 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Learning and Pairwise Ranking for Implicit Feedback in Recommendation Systems
Jul 12, 2018


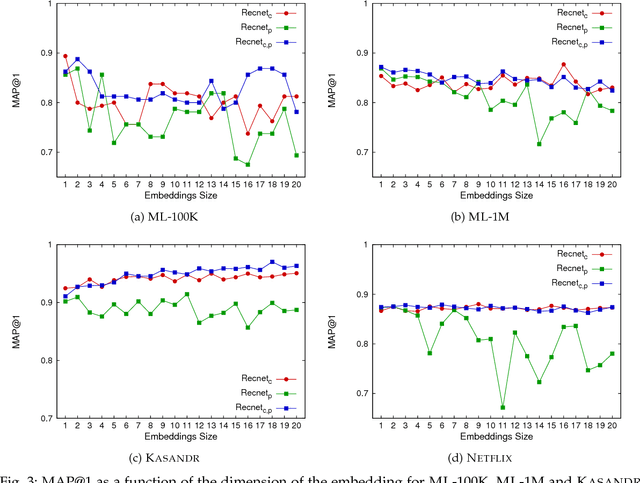
In this paper, we propose a novel ranking framework for collaborative filtering with the overall aim of learning user preferences over items by minimizing a pairwise ranking loss. We show the minimization problem involves dependent random variables and provide a theoretical analysis by proving the consistency of the empirical risk minimization in the worst case where all users choose a minimal number of positive and negative items. We further derive a Neural-Network model that jointly learns a new representation of users and items in an embedded space as well as the preference relation of users over the pairs of items. The learning objective is based on three scenarios of ranking losses that control the ability of the model to maintain the ordering over the items induced from the users' preferences, as well as, the capacity of the dot-product defined in the learned embedded space to produce the ordering. The proposed model is by nature suitable for implicit feedback and involves the estimation of only very few parameters. Through extensive experiments on several real-world benchmarks on implicit data, we show the interest of learning the preference and the embedding simultaneously when compared to learning those separately. We also demonstrate that our approach is very competitive with the best state-of-the-art collaborative filtering techniques proposed for implicit feedback.
Exponential Machines
Dec 08, 2017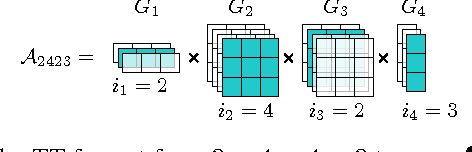
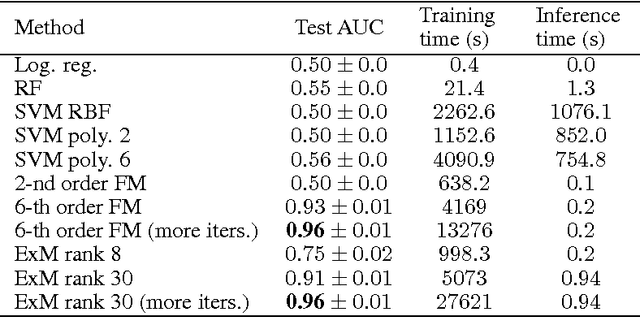
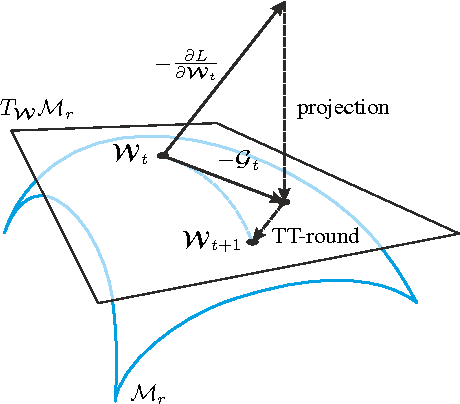
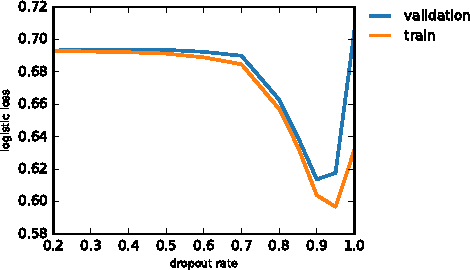
Modeling interactions between features improves the performance of machine learning solutions in many domains (e.g. recommender systems or sentiment analysis). In this paper, we introduce Exponential Machines (ExM), a predictor that models all interactions of every order. The key idea is to represent an exponentially large tensor of parameters in a factorized format called Tensor Train (TT). The Tensor Train format regularizes the model and lets you control the number of underlying parameters. To train the model, we develop a stochastic Riemannian optimization procedure, which allows us to fit tensors with 2^160 entries. We show that the model achieves state-of-the-art performance on synthetic data with high-order interactions and that it works on par with high-order factorization machines on a recommender system dataset MovieLens 100K.
Novel Feature Extraction, Selection and Fusion for Effective Malware Family Classification
Mar 10, 2016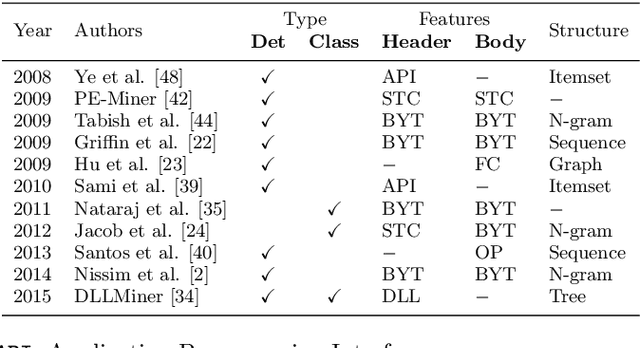


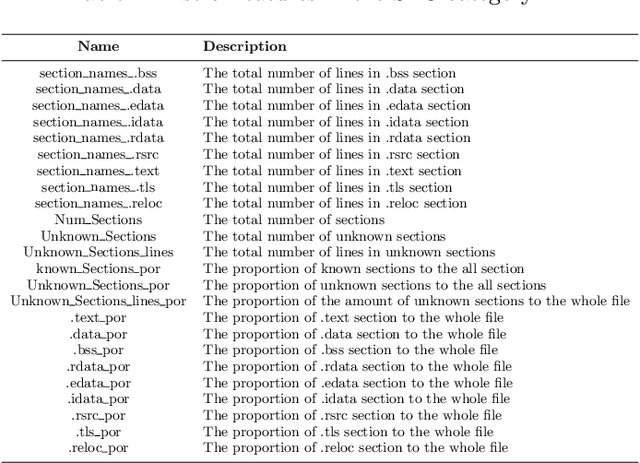
Modern malware is designed with mutation characteristics, namely polymorphism and metamorphism, which causes an enormous growth in the number of variants of malware samples. Categorization of malware samples on the basis of their behaviors is essential for the computer security community, because they receive huge number of malware everyday, and the signature extraction process is usually based on malicious parts characterizing malware families. Microsoft released a malware classification challenge in 2015 with a huge dataset of near 0.5 terabytes of data, containing more than 20K malware samples. The analysis of this dataset inspired the development of a novel paradigm that is effective in categorizing malware variants into their actual family groups. This paradigm is presented and discussed in the present paper, where emphasis has been given to the phases related to the extraction, and selection of a set of novel features for the effective representation of malware samples. Features can be grouped according to different characteristics of malware behavior, and their fusion is performed according to a per-class weighting paradigm. The proposed method achieved a very high accuracy ($\approx$ 0.998) on the Microsoft Malware Challenge dataset.