due to the entangled nature of raster images, where all visual content is fused into a single canvas. In contrast, professional design tools employ layered representations, allowing isolated edits while preserving consistency. Motivated by this, we propose \textbf{Qwen-Image-Layered}, an end-to-end diffusion model that decomposes a single RGB image into multiple semantically disentangled RGBA layers, enabling \textbf{inherent editability}, where each RGBA layer can be independently manipulated without affecting other content. To support variable-length decomposition, we introduce three key components: (1) an RGBA-VAE to unify the latent representations of RGB and RGBA images; (2) a VLD-MMDiT (Variable Layers Decomposition MMDiT) architecture capable of decomposing a variable number of image layers; and (3) a Multi-stage Training strategy to adapt a pretrained image generation model into a multilayer image decomposer. Furthermore, to address the scarcity of high-quality multilayer training images, we build a pipeline to extract and annotate multilayer images from Photoshop documents (PSD). Experiments demonstrate that our method significantly surpasses existing approaches in decomposition quality and establishes a new paradigm for consistent image editing. Our code and models are released on \href{https://github.com/QwenLM/Qwen-Image-Layered}{https://github.com/QwenLM/Qwen-Image-Layered}
LongRM: Revealing and Unlocking the Context Boundary of Reward Modeling
Oct 08, 2025Reward model (RM) plays a pivotal role in aligning large language model (LLM) with human preferences. As real-world applications increasingly involve long history trajectories, e.g., LLM agent, it becomes indispensable to evaluate whether a model's responses are not only high-quality but also grounded in and consistent with the provided context. Yet, current RMs remain confined to short-context settings and primarily focus on response-level attributes (e.g., safety or helpfulness), while largely neglecting the critical dimension of long context-response consistency. In this work, we introduce Long-RewardBench, a benchmark specifically designed for long-context RM evaluation, featuring both Pairwise Comparison and Best-of-N tasks. Our preliminary study reveals that even state-of-the-art generative RMs exhibit significant fragility in long-context scenarios, failing to maintain context-aware preference judgments. Motivated by the analysis of failure patterns observed in model outputs, we propose a general multi-stage training strategy that effectively scales arbitrary models into robust Long-context RMs (LongRMs). Experiments show that our approach not only substantially improves performance on long-context evaluation but also preserves strong short-context capability. Notably, our 8B LongRM outperforms much larger 70B-scale baselines and matches the performance of the proprietary Gemini 2.5 Pro model.
Revealing and Mitigating Over-Attention in Knowledge Editing
Feb 20, 2025Large Language Models have demonstrated superior performance across a wide range of tasks, but they still exhibit undesirable errors due to incorrect knowledge learned from the training data. To avoid this, knowledge editing methods emerged to precisely edit the specific model knowledge via efficiently modifying a very small percentage of parameters. % However, those methods can lead to the problem of Specificity Failure: when the content related to the edited knowledge occurs in the context, it can inadvertently corrupt other pre-existing knowledge. However, those methods can lead to the problem of Specificity Failure, where the existing knowledge and capabilities are severely degraded due to editing. Our preliminary indicates that Specificity Failure primarily stems from the model's attention heads assigning excessive attention scores to entities related to the edited knowledge, thereby unduly focusing on specific snippets within the context, which we denote as the Attention Drift phenomenon. To mitigate such Attention Drift issue, we introduce a simple yet effective method Selective Attention Drift Restriction}(SADR), which introduces an additional regularization term during the knowledge editing process to restrict changes in the attention weight distribution, thereby preventing undue focus on the edited entity. Experiments on five frequently used strong LLMs demonstrate the effectiveness of our method, where SADR can significantly mitigate Specificity Failure in the predominant knowledge editing tasks.
OmniGuard: Hybrid Manipulation Localization via Augmented Versatile Deep Image Watermarking
Dec 02, 2024



With the rapid growth of generative AI and its widespread application in image editing, new risks have emerged regarding the authenticity and integrity of digital content. Existing versatile watermarking approaches suffer from trade-offs between tamper localization precision and visual quality. Constrained by the limited flexibility of previous framework, their localized watermark must remain fixed across all images. Under AIGC-editing, their copyright extraction accuracy is also unsatisfactory. To address these challenges, we propose OmniGuard, a novel augmented versatile watermarking approach that integrates proactive embedding with passive, blind extraction for robust copyright protection and tamper localization. OmniGuard employs a hybrid forensic framework that enables flexible localization watermark selection and introduces a degradation-aware tamper extraction network for precise localization under challenging conditions. Additionally, a lightweight AIGC-editing simulation layer is designed to enhance robustness across global and local editing. Extensive experiments show that OmniGuard achieves superior fidelity, robustness, and flexibility. Compared to the recent state-of-the-art approach EditGuard, our method outperforms it by 4.25dB in PSNR of the container image, 20.7% in F1-Score under noisy conditions, and 14.8% in average bit accuracy.
LOGO -- Long cOntext aliGnment via efficient preference Optimization
Oct 24, 2024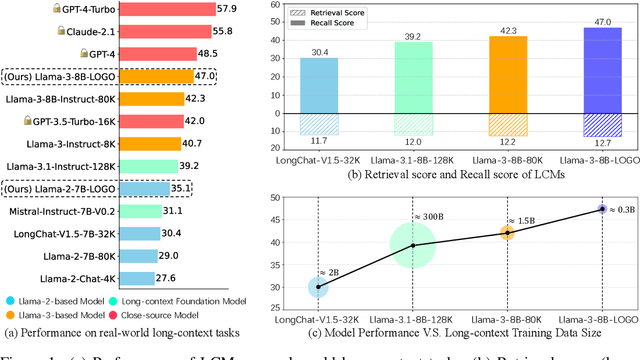
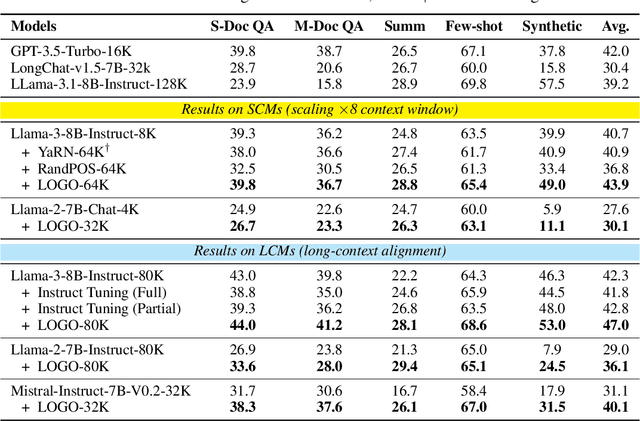
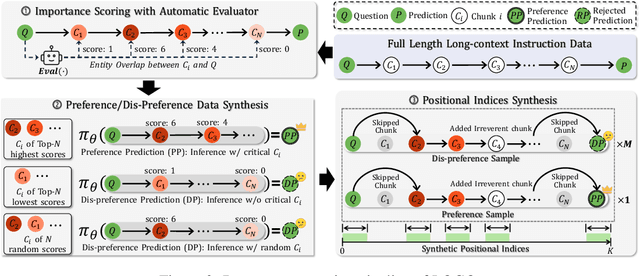
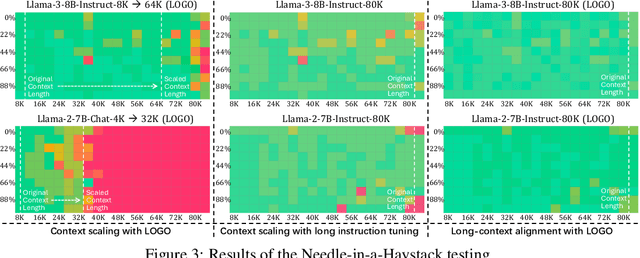
Long-context models(LCMs) have shown great potential in processing long input sequences(even more than 100M tokens) conveniently and effectively. With significant progress, recent research has pointed out that LCMs can accurately locate token-level salient information within the context. Yet, the generation performance of these LCMs is far from satisfactory and might result in misaligned responses, such as hallucinations. To enhance the generation capability of LCMs, existing works have investigated the effects of data size and quality for both pre-training and instruction tuning. Though achieving meaningful improvement, previous methods fall short in either effectiveness or efficiency. In this paper, we introduce LOGO(Long cOntext aliGnment via efficient preference Optimization), a training strategy that first introduces preference optimization for long-context alignment. To overcome the GPU memory-bound issue caused by the long sequence, LOGO employs a reference-free preference optimization strategy and adopts a position synthesis method to construct the training data. By training with only 0.3B data on a single 8$\times$A800 GPU machine for 16 hours, LOGO allows the Llama-3-8B-Instruct-80K model to achieve comparable performance with GPT-4 in real-world long-context tasks while preserving the model's original capabilities on other tasks, e.g., language modeling and MMLU. Moreover, LOGO can extend the model's context window size while enhancing its generation performance.
Revealing and Mitigating the Local Pattern Shortcuts of Mamba
Oct 21, 2024Large language models (LLMs) have advanced significantly due to the attention mechanism, but their quadratic complexity and linear memory demands limit their performance on long-context tasks. Recently, researchers introduced Mamba, an advanced model built upon State Space Models(SSMs) that offers linear complexity and constant memory. Although Mamba is reported to match or surpass the performance of attention-based models, our analysis reveals a performance gap: Mamba excels in tasks that involve localized key information but faces challenges with tasks that require handling distributed key information. Our controlled experiments suggest that this inconsistency arises from Mamba's reliance on local pattern shortcuts, which enable the model to remember local key information within its limited memory but hinder its ability to retain more dispersed information. Therefore, we introduce a global selection module into the Mamba model to address this issue. Experiments on both existing and proposed synthetic tasks, as well as real-world tasks, demonstrate the effectiveness of our method. Notably, with the introduction of only 4M extra parameters, our approach enables the Mamba model(130M) to achieve a significant improvement on tasks with distributed information, increasing its performance from 0 to 80.54 points.