 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevelopment and Validation of a Machine Learning Algorithm for Clinical Wellness Visit Classification in Cats and Dogs
Jun 14, 2024Early disease detection in veterinary care relies on identifying subclinical abnormalities in asymptomatic animals during wellness visits. This study introduces an algorithm designed to distinguish between wellness and other veterinary visits.The purpose of this study is to validate the use of a visit classification algorithm compared to manual classification of veterinary visits by three board-certified veterinarians. Using a dataset of 11,105 clinical visits from 2012 to 2017 involving 655 animals (85.3% canines and 14.7% felines) across 544 U.S. veterinary establishments, the model was trained using a Gradient Boosting Machine model. Three validators were tasked with classifying 400 visits, including both wellness and other types of visits, selected randomly from the same database used for initial algorithm training, aiming to maintain consistency and relevance between the training and application phases; visit classifications were subsequently categorized into "wellness" or "other" based on majority consensus among validators to assess the algorithm's performance in identifying wellness visits. The algorithm demonstrated a specificity of 0.94 (95% CI: 0.91 to 0.96), implying its accuracy in distinguishing non-wellness visits. The algorithm had a sensitivity of 0.86 (95% CI: 0.80 to 0.92), indicating its ability to correctly identify wellness visits as compared to the annotations provided by veterinary experts. The balanced accuracy, calculated as 0.90 (95% CI: 0.87 to 0.93), further confirms the algorithm's overall effectiveness. The algorithm exhibits strong specificity and sensitivity, ensuring accurate identification of a high proportion of wellness visits. Overall, this algorithm holds promise for advancing research on preventive care's role in subclinical disease identification, but prospective studies are needed for validation.
Two Approaches to Building Collaborative, Task-Oriented Dialog Agents through Self-Play
Sep 20, 2021
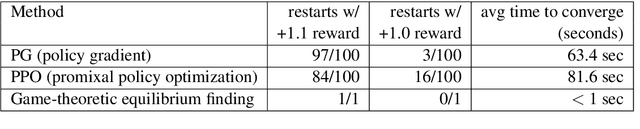
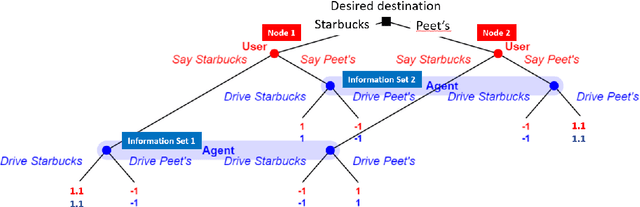
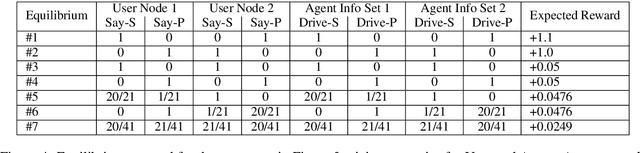
Task-oriented dialog systems are often trained on human/human dialogs, such as collected from Wizard-of-Oz interfaces. However, human/human corpora are frequently too small for supervised training to be effective. This paper investigates two approaches to training agent-bots and user-bots through self-play, in which they autonomously explore an API environment, discovering communication strategies that enable them to solve the task. We give empirical results for both reinforcement learning and game-theoretic equilibrium finding.
MeetDot: Videoconferencing with Live Translation Captions
Sep 20, 2021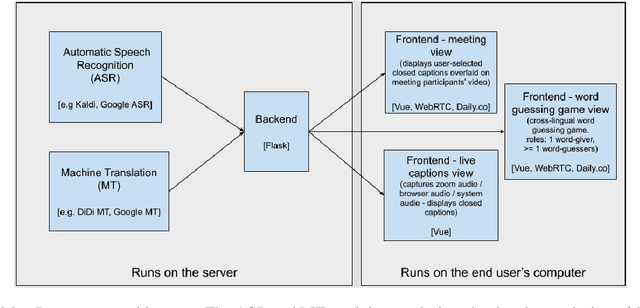

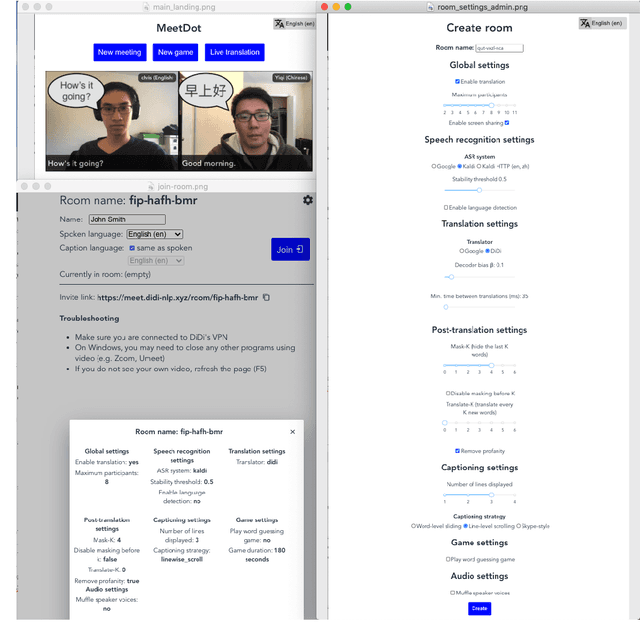
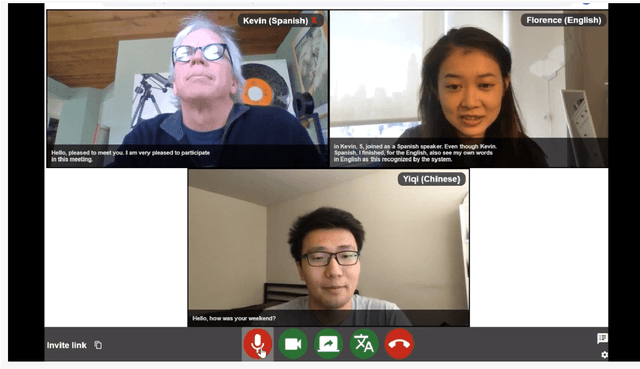
We present MeetDot, a videoconferencing system with live translation captions overlaid on screen. The system aims to facilitate conversation between people who speak different languages, thereby reducing communication barriers between multilingual participants. Currently, our system supports speech and captions in 4 languages and combines automatic speech recognition (ASR) and machine translation (MT) in a cascade. We use the re-translation strategy to translate the streamed speech, resulting in caption flicker. Additionally, our system has very strict latency requirements to have acceptable call quality. We implement several features to enhance user experience and reduce their cognitive load, such as smooth scrolling captions and reducing caption flicker. The modular architecture allows us to integrate different ASR and MT services in our backend. Our system provides an integrated evaluation suite to optimize key intrinsic evaluation metrics such as accuracy, latency and erasure. Finally, we present an innovative cross-lingual word-guessing game as an extrinsic evaluation metric to measure end-to-end system performance. We plan to make our system open-source for research purposes.
Learning Mathematical Properties of Integers
Sep 15, 2021
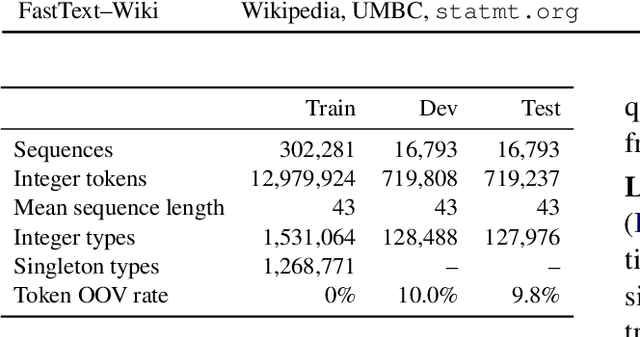
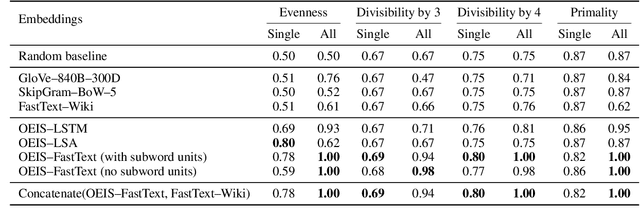
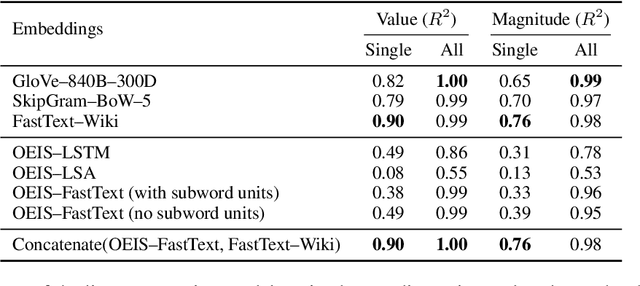
Embedding words in high-dimensional vector spaces has proven valuable in many natural language applications. In this work, we investigate whether similarly-trained embeddings of integers can capture concepts that are useful for mathematical applications. We probe the integer embeddings for mathematical knowledge, apply them to a set of numerical reasoning tasks, and show that by learning the representations from mathematical sequence data, we can substantially improve over number embeddings learned from English text corpora.
A Hybrid Task-Oriented Dialog System with Domain and Task Adaptive Pretraining
Feb 08, 2021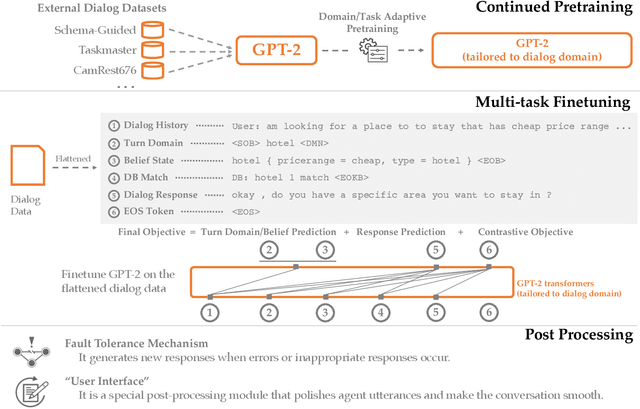
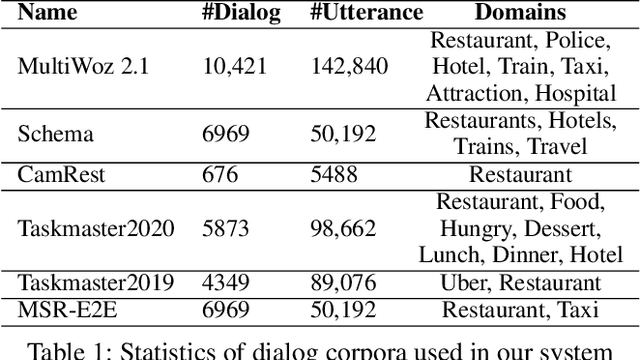

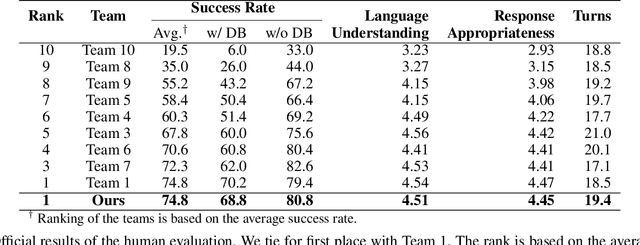
This paper describes our submission for the End-to-end Multi-domain Task Completion Dialog shared task at the 9th Dialog System Technology Challenge (DSTC-9). Participants in the shared task build an end-to-end task completion dialog system which is evaluated by human evaluation and a user simulator based automatic evaluation. Different from traditional pipelined approaches where modules are optimized individually and suffer from cascading failure, we propose an end-to-end dialog system that 1) uses Generative Pretraining 2 (GPT-2) as the backbone to jointly solve Natural Language Understanding, Dialog State Tracking, and Natural Language Generation tasks, 2) adopts Domain and Task Adaptive Pretraining to tailor GPT-2 to the dialog domain before finetuning, 3) utilizes heuristic pre/post-processing rules that greatly simplify the prediction tasks and improve generalizability, and 4) equips a fault tolerance module to correct errors and inappropriate responses. Our proposed method significantly outperforms baselines and ties for first place in the official evaluation. We make our source code publicly available.
Why Neural Machine Translation Prefers Empty Outputs
Dec 24, 2020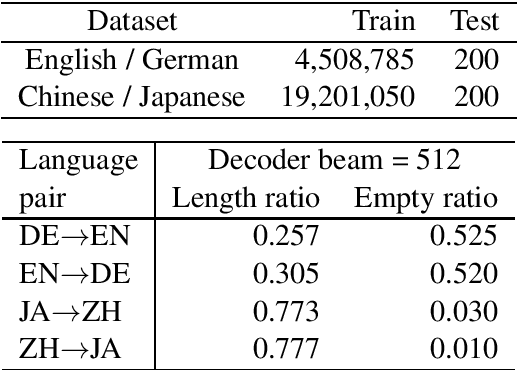
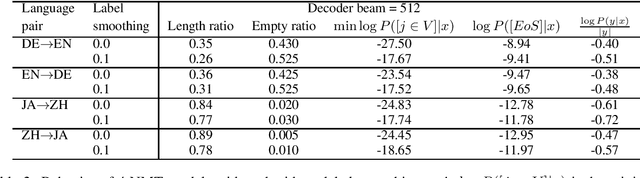
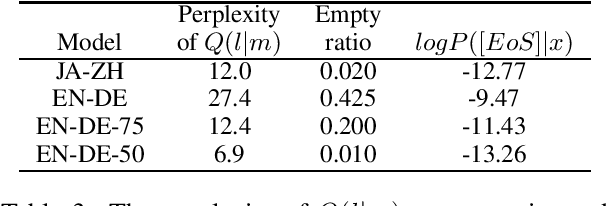
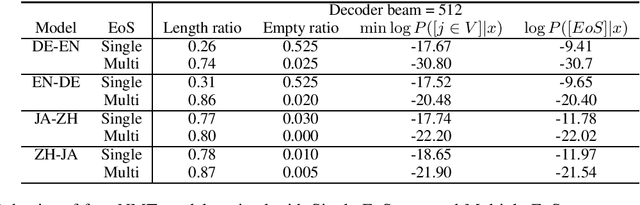
We investigate why neural machine translation (NMT) systems assign high probability to empty translations. We find two explanations. First, label smoothing makes correct-length translations less confident, making it easier for the empty translation to finally outscore them. Second, NMT systems use the same, high-frequency EoS word to end all target sentences, regardless of length. This creates an implicit smoothing that increases zero-length translations. Using different EoS types in target sentences of different lengths exposes and eliminates this implicit smoothing.
MUSE: Illustrating Textual Attributes by Portrait Generation
Nov 09, 2020
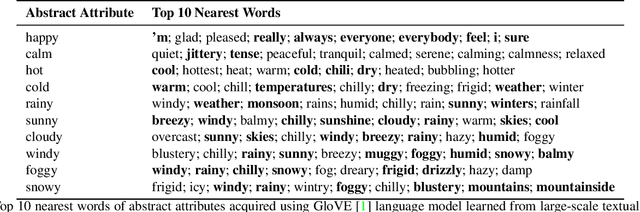

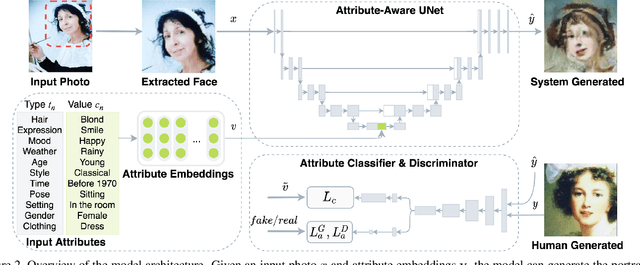
We propose a novel approach, MUSE, to illustrate textual attributes visually via portrait generation. MUSE takes a set of attributes written in text, in addition to facial features extracted from a photo of the subject as input. We propose 11 attribute types to represent inspirations from a subject's profile, emotion, story, and environment. We propose a novel stacked neural network architecture by extending an image-to-image generative model to accept textual attributes. Experiments show that our approach significantly outperforms several state-of-the-art methods without using textual attributes, with Inception Score score increased by 6% and Fr\'echet Inception Distance (FID) score decreased by 11%, respectively. We also propose a new attribute reconstruction metric to evaluate whether the generated portraits preserve the subject's attributes. Experiments show that our approach can accurately illustrate 78% textual attributes, which also help MUSE capture the subject in a more creative and expressive way.
DiDi's Machine Translation System for WMT2020
Oct 16, 2020
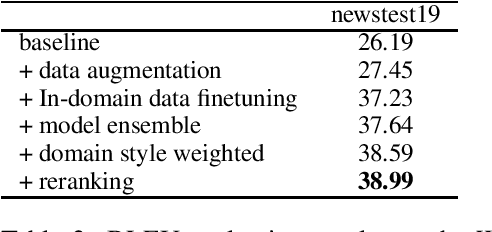
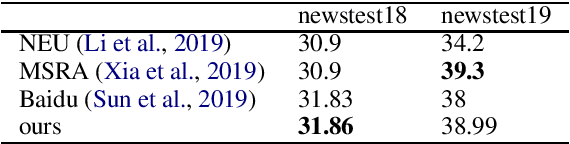
This paper describes DiDi AI Labs' submission to the WMT2020 news translation shared task. We participate in the translation direction of Chinese->English. In this direction, we use the Transformer as our baseline model, and integrate several techniques for model enhancement, including data filtering, data selection, back-translation, fine-tuning, model ensembling, and re-ranking. As a result, our submission achieves a BLEU score of $36.6$ in Chinese->English.
ReviewRobot: Explainable Paper Review Generation based on Knowledge Synthesis
Oct 13, 2020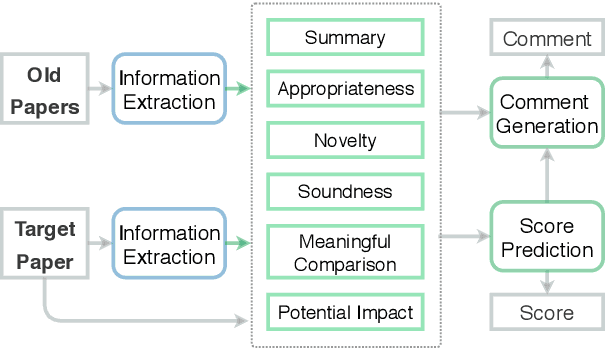
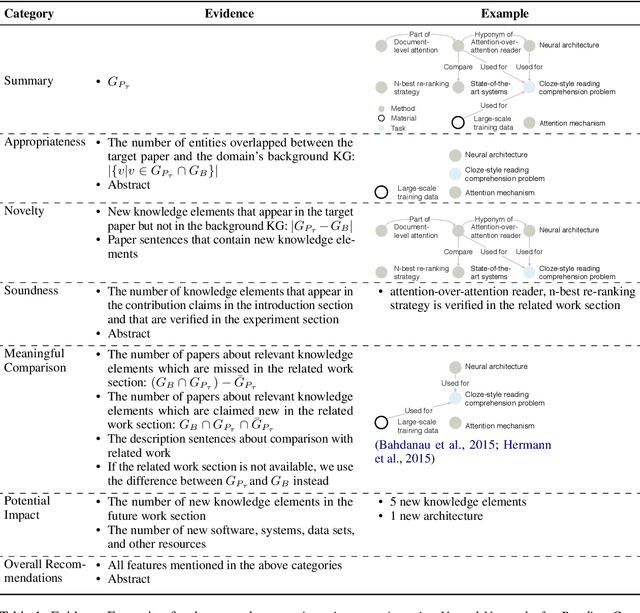
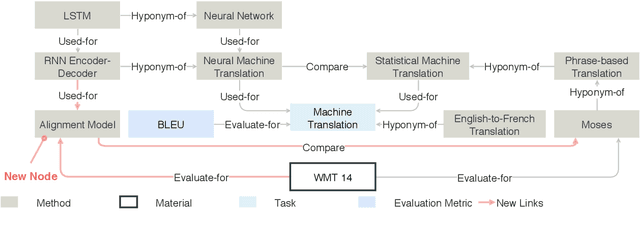

To assist human review process, we build a novel ReviewRobot to automatically assign a review score and write comments for multiple categories. A good review needs to be knowledgeable, namely that the comments should be constructive and informative to help improve the paper; and explainable by providing detailed evidence. ReviewRobot achieves these goals via three steps: (1) We perform domain-specific Information Extraction to construct a knowledge graph (KG) from the target paper under review, a related work KG from the papers cited by the target paper, and a background KG from a large collection of previous papers in the domain. (2) By comparing these three KGs we predict a review score and detailed structured knowledge as evidence for each review category. (3) We carefully select and generalize human review sentences into templates, and apply these templates to transform the review scores and evidence into natural language comments. Experimental results show that our review score predictor reaches 71.4-100% accuracy. Human assessment by domain experts shows that 41.7%-70.5% of the comments generated by ReviewRobot are valid and constructive, and better than human-written ones 20% of the time. Thus, ReviewRobot can serve as an assistant for paper reviewers, program chairs and authors.
MEEP: An Open-Source Platform for Human-Human Dialog Collection and End-to-End Agent Training
Oct 09, 2020
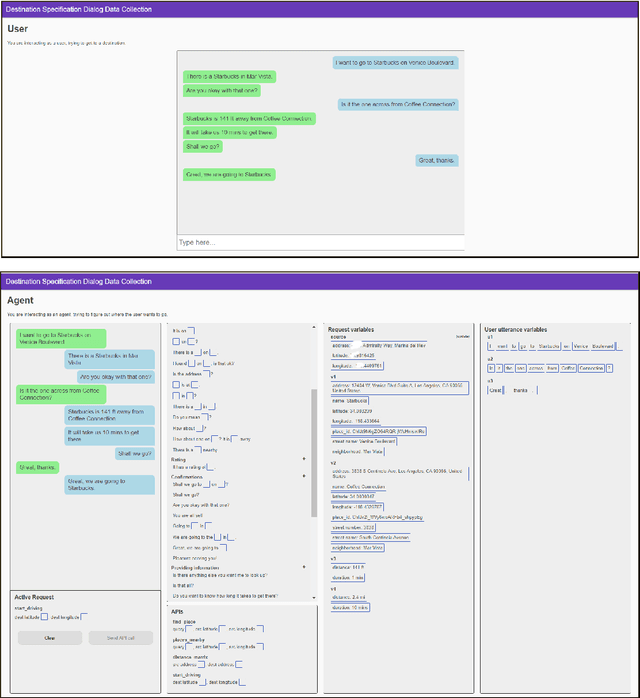


We create a new task-oriented dialog platform (MEEP) where agents are given considerable freedom in terms of utterances and API calls, but are constrained to work within a push-button environment. We include facilities for collecting human-human dialog corpora, and for training automatic agents in an end-to-end fashion. We demonstrate MEEP with a dialog assistant that lets users specify trip destinations.