 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCutting-Splicing data augmentation: A novel technology for medical image segmentation
Oct 17, 2022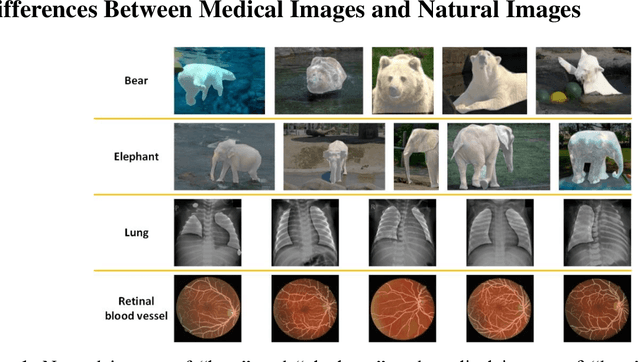
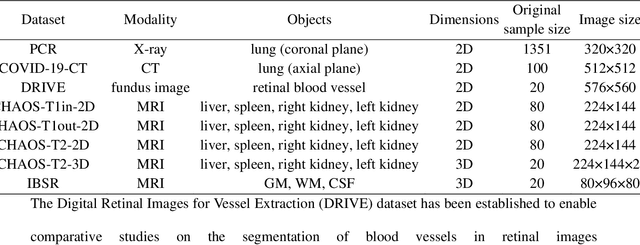
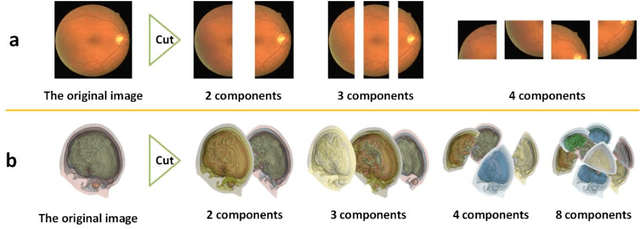
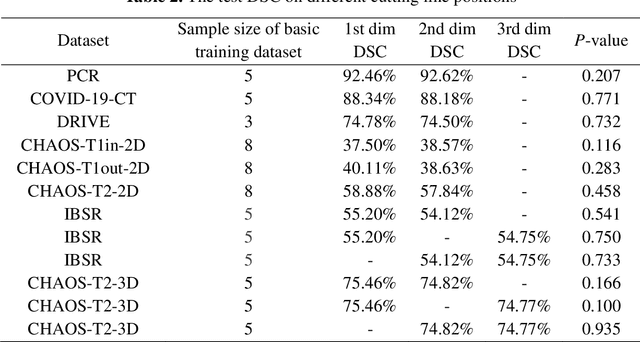
Background: Medical images are more difficult to acquire and annotate than natural images, which results in data augmentation technologies often being used in medical image segmentation tasks. Most data augmentation technologies used in medical segmentation were originally developed on natural images and do not take into account the characteristic that the overall layout of medical images is standard and fixed. Methods: Based on the characteristics of medical images, we developed the cutting-splicing data augmentation (CS-DA) method, a novel data augmentation technology for medical image segmentation. CS-DA augments the dataset by splicing different position components cut from different original medical images into a new image. The characteristics of the medical image result in the new image having the same layout as and similar appearance to the original image. Compared with classical data augmentation technologies, CS-DA is simpler and more robust. Moreover, CS-DA does not introduce any noise or fake information into the newly created image. Results: To explore the properties of CS-DA, many experiments are conducted on eight diverse datasets. On the training dataset with the small sample size, CS-DA can effectively increase the performance of the segmentation model. When CS-DA is used together with classical data augmentation technologies, the performance of the segmentation model can be further improved and is much better than that of CS-DA and classical data augmentation separately. We also explored the influence of the number of components, the position of the cutting line, and the splicing method on the CS-DA performance. Conclusions: The excellent performance of CS-DA in the experiment has confirmed the effectiveness of CS-DA, and provides a new data augmentation idea for the small sample segmentation task.
ShadowNet: A Secure and Efficient System for On-device Model Inference
Nov 11, 2020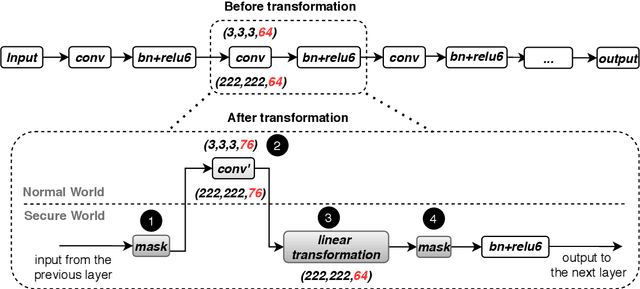
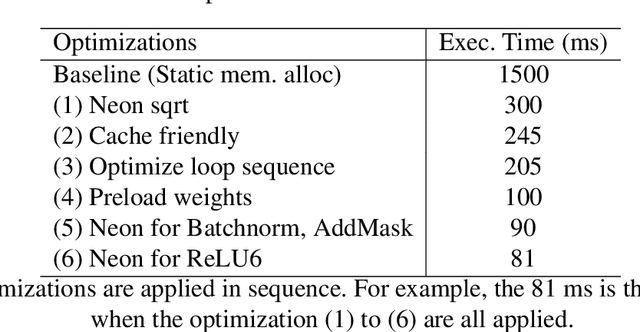
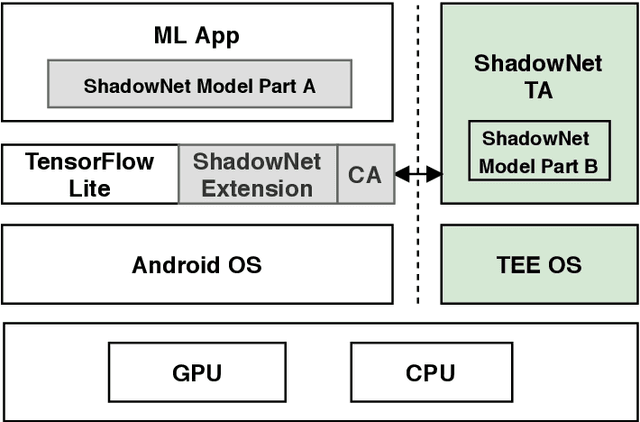
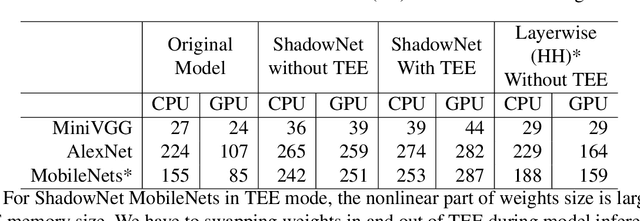
On-device machine learning (ML) is getting more and more popular as fast evolving AI accelerators emerge on mobile and edge devices. Consequently, thousands of proprietary ML models are being deployed on billions of untrusted devices, raising a serious security concern about the model privacy. However, how to protect the model privacy without losing access to the AI accelerators is a challenging problem. This paper presents a novel on-device model inference system called ShadowNet, which protects the model privacy with TEE while securely outsourcing the heavy linear layers of the model onto the hardware accelerators without trusting them. ShadowNet achieves it by transforming the weights of the linear layers before outsourcing them and restoring the results inside the TEE. The nonlinear layers are also kept secure inside the TEE. The transformation of the weights and the restoration of the results are designed in a way that can be implemented efficiently. We have built a ShadowNet prototype based on TensorFlow Lite and applied it on three popular CNNs including AlexNet, MiniVGG and MobileNets. Our evaluation shows that the ShadowNet transformed models have comparable performance with the original models, offering a promising solution for secure on-device model inference.
MEUZZ: Smart Seed Scheduling for Hybrid Fuzzing
Feb 20, 2020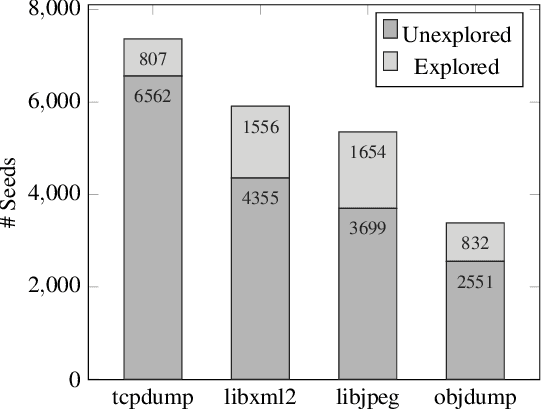



Seed scheduling is a prominent factor in determining the yields of hybrid fuzzing. Existing hybrid fuzzers schedule seeds based on fixed heuristics that aim to predict input utilities. However, such heuristics are not generalizable as there exists no one-size-fits-all rule applicable to different programs. They may work well on the programs from which they were derived, but not others. To overcome this problem, we design a Machine learning-Enhanced hybrid fUZZing system (MEUZZ), which employs supervised machine learning for adaptive and generalizable seed scheduling. MEUZZ determines which new seeds are expected to produce better fuzzing yields based on the knowledge learned from past seed scheduling decisions made on the same or similar programs. MEUZZ's learning is based on a series of features extracted via code reachability and dynamic analysis, which incurs negligible runtime overhead (in microseconds). Moreover, MEUZZ automatically infers the data labels by evaluating the fuzzing performance of each selected seed. As a result, MEUZZ is generally applicable to, and performs well on, various kinds of programs. Our evaluation shows MEUZZ significantly outperforms the state-of-the-art grey-box and hybrid fuzzers, achieving 27.1% more code coverage than QSYM. The learned models are reusable and transferable, which boosts fuzzing performance by 7.1% on average and improves 68% of the 56 cross-program fuzzing campaigns. MEUZZ discovered 47 deeply hidden and previously unknown bugs--with 21 confirmed and fixed by the developers--when fuzzing 8 well-tested programs with the same configurations as used in previous work.
Mind Your Weight: A Large-scale Study on Insufficient Machine Learning Model Protection in Mobile Apps
Feb 18, 2020
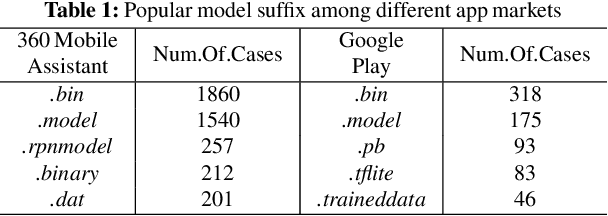
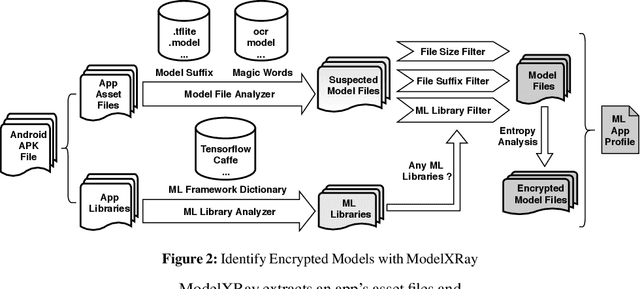
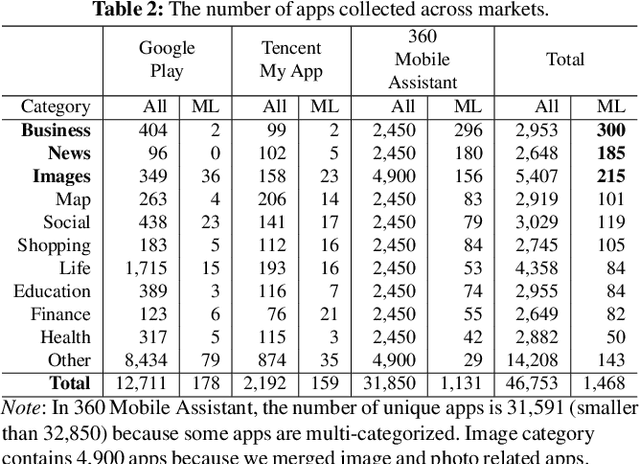
On-device machine learning (ML) is quickly gaining popularity among mobile apps. It allows offline model inference while preserving user privacy. However, ML models, considered as core intellectual properties of model owners, are now stored on billions of untrusted devices and subject to potential thefts. Leaked models can cause both severe financial loss and security consequences. This paper presents the first empirical study of ML model protection on mobile devices. Our study aims to answer three open questions with quantitative evidence: How widely is model protection used in apps? How robust are existing model protection techniques? How much can (stolen) models cost? To that end, we built a simple app analysis pipeline and analyzed 46,753 popular apps collected from the US and Chinese app markets. We identified 1,468 ML apps spanning all popular app categories. We found that, alarmingly, 41% of ML apps do not protect their models at all, which can be trivially stolen from app packages. Even for those apps that use model protection or encryption, we were able to extract the models from 66% of them via unsophisticated dynamic analysis techniques. The extracted models are mostly commercial products and used for face recognition, liveness detection, ID/bank card recognition, and malware detection. We quantitatively estimated the potential financial impact of a leaked model, which can amount to millions of dollars for different stakeholders. Our study reveals that on-device models are currently at high risk of being leaked; attackers are highly motivated to steal such models. Drawn from our large-scale study, we report our insights into this emerging security problem and discuss the technical challenges, hoping to inspire future research on robust and practical model protection for mobile devices.