 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing and Mitigating the Local Pattern Shortcuts of Mamba
Oct 21, 2024


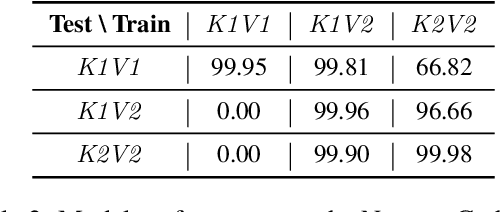
Large language models (LLMs) have advanced significantly due to the attention mechanism, but their quadratic complexity and linear memory demands limit their performance on long-context tasks. Recently, researchers introduced Mamba, an advanced model built upon State Space Models(SSMs) that offers linear complexity and constant memory. Although Mamba is reported to match or surpass the performance of attention-based models, our analysis reveals a performance gap: Mamba excels in tasks that involve localized key information but faces challenges with tasks that require handling distributed key information. Our controlled experiments suggest that this inconsistency arises from Mamba's reliance on local pattern shortcuts, which enable the model to remember local key information within its limited memory but hinder its ability to retain more dispersed information. Therefore, we introduce a global selection module into the Mamba model to address this issue. Experiments on both existing and proposed synthetic tasks, as well as real-world tasks, demonstrate the effectiveness of our method. Notably, with the introduction of only 4M extra parameters, our approach enables the Mamba model(130M) to achieve a significant improvement on tasks with distributed information, increasing its performance from 0 to 80.54 points.
Plan-And-Write: Towards Better Automatic Storytelling
Nov 20, 2018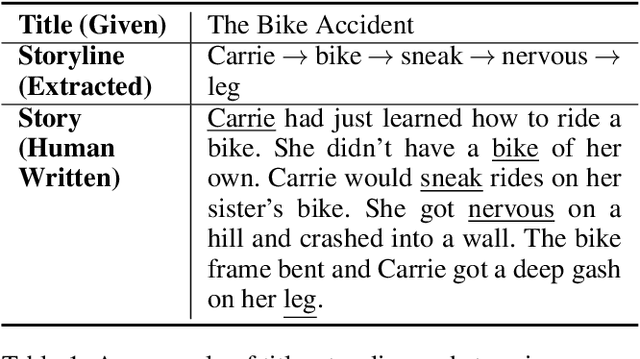
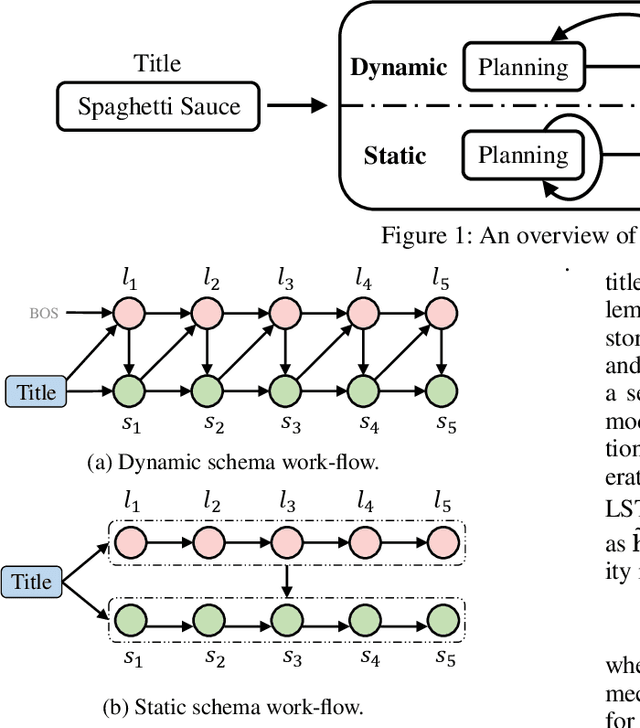

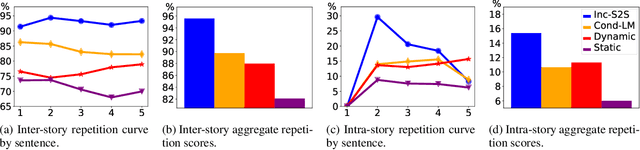
Automatic storytelling is challenging since it requires generating long, coherent natural language to describes a sensible sequence of events. Despite considerable efforts on automatic story generation in the past, prior work either is restricted in plot planning, or can only generate stories in a narrow domain. In this paper, we explore open-domain story generation that writes stories given a title (topic) as input. We propose a plan-and-write hierarchical generation framework that first plans a storyline, and then generates a story based on the storyline. We compare two planning strategies. The dynamic schema interweaves story planning and its surface realization in text, while the static schema plans out the entire storyline before generating stories. Experiments show that with explicit storyline planning, the generated stories are more diverse, coherent, and on topic than those generated without creating a full plan, according to both automatic and human evaluations.
Chat More If You Like: Dynamic Cue Words Planning to Flow Longer Conversations
Nov 19, 2018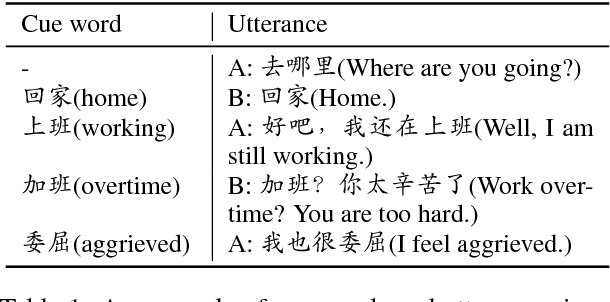
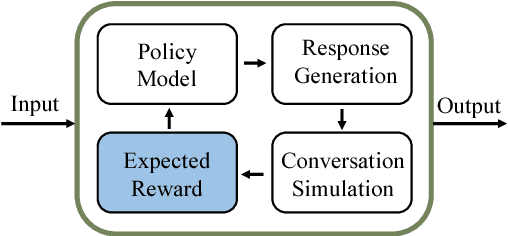
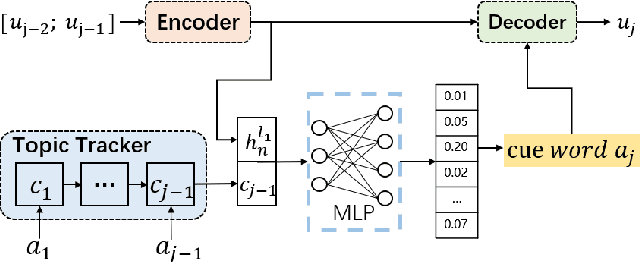

To build an open-domain multi-turn conversation system is one of the most interesting and challenging tasks in Artificial Intelligence. Many research efforts have been dedicated to building such dialogue systems, yet few shed light on modeling the conversation flow in an ongoing dialogue. Besides, it is common for people to talk about highly relevant aspects during a conversation. And the topics are coherent and drift naturally, which demonstrates the necessity of dialogue flow modeling. To this end, we present the multi-turn cue-words driven conversation system with reinforcement learning method (RLCw), which strives to select an adaptive cue word with the greatest future credit, and therefore improve the quality of generated responses. We introduce a new reward to measure the quality of cue words in terms of effectiveness and relevance. To further optimize the model for long-term conversations, a reinforcement approach is adopted in this paper. Experiments on real-life dataset demonstrate that our model consistently outperforms a set of competitive baselines in terms of simulated turns, diversity and human evaluation.