 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEUZZ: Smart Seed Scheduling for Hybrid Fuzzing
Feb 20, 2020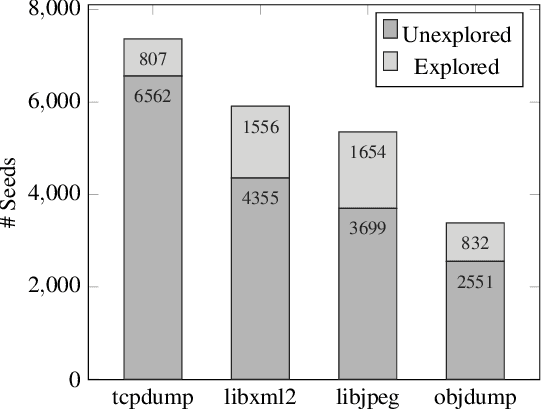



Seed scheduling is a prominent factor in determining the yields of hybrid fuzzing. Existing hybrid fuzzers schedule seeds based on fixed heuristics that aim to predict input utilities. However, such heuristics are not generalizable as there exists no one-size-fits-all rule applicable to different programs. They may work well on the programs from which they were derived, but not others. To overcome this problem, we design a Machine learning-Enhanced hybrid fUZZing system (MEUZZ), which employs supervised machine learning for adaptive and generalizable seed scheduling. MEUZZ determines which new seeds are expected to produce better fuzzing yields based on the knowledge learned from past seed scheduling decisions made on the same or similar programs. MEUZZ's learning is based on a series of features extracted via code reachability and dynamic analysis, which incurs negligible runtime overhead (in microseconds). Moreover, MEUZZ automatically infers the data labels by evaluating the fuzzing performance of each selected seed. As a result, MEUZZ is generally applicable to, and performs well on, various kinds of programs. Our evaluation shows MEUZZ significantly outperforms the state-of-the-art grey-box and hybrid fuzzers, achieving 27.1% more code coverage than QSYM. The learned models are reusable and transferable, which boosts fuzzing performance by 7.1% on average and improves 68% of the 56 cross-program fuzzing campaigns. MEUZZ discovered 47 deeply hidden and previously unknown bugs--with 21 confirmed and fixed by the developers--when fuzzing 8 well-tested programs with the same configurations as used in previous work.
Novel Feature Extraction, Selection and Fusion for Effective Malware Family Classification
Mar 10, 2016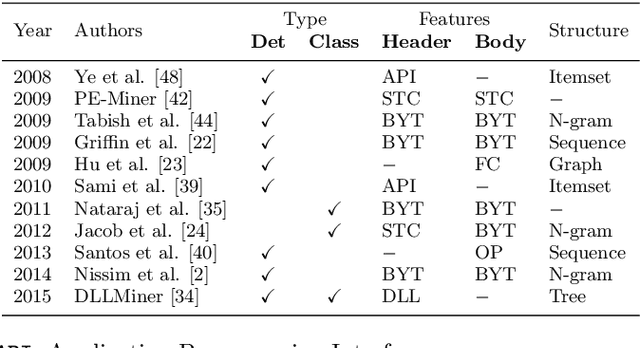


Modern malware is designed with mutation characteristics, namely polymorphism and metamorphism, which causes an enormous growth in the number of variants of malware samples. Categorization of malware samples on the basis of their behaviors is essential for the computer security community, because they receive huge number of malware everyday, and the signature extraction process is usually based on malicious parts characterizing malware families. Microsoft released a malware classification challenge in 2015 with a huge dataset of near 0.5 terabytes of data, containing more than 20K malware samples. The analysis of this dataset inspired the development of a novel paradigm that is effective in categorizing malware variants into their actual family groups. This paradigm is presented and discussed in the present paper, where emphasis has been given to the phases related to the extraction, and selection of a set of novel features for the effective representation of malware samples. Features can be grouped according to different characteristics of malware behavior, and their fusion is performed according to a per-class weighting paradigm. The proposed method achieved a very high accuracy ($\approx$ 0.998) on the Microsoft Malware Challenge dataset.