 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSPO: Self-traced Step-wise Preference Optimization for Process Supervision and Reasoning Compression
Aug 18, 2025Test-time scaling has proven effective in further enhancing the performance of pretrained Large Language Models (LLMs). However, mainstream post-training methods (i.e., reinforcement learning (RL) with chain-of-thought (CoT) reasoning) often incur substantial computational overhead due to auxiliary models and overthinking. In this paper, we empirically reveal that the incorrect answers partially stem from verbose reasoning processes lacking correct self-fix, where errors accumulate across multiple reasoning steps. To this end, we propose Self-traced Step-wise Preference Optimization (SSPO), a pluggable RL process supervision framework that enables fine-grained optimization of each reasoning step. Specifically, SSPO requires neither auxiliary models nor stepwise manual annotations. Instead, it leverages step-wise preference signals generated by the model itself to guide the optimization process for reasoning compression. Experiments demonstrate that the generated reasoning sequences from SSPO are both accurate and succinct, effectively mitigating overthinking behaviors without compromising model performance across diverse domains and languages.
Large language models could be rote learners
Apr 15, 2025
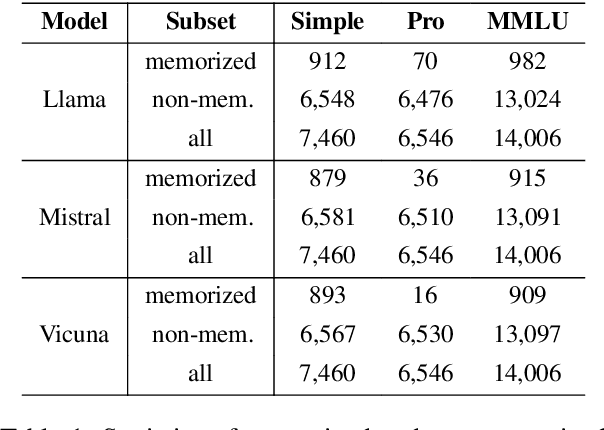
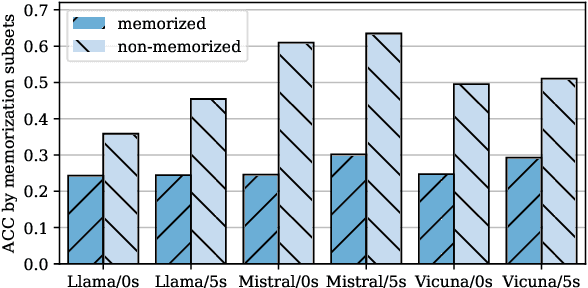

Multiple-choice question (MCQ) benchmarks are widely used for evaluating Large Language Models (LLMs), yet their reliability is undermined by benchmark contamination. In this study, we reframe contamination as an inherent aspect of learning and seek to disentangle genuine capability acquisition from superficial memorization in LLM evaluation. First, by analyzing model performance under different memorization conditions, we uncover a counterintuitive trend: LLMs perform worse on memorized MCQs than on non-memorized ones, indicating the coexistence of two distinct learning phenomena, i.e., rote memorization and genuine capability learning. To disentangle them, we propose TrinEval, a novel evaluation framework that reformulates MCQs into an alternative trinity format, reducing memorization while preserving knowledge assessment. Experiments validate TrinEval's effectiveness in reformulation, and its evaluation reveals that common LLMs may memorize by rote 20.5% of knowledge points (in MMLU on average).
Training an LLM-as-a-Judge Model: Pipeline, Insights, and Practical Lessons
Feb 05, 2025The rapid advancement of large language models (LLMs) has opened new possibilities for their adoption as evaluative judges. This paper introduces Themis, a fine-tuned LLM judge that delivers sophisticated context-aware evaluations. We provide a comprehensive overview of the development pipeline for Themis, highlighting its scenario-dependent evaluation prompts and two novel methods for controlled instruction generation. These designs enable Themis to effectively distill evaluative skills from teacher models, while retaining flexibility for continuous development. We introduce two human-labeled benchmarks for meta-evaluation, demonstrating that Themis can achieve high alignment with human preferences in an economical manner. Additionally, we explore insights into the LLM-as-a-judge paradigm, revealing nuances in performance and the varied effects of reference answers. Notably, we observe that pure knowledge distillation from strong LLMs, though common, does not guarantee performance improvement through scaling. We propose a mitigation strategy based on instruction-following difficulty. Furthermore, we provide practical guidelines covering data balancing, prompt customization, multi-objective training, and metric aggregation. We aim for our method and findings, along with the fine-tuning data, benchmarks, and model checkpoints, to support future research and development in this area.
Behavior Modeling Space Reconstruction for E-Commerce Search
Jan 30, 2025



Delivering superior search services is crucial for enhancing customer experience and driving revenue growth. Conventionally, search systems model user behaviors by combining user preference and query item relevance statically, often through a fixed logical 'and' relationship. This paper reexamines existing approaches through a unified lens using both causal graphs and Venn diagrams, uncovering two prevalent yet significant issues: entangled preference and relevance effects, and a collapsed modeling space. To surmount these challenges, our research introduces a novel framework, DRP, which enhances search accuracy through two components to reconstruct the behavior modeling space. Specifically, we implement preference editing to proactively remove the relevance effect from preference predictions, yielding untainted user preferences. Additionally, we employ adaptive fusion, which dynamically adjusts fusion criteria to align with the varying patterns of relevance and preference, facilitating more nuanced and tailored behavior predictions within the reconstructed modeling space. Empirical validation on two public datasets and a proprietary search dataset underscores the superiority of our proposed methodology, demonstrating marked improvements in performance over existing approaches.
PertEval: Unveiling Real Knowledge Capacity of LLMs with Knowledge-Invariant Perturbations
May 30, 2024
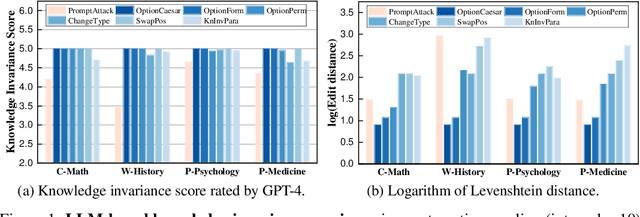

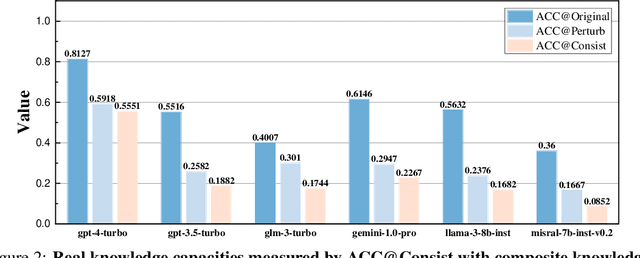
Expert-designed close-ended benchmarks serve as vital tools in assessing the knowledge capacity of large language models (LLMs). Despite their widespread use, concerns have mounted regarding their reliability due to limited test scenarios and an unavoidable risk of data contamination. To rectify this, we present PertEval, a toolkit devised for in-depth probing of LLMs' knowledge capacity through knowledge-invariant perturbations. These perturbations employ human-like restatement techniques to generate on-the-fly test samples from static benchmarks, meticulously retaining knowledge-critical content while altering irrelevant details. Our toolkit further includes a suite of transition analyses that compare performance on raw vs. perturbed test sets to precisely assess LLMs' genuine knowledge capacity. Six state-of-the-art LLMs are re-evaluated using PertEval. Results reveal significantly inflated performance of the LLMs on raw benchmarks, including an absolute 21% overestimation for GPT-4. Additionally, through a nuanced response pattern analysis, we discover that PertEval retains LLMs' uncertainty to specious knowledge, potentially being resolved through rote memorization and leading to inflated performance. We also find that the detailed transition analyses by PertEval could illuminate weaknesses in existing LLMs' knowledge mastery and guide the development of refinement. Given these insights, we posit that PertEval can act as an essential tool that, when applied alongside any close-ended benchmark, unveils the true knowledge capacity of LLMs, marking a significant step toward more trustworthy LLM evaluation.
EasyAnimate: A High-Performance Long Video Generation Method based on Transformer Architecture
May 29, 2024This paper presents EasyAnimate, an advanced method for video generation that leverages the power of transformer architecture for high-performance outcomes. We have expanded the DiT framework originally designed for 2D image synthesis to accommodate the complexities of 3D video generation by incorporating a motion module block. It is used to capture temporal dynamics, thereby ensuring the production of consistent frames and seamless motion transitions. The motion module can be adapted to various DiT baseline methods to generate video with different styles. It can also generate videos with different frame rates and resolutions during both training and inference phases, suitable for both images and videos. Moreover, we introduce slice VAE, a novel approach to condense the temporal axis, facilitating the generation of long duration videos. Currently, EasyAnimate exhibits the proficiency to generate videos with 144 frames. We provide a holistic ecosystem for video production based on DiT, encompassing aspects such as data pre-processing, VAE training, DiT models training (both the baseline model and LoRA model), and end-to-end video inference. Code is available at: https://github.com/aigc-apps/EasyAnimate. We are continuously working to enhance the performance of our method.
DiffPoint: Single and Multi-view Point Cloud Reconstruction with ViT Based Diffusion Model
Feb 17, 2024



As the task of 2D-to-3D reconstruction has gained significant attention in various real-world scenarios, it becomes crucial to be able to generate high-quality point clouds. Despite the recent success of deep learning models in generating point clouds, there are still challenges in producing high-fidelity results due to the disparities between images and point clouds. While vision transformers (ViT) and diffusion models have shown promise in various vision tasks, their benefits for reconstructing point clouds from images have not been demonstrated yet. In this paper, we first propose a neat and powerful architecture called DiffPoint that combines ViT and diffusion models for the task of point cloud reconstruction. At each diffusion step, we divide the noisy point clouds into irregular patches. Then, using a standard ViT backbone that treats all inputs as tokens (including time information, image embeddings, and noisy patches), we train our model to predict target points based on input images. We evaluate DiffPoint on both single-view and multi-view reconstruction tasks and achieve state-of-the-art results. Additionally, we introduce a unified and flexible feature fusion module for aggregating image features from single or multiple input images. Furthermore, our work demonstrates the feasibility of applying unified architectures across languages and images to improve 3D reconstruction tasks.
Arithmetic Feature Interaction Is Necessary for Deep Tabular Learning
Feb 04, 2024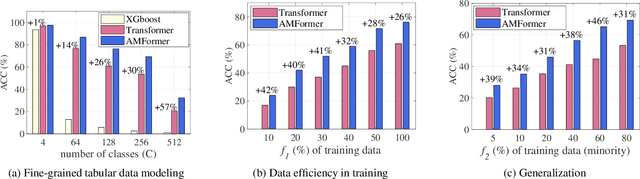

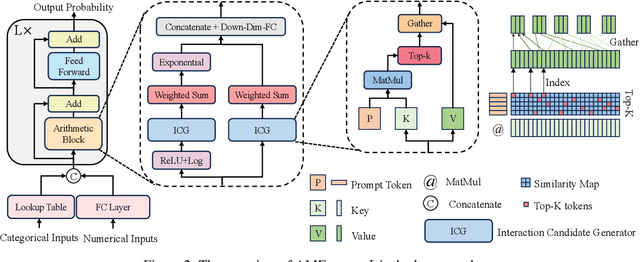

Until recently, the question of the effective inductive bias of deep models on tabular data has remained unanswered. This paper investigates the hypothesis that arithmetic feature interaction is necessary for deep tabular learning. To test this point, we create a synthetic tabular dataset with a mild feature interaction assumption and examine a modified transformer architecture enabling arithmetical feature interactions, referred to as AMFormer. Results show that AMFormer outperforms strong counterparts in fine-grained tabular data modeling, data efficiency in training, and generalization. This is attributed to its parallel additive and multiplicative attention operators and prompt-based optimization, which facilitate the separation of tabular samples in an extended space with arithmetically-engineered features. Our extensive experiments on real-world data also validate the consistent effectiveness, efficiency, and rationale of AMFormer, suggesting it has established a strong inductive bias for deep learning on tabular data. Code is available at https://github.com/aigc-apps/AMFormer.
EasyPhoto: Your Smart AI Photo Generator
Oct 07, 2023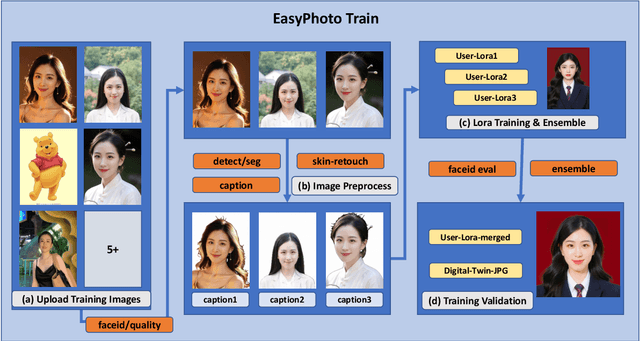
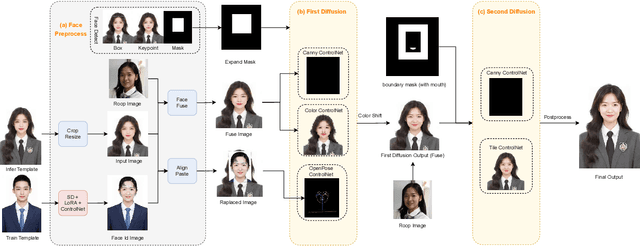
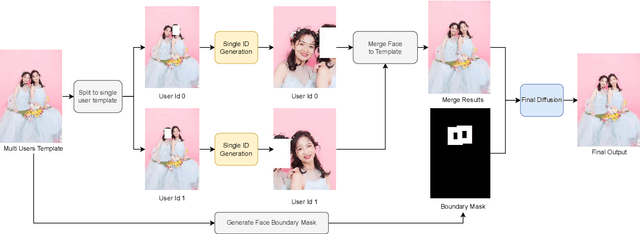

Stable Diffusion web UI (SD-WebUI) is a comprehensive project that provides a browser interface based on Gradio library for Stable Diffusion models. In this paper, We propose a novel WebUI plugin called EasyPhoto, which enables the generation of AI portraits. By training a digital doppelganger of a specific user ID using 5 to 20 relevant images, the finetuned model (according to the trained LoRA model) allows for the generation of AI photos using arbitrary templates. Our current implementation supports the modification of multiple persons and different photo styles. Furthermore, we allow users to generate fantastic template image with the strong SDXL model, enhancing EasyPhoto's capabilities to deliver more diverse and satisfactory results. The source code for EasyPhoto is available at: https://github.com/aigc-apps/sd-webui-EasyPhoto. We also support a webui-free version by using diffusers: https://github.com/aigc-apps/EasyPhoto. We are continuously enhancing our efforts to expand the EasyPhoto pipeline, making it suitable for any identification (not limited to just the face), and we enthusiastically welcome any intriguing ideas or suggestions.
MuLTI: Efficient Video-and-Language Understanding with MultiWay-Sampler and Multiple Choice Modeling
Mar 10, 2023



Video-and-language understanding has a variety of applications in the industry, such as video question answering, text-video retrieval and multi-label classification. Existing video-and-language understanding methods generally adopt heavy multi-modal encoders and feature fusion modules, which consume large amounts of GPU memory. Especially, they have difficulty dealing with dense video frames or long text that are prevalent in industrial applications. In this paper, we propose MuLTI, a highly accurate and memory-efficient video-and-language understanding model that achieves efficient and effective feature fusion through feature sampling and attention modules. Therefore, MuLTI can handle longer sequences with limited GPU memory. Then, we introduce an attention-based adapter to the encoders, which finetunes the shallow features to improve the model's performance with low GPU memory consumption. Finally, to further improve the model's performance, we introduce a new pretraining task named Multiple Choice Modeling to bridge the task gap between pretraining and downstream tasks and enhance the model's ability to align the video and the text. Benefiting from the efficient feature fusion module, the attention-based adapter and the new pretraining task, MuLTI achieves state-of-the-art performance on multiple datasets. Implementation and pretrained models will be released.