 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Agents to Communicate Entirely in Latent Space
Nov 12, 2025While natural language is the de facto communication medium for LLM-based agents, it presents a fundamental constraint. The process of downsampling rich, internal latent states into discrete tokens inherently limits the depth and nuance of information that can be transmitted, thereby hindering collaborative problem-solving. Inspired by human mind-reading, we propose Interlat (Inter-agent Latent Space Communication), a paradigm that leverages the last hidden states of an LLM as a representation of its mind for direct transmission (termed latent communication). An additional compression process further compresses latent communication via entirely latent space reasoning. Experiments demonstrate that Interlat outperforms both fine-tuned chain-of-thought (CoT) prompting and single-agent baselines, promoting more exploratory behavior and enabling genuine utilization of latent information. Further compression not only substantially accelerates inference but also maintains competitive performance through an efficient information-preserving mechanism. We position this work as a feasibility study of entirely latent space inter-agent communication, and our results highlight its potential, offering valuable insights for future research.
Versatile and Risk-Sensitive Cardiac Diagnosis via Graph-Based ECG Signal Representation
Nov 11, 2025Despite the rapid advancements of electrocardiogram (ECG) signal diagnosis and analysis methods through deep learning, two major hurdles still limit their clinical adoption: the lack of versatility in processing ECG signals with diverse configurations, and the inadequate detection of risk signals due to sample imbalances. Addressing these challenges, we introduce VersAtile and Risk-Sensitive cardiac diagnosis (VARS), an innovative approach that employs a graph-based representation to uniformly model heterogeneous ECG signals. VARS stands out by transforming ECG signals into versatile graph structures that capture critical diagnostic features, irrespective of signal diversity in the lead count, sampling frequency, and duration. This graph-centric formulation also enhances diagnostic sensitivity, enabling precise localization and identification of abnormal ECG patterns that often elude standard analysis methods. To facilitate representation transformation, our approach integrates denoising reconstruction with contrastive learning to preserve raw ECG information while highlighting pathognomonic patterns. We rigorously evaluate the efficacy of VARS on three distinct ECG datasets, encompassing a range of structural variations. The results demonstrate that VARS not only consistently surpasses existing state-of-the-art models across all these datasets but also exhibits substantial improvement in identifying risk signals. Additionally, VARS offers interpretability by pinpointing the exact waveforms that lead to specific model outputs, thereby assisting clinicians in making informed decisions. These findings suggest that our VARS will likely emerge as an invaluable tool for comprehensive cardiac health assessment.
AutoRing: Imitation Learning--based Autonomous Intraocular Foreign Body Removal Manipulation with Eye Surgical Robot
Aug 27, 2025Intraocular foreign body removal demands millimeter-level precision in confined intraocular spaces, yet existing robotic systems predominantly rely on manual teleoperation with steep learning curves. To address the challenges of autonomous manipulation (particularly kinematic uncertainties from variable motion scaling and variation of the Remote Center of Motion (RCM) point), we propose AutoRing, an imitation learning framework for autonomous intraocular foreign body ring manipulation. Our approach integrates dynamic RCM calibration to resolve coordinate-system inconsistencies caused by intraocular instrument variation and introduces the RCM-ACT architecture, which combines action-chunking transformers with real-time kinematic realignment. Trained solely on stereo visual data and instrument kinematics from expert demonstrations in a biomimetic eye model, AutoRing successfully completes ring grasping and positioning tasks without explicit depth sensing. Experimental validation demonstrates end-to-end autonomy under uncalibrated microscopy conditions. The results provide a viable framework for developing intelligent eye-surgical systems capable of complex intraocular procedures.
SSPO: Self-traced Step-wise Preference Optimization for Process Supervision and Reasoning Compression
Aug 18, 2025Test-time scaling has proven effective in further enhancing the performance of pretrained Large Language Models (LLMs). However, mainstream post-training methods (i.e., reinforcement learning (RL) with chain-of-thought (CoT) reasoning) often incur substantial computational overhead due to auxiliary models and overthinking. In this paper, we empirically reveal that the incorrect answers partially stem from verbose reasoning processes lacking correct self-fix, where errors accumulate across multiple reasoning steps. To this end, we propose Self-traced Step-wise Preference Optimization (SSPO), a pluggable RL process supervision framework that enables fine-grained optimization of each reasoning step. Specifically, SSPO requires neither auxiliary models nor stepwise manual annotations. Instead, it leverages step-wise preference signals generated by the model itself to guide the optimization process for reasoning compression. Experiments demonstrate that the generated reasoning sequences from SSPO are both accurate and succinct, effectively mitigating overthinking behaviors without compromising model performance across diverse domains and languages.
Dual-level Fuzzy Learning with Patch Guidance for Image Ordinal Regression
May 09, 2025Ordinal regression bridges regression and classification by assigning objects to ordered classes. While human experts rely on discriminative patch-level features for decisions, current approaches are limited by the availability of only image-level ordinal labels, overlooking fine-grained patch-level characteristics. In this paper, we propose a Dual-level Fuzzy Learning with Patch Guidance framework, named DFPG that learns precise feature-based grading boundaries from ambiguous ordinal labels, with patch-level supervision. Specifically, we propose patch-labeling and filtering strategies to enable the model to focus on patch-level features exclusively with only image-level ordinal labels available. We further design a dual-level fuzzy learning module, which leverages fuzzy logic to quantitatively capture and handle label ambiguity from both patch-wise and channel-wise perspectives. Extensive experiments on various image ordinal regression datasets demonstrate the superiority of our proposed method, further confirming its ability in distinguishing samples from difficult-to-classify categories. The code is available at https://github.com/ZJUMAI/DFPG-ord.
Uncertainty-Aware Multi-Expert Knowledge Distillation for Imbalanced Disease Grading
May 01, 2025Automatic disease image grading is a significant application of artificial intelligence for healthcare, enabling faster and more accurate patient assessments. However, domain shifts, which are exacerbated by data imbalance, introduce bias into the model, posing deployment difficulties in clinical applications. To address the problem, we propose a novel \textbf{U}ncertainty-aware \textbf{M}ulti-experts \textbf{K}nowledge \textbf{D}istillation (UMKD) framework to transfer knowledge from multiple expert models to a single student model. Specifically, to extract discriminative features, UMKD decouples task-agnostic and task-specific features with shallow and compact feature alignment in the feature space. At the output space, an uncertainty-aware decoupled distillation (UDD) mechanism dynamically adjusts knowledge transfer weights based on expert model uncertainties, ensuring robust and reliable distillation. Additionally, UMKD also tackles the problems of model architecture heterogeneity and distribution discrepancies between source and target domains, which are inadequately tackled by previous KD approaches. Extensive experiments on histology prostate grading (\textit{SICAPv2}) and fundus image grading (\textit{APTOS}) demonstrate that UMKD achieves a new state-of-the-art in both source-imbalanced and target-imbalanced scenarios, offering a robust and practical solution for real-world disease image grading.
Large language models could be rote learners
Apr 15, 2025
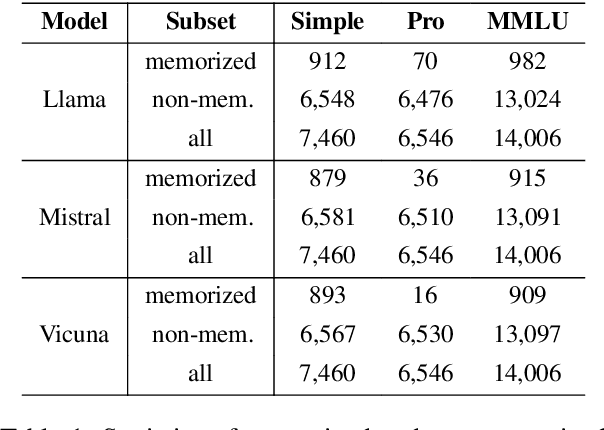
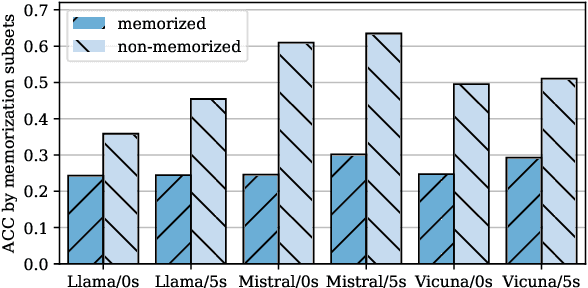

Multiple-choice question (MCQ) benchmarks are widely used for evaluating Large Language Models (LLMs), yet their reliability is undermined by benchmark contamination. In this study, we reframe contamination as an inherent aspect of learning and seek to disentangle genuine capability acquisition from superficial memorization in LLM evaluation. First, by analyzing model performance under different memorization conditions, we uncover a counterintuitive trend: LLMs perform worse on memorized MCQs than on non-memorized ones, indicating the coexistence of two distinct learning phenomena, i.e., rote memorization and genuine capability learning. To disentangle them, we propose TrinEval, a novel evaluation framework that reformulates MCQs into an alternative trinity format, reducing memorization while preserving knowledge assessment. Experiments validate TrinEval's effectiveness in reformulation, and its evaluation reveals that common LLMs may memorize by rote 20.5% of knowledge points (in MMLU on average).
AnyECG: Foundational Models for Electrocardiogram Analysis
Nov 17, 2024



Electrocardiogram (ECG), a non-invasive and affordable tool for cardiac monitoring, is highly sensitive in detecting acute heart attacks. However, due to the lengthy nature of ECG recordings, numerous machine learning methods have been developed for automated heart disease detection to reduce human workload. Despite these efforts, performance remains suboptimal. A key obstacle is the inherent complexity of ECG data, which includes heterogeneity (e.g., varying sampling rates), high levels of noise, demographic-related pattern shifts, and intricate rhythm-event associations. To overcome these challenges, this paper introduces AnyECG, a foundational model designed to extract robust representations from any real-world ECG data. Specifically, a tailored ECG Tokenizer encodes each fixed-duration ECG fragment into a token and, guided by proxy tasks, converts noisy, continuous ECG features into discrete, compact, and clinically meaningful local rhythm codes. These codes encapsulate basic morphological, frequency, and demographic information (e.g., sex), effectively mitigating signal noise. We further pre-train the AnyECG to learn rhythmic pattern associations across ECG tokens, enabling the capture of cardiac event semantics. By being jointly pre-trained on diverse ECG data sources, AnyECG is capable of generalizing across a wide range of downstream tasks where ECG signals are recorded from various devices and scenarios. Experimental results in anomaly detection, arrhythmia detection, corrupted lead generation, and ultra-long ECG signal analysis demonstrate that AnyECG learns common ECG knowledge from data and significantly outperforms cutting-edge methods in each respective task.
Fair Evaluation of Federated Learning Algorithms for Automated Breast Density Classification: The Results of the 2022 ACR-NCI-NVIDIA Federated Learning Challenge
May 22, 2024The correct interpretation of breast density is important in the assessment of breast cancer risk. AI has been shown capable of accurately predicting breast density, however, due to the differences in imaging characteristics across mammography systems, models built using data from one system do not generalize well to other systems. Though federated learning (FL) has emerged as a way to improve the generalizability of AI without the need to share data, the best way to preserve features from all training data during FL is an active area of research. To explore FL methodology, the breast density classification FL challenge was hosted in partnership with the American College of Radiology, Harvard Medical School's Mass General Brigham, University of Colorado, NVIDIA, and the National Institutes of Health National Cancer Institute. Challenge participants were able to submit docker containers capable of implementing FL on three simulated medical facilities, each containing a unique large mammography dataset. The breast density FL challenge ran from June 15 to September 5, 2022, attracting seven finalists from around the world. The winning FL submission reached a linear kappa score of 0.653 on the challenge test data and 0.413 on an external testing dataset, scoring comparably to a model trained on the same data in a central location.
* 16 pages, 9 figures
Personalized Heart Disease Detection via ECG Digital Twin Generation
Apr 17, 2024Heart diseases rank among the leading causes of global mortality, demonstrating a crucial need for early diagnosis and intervention. Most traditional electrocardiogram (ECG) based automated diagnosis methods are trained at population level, neglecting the customization of personalized ECGs to enhance individual healthcare management. A potential solution to address this limitation is to employ digital twins to simulate symptoms of diseases in real patients. In this paper, we present an innovative prospective learning approach for personalized heart disease detection, which generates digital twins of healthy individuals' anomalous ECGs and enhances the model sensitivity to the personalized symptoms. In our approach, a vector quantized feature separator is proposed to locate and isolate the disease symptom and normal segments in ECG signals with ECG report guidance. Thus, the ECG digital twins can simulate specific heart diseases used to train a personalized heart disease detection model. Experiments demonstrate that our approach not only excels in generating high-fidelity ECG signals but also improves personalized heart disease detection. Moreover, our approach ensures robust privacy protection, safeguarding patient data in model development.