 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning What Matters: Dynamic Dimension Selection and Aggregation for Interpretable Vision-Language Reward Modeling
Apr 07, 2026Vision-language reward modeling faces a dilemma: generative approaches are interpretable but slow, while discriminative ones are efficient but act as opaque "black boxes." To bridge this gap, we propose VL-MDR (Vision-Language Multi-Dimensional Reward), a framework that dynamically decomposes evaluation into granular, interpretable dimensions. Instead of outputting a monolithic scalar, VL-MDR employs a visual-aware gating mechanism to identify relevant dimensions and adaptively weight them (e.g., Hallucination, Reasoning) for each specific input. To support this, we curate a dataset of 321k vision-language preference pairs annotated across 21 fine-grained dimensions. Extensive experiments show that VL-MDR consistently outperforms existing open-source reward models on benchmarks like VL-RewardBench. Furthermore, we show that VL-MDR-constructed preference pairs effectively enable DPO alignment to mitigate visual hallucinations and improve reliability, providing a scalable solution for VLM alignment.
LLM-based Few-Shot Early Rumor Detection with Imitation Agent
Dec 20, 2025Early Rumor Detection (EARD) aims to identify the earliest point at which a claim can be accurately classified based on a sequence of social media posts. This is especially challenging in data-scarce settings. While Large Language Models (LLMs) perform well in few-shot NLP tasks, they are not well-suited for time-series data and are computationally expensive for both training and inference. In this work, we propose a novel EARD framework that combines an autonomous agent and an LLM-based detection model, where the agent acts as a reliable decision-maker for \textit{early time point determination}, while the LLM serves as a powerful \textit{rumor detector}. This approach offers the first solution for few-shot EARD, necessitating only the training of a lightweight agent and allowing the LLM to remain training-free. Extensive experiments on four real-world datasets show our approach boosts performance across LLMs and surpasses existing EARD methods in accuracy and earliness.
Mitigating Hallucination of Large Vision-Language Models via Dynamic Logits Calibration
Jun 26, 2025Large Vision-Language Models (LVLMs) have demonstrated significant advancements in multimodal understanding, yet they are frequently hampered by hallucination-the generation of text that contradicts visual input. Existing training-free decoding strategies exhibit critical limitations, including the use of static constraints that do not adapt to semantic drift during generation, inefficiency stemming from the need for multiple forward passes, and degradation of detail due to overly rigid intervention rules. To overcome these challenges, this paper introduces Dynamic Logits Calibration (DLC), a novel training-free decoding framework designed to dynamically align text generation with visual evidence at inference time. At the decoding phase, DLC step-wise employs CLIP to assess the semantic alignment between the input image and the generated text sequence. Then, the Relative Visual Advantage (RVA) of candidate tokens is evaluated against a dynamically updated contextual baseline, adaptively adjusting output logits to favor tokens that are visually grounded. Furthermore, an adaptive weighting mechanism, informed by a real-time context alignment score, carefully balances the visual guidance while ensuring the overall quality of the textual output. Extensive experiments conducted across diverse benchmarks and various LVLM architectures (such as LLaVA, InstructBLIP, and MiniGPT-4) demonstrate that DLC significantly reduces hallucinations, outperforming current methods while maintaining high inference efficiency by avoiding multiple forward passes. Overall, we present an effective and efficient decoding-time solution to mitigate hallucinations, thereby enhancing the reliability of LVLMs for more practices. Code will be released on Github.
New Recipe for Semi-supervised Community Detection: Clique Annealing under Crystallization Kinetics
Apr 22, 2025Semi-supervised community detection methods are widely used for identifying specific communities due to the label scarcity. Existing semi-supervised community detection methods typically involve two learning stages learning in both initial identification and subsequent adjustment, which often starts from an unreasonable community core candidate. Moreover, these methods encounter scalability issues because they depend on reinforcement learning and generative adversarial networks, leading to higher computational costs and restricting the selection of candidates. To address these limitations, we draw a parallel between crystallization kinetics and community detection to integrate the spontaneity of the annealing process into community detection. Specifically, we liken community detection to identifying a crystal subgrain (core) that expands into a complete grain (community) through a process similar to annealing. Based on this finding, we propose CLique ANNealing (CLANN), which applies kinetics concepts to community detection by integrating these principles into the optimization process to strengthen the consistency of the community core. Subsequently, a learning-free Transitive Annealer was employed to refine the first-stage candidates by merging neighboring cliques and repositioning the community core, enabling a spontaneous growth process that enhances scalability. Extensive experiments on \textbf{43} different network settings demonstrate that CLANN outperforms state-of-the-art methods across multiple real-world datasets, showcasing its exceptional efficacy and efficiency in community detection.
Generation of Drug-Induced Cardiac Reactions towards Virtual Clinical Trials
Feb 11, 2025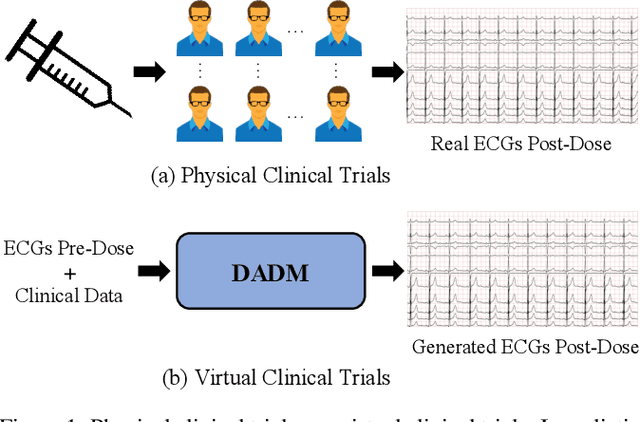
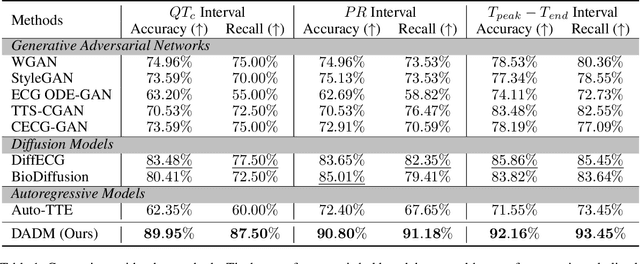
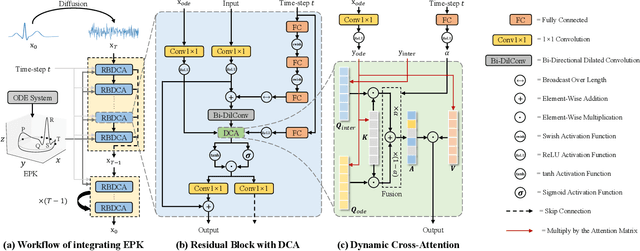
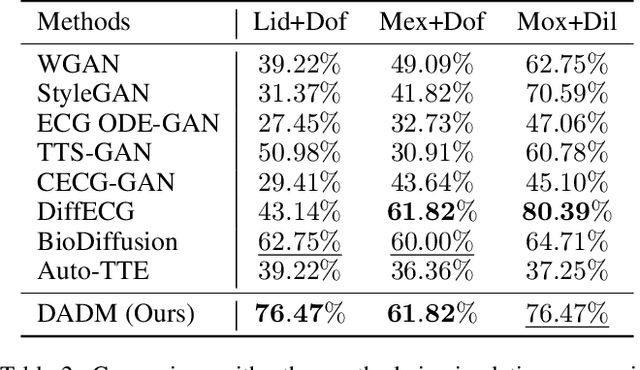
Clinical trials are pivotal in cardiac drug development, yet they often fail due to inadequate efficacy and unexpected safety issues, leading to significant financial losses. Using in-silico trials to replace a part of physical clinical trials, e.g., leveraging advanced generative models to generate drug-influenced electrocardiograms (ECGs), seems an effective method to reduce financial risk and potential harm to trial participants. While existing generative models have demonstrated progress in ECG generation, they fall short in modeling drug reactions due to limited fidelity and inability to capture individualized drug response patterns. In this paper, we propose a Drug-Aware Diffusion Model (DADM), which could simulate individualized drug reactions while ensuring fidelity. To ensure fidelity, we construct a set of ordinary differential equations to provide external physical knowledge (EPK) of the realistic ECG morphology. The EPK is used to adaptively constrain the morphology of the generated ECGs through a dynamic cross-attention (DCA) mechanism. Furthermore, we propose an extension of ControlNet to incorporate demographic and drug data, simulating individual drug reactions. We compare DADM with the other eight state-of-the-art ECG generative models on two real-world databases covering 8 types of drug regimens. The results demonstrate that DADM can more accurately simulate drug-induced changes in ECGs, improving the accuracy by at least 5.79% and recall by 8%.
Take Your Steps: Hierarchically Efficient Pulmonary Disease Screening via CT Volume Compression
Dec 03, 2024Deep learning models are widely used to process Computed Tomography (CT) data in the automated screening of pulmonary diseases, significantly reducing the workload of physicians. However, the three-dimensional nature of CT volumes involves an excessive number of voxels, which significantly increases the complexity of model processing. Previous screening approaches often overlook this issue, which undoubtedly reduces screening efficiency. Towards efficient and effective screening, we design a hierarchical approach to reduce the computational cost of pulmonary disease screening. The new approach re-organizes the screening workflows into three steps. First, we propose a Computed Tomography Volume Compression (CTVC) method to select a small slice subset that comprehensively represents the whole CT volume. Second, the selected CT slices are used to detect pulmonary diseases coarsely via a lightweight classification model. Third, an uncertainty measurement strategy is applied to identify samples with low diagnostic confidence, which are re-detected by radiologists. Experiments on two public pulmonary disease datasets demonstrate that our approach achieves comparable accuracy and recall while reducing the time by 50%-70% compared with the counterparts using full CT volumes. Besides, we also found that our approach outperforms previous cutting-edge CTVC methods in retaining important indications after compression.
Enhancing Semi-Supervised Learning via Representative and Diverse Sample Selection
Sep 18, 2024Semi-Supervised Learning (SSL) has become a preferred paradigm in many deep learning tasks, which reduces the need for human labor. Previous studies primarily focus on effectively utilising the labelled and unlabeled data to improve performance. However, we observe that how to select samples for labelling also significantly impacts performance, particularly under extremely low-budget settings. The sample selection task in SSL has been under-explored for a long time. To fill in this gap, we propose a Representative and Diverse Sample Selection approach (RDSS). By adopting a modified Frank-Wolfe algorithm to minimise a novel criterion $\alpha$-Maximum Mean Discrepancy ($\alpha$-MMD), RDSS samples a representative and diverse subset for annotation from the unlabeled data. We demonstrate that minimizing $\alpha$-MMD enhances the generalization ability of low-budget learning. Experimental results show that RDSS consistently improves the performance of several popular SSL frameworks and outperforms the state-of-the-art sample selection approaches used in Active Learning (AL) and Semi-Supervised Active Learning (SSAL), even with constrained annotation budgets.
TeleOR: Real-time Telemedicine System for Full-Scene Operating Room
Jul 29, 2024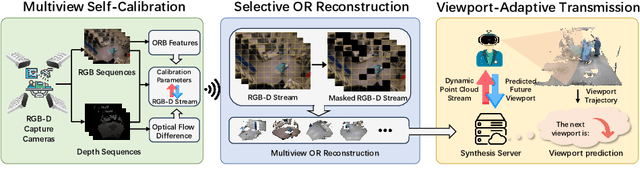


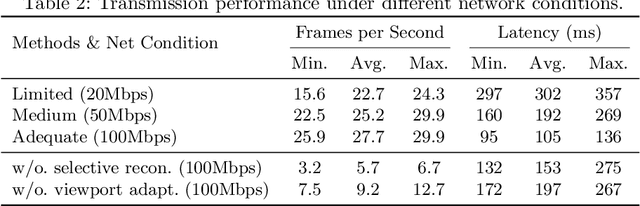
The advent of telemedicine represents a transformative development in leveraging technology to extend the reach of specialized medical expertise to remote surgeries, a field where the immediacy of expert guidance is paramount. However, the intricate dynamics of Operating Room (OR) scene pose unique challenges for telemedicine, particularly in achieving high-fidelity, real-time scene reconstruction and transmission amidst obstructions and bandwidth limitations. This paper introduces TeleOR, a pioneering system designed to address these challenges through real-time OR scene reconstruction for Tele-intervention. TeleOR distinguishes itself with three innovative approaches: dynamic self-calibration, which leverages inherent scene features for calibration without the need for preset markers, allowing for obstacle avoidance and real-time camera adjustment; selective OR reconstruction, focusing on dynamically changing scene segments to reduce reconstruction complexity; and viewport-adaptive transmission, optimizing data transmission based on real-time client feedback to efficiently deliver high-quality 3D reconstructions within bandwidth constraints. Comprehensive experiments on the 4D-OR surgical scene dataset demostrate the superiority and applicability of TeleOR, illuminating the potential to revolutionize tele-interventions by overcoming the spatial and technical barriers inherent in remote surgical guidance.
Imitating Cost-Constrained Behaviors in Reinforcement Learning
Mar 27, 2024Complex planning and scheduling problems have long been solved using various optimization or heuristic approaches. In recent years, imitation learning that aims to learn from expert demonstrations has been proposed as a viable alternative to solving these problems. Generally speaking, imitation learning is designed to learn either the reward (or preference) model or directly the behavioral policy by observing the behavior of an expert. Existing work in imitation learning and inverse reinforcement learning has focused on imitation primarily in unconstrained settings (e.g., no limit on fuel consumed by the vehicle). However, in many real-world domains, the behavior of an expert is governed not only by reward (or preference) but also by constraints. For instance, decisions on self-driving delivery vehicles are dependent not only on the route preferences/rewards (depending on past demand data) but also on the fuel in the vehicle and the time available. In such problems, imitation learning is challenging as decisions are not only dictated by the reward model but are also dependent on a cost-constrained model. In this paper, we provide multiple methods that match expert distributions in the presence of trajectory cost constraints through (a) Lagrangian-based method; (b) Meta-gradients to find a good trade-off between expected return and minimizing constraint violation; and (c) Cost-violation-based alternating gradient. We empirically show that leading imitation learning approaches imitate cost-constrained behaviors poorly and our meta-gradient-based approach achieves the best performance.
Crafting a Good Prompt or Providing Exemplary Dialogues? A Study of In-Context Learning for Persona-based Dialogue Generation
Feb 17, 2024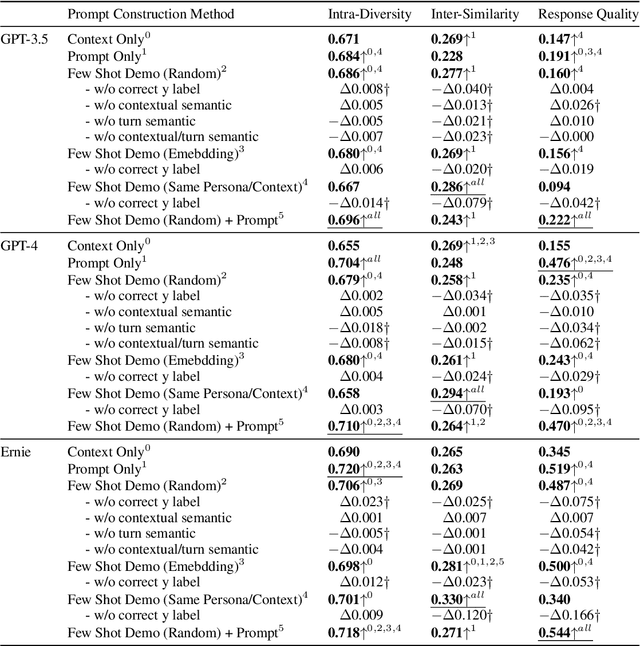
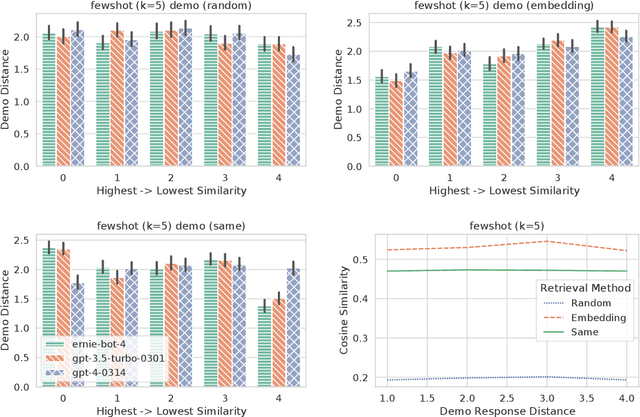
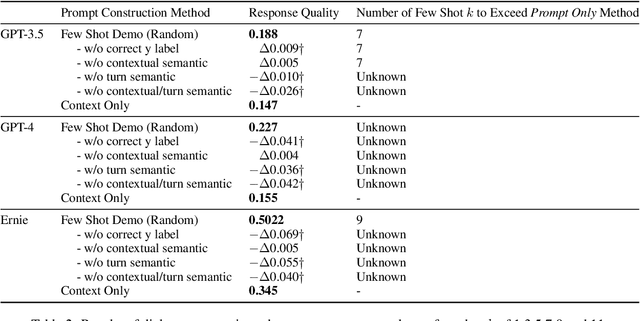
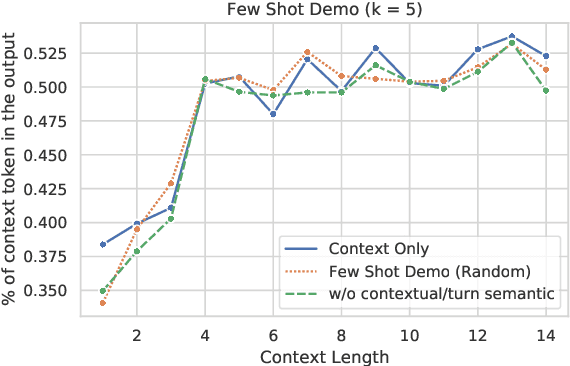
Previous in-context learning (ICL) research has focused on tasks such as classification, machine translation, text2table, etc., while studies on whether ICL can improve human-like dialogue generation are scarce. Our work fills this gap by systematically investigating the ICL capabilities of large language models (LLMs) in persona-based dialogue generation, conducting extensive experiments on high-quality real human Chinese dialogue datasets. From experimental results, we draw three conclusions: 1) adjusting prompt instructions is the most direct, effective, and economical way to improve generation quality; 2) randomly retrieving demonstrations (demos) achieves the best results, possibly due to the greater diversity and the amount of effective information; counter-intuitively, retrieving demos with a context identical to the query performs the worst; 3) even when we destroy the multi-turn associations and single-turn semantics in the demos, increasing the number of demos still improves dialogue performance, proving that LLMs can learn from corrupted dialogue demos. Previous explanations of the ICL mechanism, such as $n$-gram induction head, cannot fully account for this phenomenon.