 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Heart Disease Detection via ECG Digital Twin Generation
Apr 17, 2024Heart diseases rank among the leading causes of global mortality, demonstrating a crucial need for early diagnosis and intervention. Most traditional electrocardiogram (ECG) based automated diagnosis methods are trained at population level, neglecting the customization of personalized ECGs to enhance individual healthcare management. A potential solution to address this limitation is to employ digital twins to simulate symptoms of diseases in real patients. In this paper, we present an innovative prospective learning approach for personalized heart disease detection, which generates digital twins of healthy individuals' anomalous ECGs and enhances the model sensitivity to the personalized symptoms. In our approach, a vector quantized feature separator is proposed to locate and isolate the disease symptom and normal segments in ECG signals with ECG report guidance. Thus, the ECG digital twins can simulate specific heart diseases used to train a personalized heart disease detection model. Experiments demonstrate that our approach not only excels in generating high-fidelity ECG signals but also improves personalized heart disease detection. Moreover, our approach ensures robust privacy protection, safeguarding patient data in model development.
Cutting-Splicing data augmentation: A novel technology for medical image segmentation
Oct 17, 2022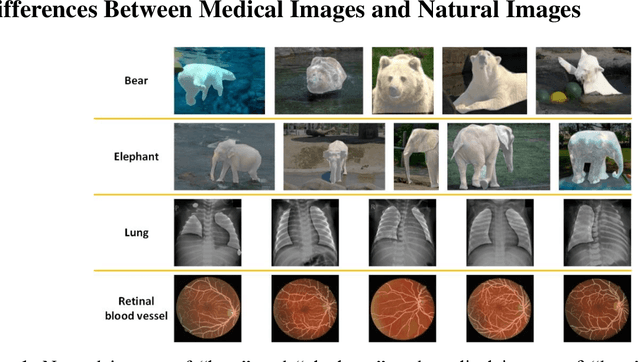
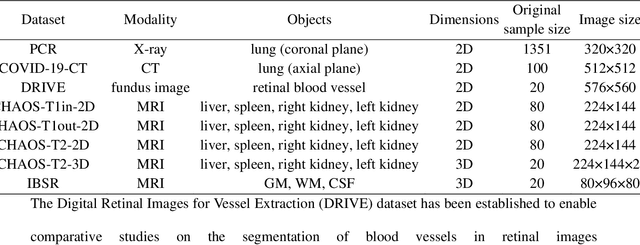
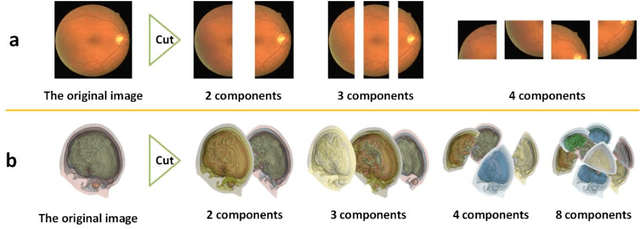
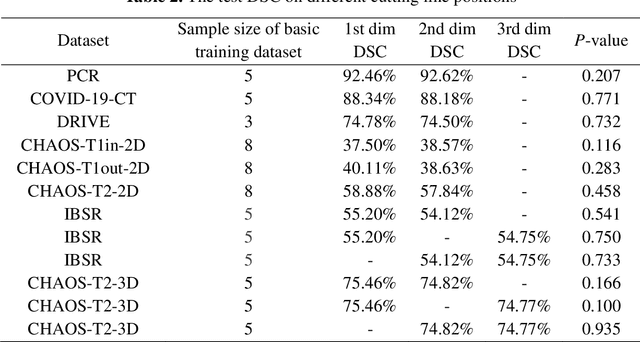
Background: Medical images are more difficult to acquire and annotate than natural images, which results in data augmentation technologies often being used in medical image segmentation tasks. Most data augmentation technologies used in medical segmentation were originally developed on natural images and do not take into account the characteristic that the overall layout of medical images is standard and fixed. Methods: Based on the characteristics of medical images, we developed the cutting-splicing data augmentation (CS-DA) method, a novel data augmentation technology for medical image segmentation. CS-DA augments the dataset by splicing different position components cut from different original medical images into a new image. The characteristics of the medical image result in the new image having the same layout as and similar appearance to the original image. Compared with classical data augmentation technologies, CS-DA is simpler and more robust. Moreover, CS-DA does not introduce any noise or fake information into the newly created image. Results: To explore the properties of CS-DA, many experiments are conducted on eight diverse datasets. On the training dataset with the small sample size, CS-DA can effectively increase the performance of the segmentation model. When CS-DA is used together with classical data augmentation technologies, the performance of the segmentation model can be further improved and is much better than that of CS-DA and classical data augmentation separately. We also explored the influence of the number of components, the position of the cutting line, and the splicing method on the CS-DA performance. Conclusions: The excellent performance of CS-DA in the experiment has confirmed the effectiveness of CS-DA, and provides a new data augmentation idea for the small sample segmentation task.