 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPSL: Representing Volumetric Video via Content-Promoted Scene Layers
Nov 18, 2025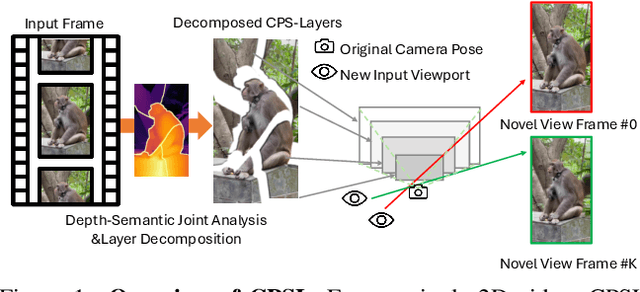

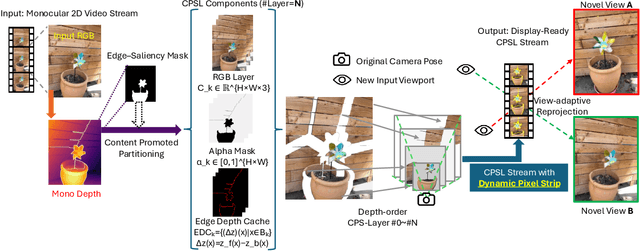
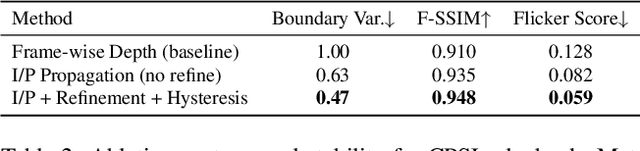
Volumetric video enables immersive and interactive visual experiences by supporting free viewpoint exploration and realistic motion parallax. However, existing volumetric representations from explicit point clouds to implicit neural fields, remain costly in capture, computation, and rendering, which limits their scalability for on-demand video and reduces their feasibility for real-time communication. To bridge this gap, we propose Content-Promoted Scene Layers (CPSL), a compact 2.5D video representation that brings the perceptual benefits of volumetric video to conventional 2D content. Guided by per-frame depth and content saliency, CPSL decomposes each frame into a small set of geometry-consistent layers equipped with soft alpha bands and an edge-depth cache that jointly preserve occlusion ordering and boundary continuity. These lightweight, 2D-encodable assets enable parallax-corrected novel-view synthesis via depth-weighted warping and front-to-back alpha compositing, bypassing expensive 3D reconstruction. Temporally, CPSL maintains inter-frame coherence using motion-guided propagation and per-layer encoding, supporting real-time playback with standard video codecs. Across multiple benchmarks, CPSL achieves superior perceptual quality and boundary fidelity compared with layer-based and neural-field baselines while reducing storage and rendering cost by several folds. Our approach offer a practical path from 2D video to scalable 2.5D immersive media.
LLMCount: Enhancing Stationary mmWave Detection with Multimodal-LLM
Sep 24, 2024



Millimeter wave sensing provides people with the capability of sensing the surrounding crowds in a non-invasive and privacy-preserving manner, which holds huge application potential. However, detecting stationary crowds remains challenging due to several factors such as minimal movements (like breathing or casual fidgets), which can be easily treated as noise clusters during data collection and consequently filtered in the following processing procedures. Additionally, the uneven distribution of signal power due to signal power attenuation and interferences resulting from external reflectors or absorbers further complicates accurate detection. To address these challenges and enable stationary crowd detection across various application scenarios requiring specialized domain adaption, we introduce LLMCount, the first system to harness the capabilities of large-language models (LLMs) to enhance crowd detection performance. By exploiting the decision-making capability of LLM, we can successfully compensate the signal power to acquire a uniform distribution and thereby achieve a detection with higher accuracy. To assess the system's performance, comprehensive evaluations are conducted under diversified scenarios like hall, meeting room, and cinema. The evaluation results show that our proposed approach reaches high detection accuracy with lower overall latency compared with previous methods.
TeleOR: Real-time Telemedicine System for Full-Scene Operating Room
Jul 29, 2024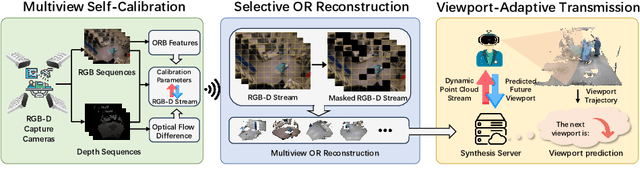


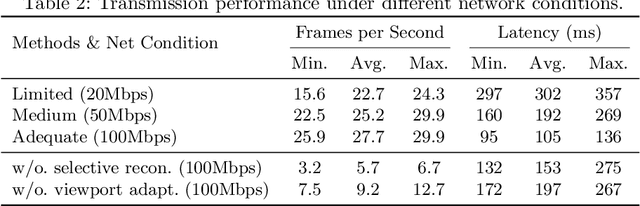
The advent of telemedicine represents a transformative development in leveraging technology to extend the reach of specialized medical expertise to remote surgeries, a field where the immediacy of expert guidance is paramount. However, the intricate dynamics of Operating Room (OR) scene pose unique challenges for telemedicine, particularly in achieving high-fidelity, real-time scene reconstruction and transmission amidst obstructions and bandwidth limitations. This paper introduces TeleOR, a pioneering system designed to address these challenges through real-time OR scene reconstruction for Tele-intervention. TeleOR distinguishes itself with three innovative approaches: dynamic self-calibration, which leverages inherent scene features for calibration without the need for preset markers, allowing for obstacle avoidance and real-time camera adjustment; selective OR reconstruction, focusing on dynamically changing scene segments to reduce reconstruction complexity; and viewport-adaptive transmission, optimizing data transmission based on real-time client feedback to efficiently deliver high-quality 3D reconstructions within bandwidth constraints. Comprehensive experiments on the 4D-OR surgical scene dataset demostrate the superiority and applicability of TeleOR, illuminating the potential to revolutionize tele-interventions by overcoming the spatial and technical barriers inherent in remote surgical guidance.
AI-Enhanced Virtual Reality in Medicine: A Comprehensive Survey
Feb 05, 2024


With the rapid advance of computer graphics and artificial intelligence technologies, the ways we interact with the world have undergone a transformative shift. Virtual Reality (VR) technology, aided by artificial intelligence (AI), has emerged as a dominant interaction media in multiple application areas, thanks to its advantage of providing users with immersive experiences. Among those applications, medicine is considered one of the most promising areas. In this paper, we present a comprehensive examination of the burgeoning field of AI-enhanced VR applications in medical care and services. By introducing a systematic taxonomy, we meticulously classify the pertinent techniques and applications into three well-defined categories based on different phases of medical diagnosis and treatment: Visualization Enhancement, VR-related Medical Data Processing, and VR-assisted Intervention. This categorization enables a structured exploration of the diverse roles that AI-powered VR plays in the medical domain, providing a framework for a more comprehensive understanding and evaluation of these technologies. To our best knowledge, this is the first systematic survey of AI-powered VR systems in medical settings, laying a foundation for future research in this interdisciplinary domain.
From Capture to Display: A Survey on Volumetric Video
Sep 11, 2023Volumetric video, which offers immersive viewing experiences, is gaining increasing prominence. With its six degrees of freedom, it provides viewers with greater immersion and interactivity compared to traditional videos. Despite their potential, volumetric video services poses significant challenges. This survey conducts a comprehensive review of the existing literature on volumetric video. We firstly provide a general framework of volumetric video services, followed by a discussion on prerequisites for volumetric video, encompassing representations, open datasets, and quality assessment metrics. Then we delve into the current methodologies for each stage of the volumetric video service pipeline, detailing capturing, compression, transmission, rendering, and display techniques. Lastly, we explore various applications enabled by this pioneering technology and we present an array of research challenges and opportunities in the domain of volumetric video services. This survey aspires to provide a holistic understanding of this burgeoning field and shed light on potential future research trajectories, aiming to bring the vision of volumetric video to fruition.
FSVVD: A Dataset of Full Scene Volumetric Video
Mar 07, 2023Recent years have witnessed a rapid development of immersive multimedia which bridges the gap between the real world and virtual space. Volumetric videos, as an emerging representative 3D video paradigm that empowers extended reality, stand out to provide unprecedented immersive and interactive video watching experience. Despite the tremendous potential, the research towards 3D volumetric video is still in its infancy, relying on sufficient and complete datasets for further exploration. However, existing related volumetric video datasets mostly only include a single object, lacking details about the scene and the interaction between them. In this paper, we focus on the current most widely used data format, point cloud, and for the first time release a full-scene volumetric video dataset that includes multiple people and their daily activities interacting with the external environments. Comprehensive dataset description and analysis are conducted, with potential usage of this dataset. The dataset and additional tools can be accessed via the following website: https://cuhksz-inml.github.io/full_scene_volumetric_video_dataset/.
Application of Time Series Analysis to Traffic Accidents in Los Angeles
Nov 28, 2019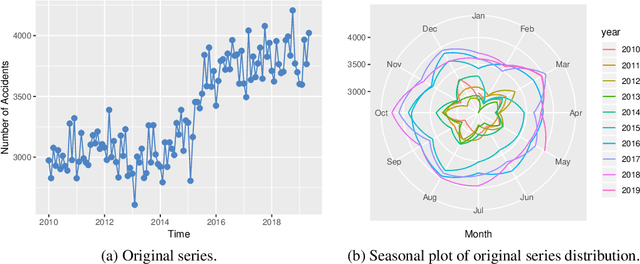



With the improvements of Los Angeles in many aspects, people in mounting numbers tend to live or travel to the city. The primary objective of this paper is to apply a set of methods for the time series analysis of traffic accidents in Los Angeles in the past few years. The number of traffic accidents, collected from 2010 to 2019 monthly reveals that the traffic accident happens seasonally and increasing with fluctuation. This paper utilizes the ensemble methods to combine several different methods to model the data from various perspectives, which can lead to better forecasting accuracy. The IMA(1, 1), ETS(A, N, A), and two models with Fourier items are failed in independence assumption checking. However, the Online Gradient Descent (OGD) model generated by the ensemble method shows the perfect fit in the data modeling, which is the state-of-the-art model among our candidate models. Therefore, it can be easier to accurately forecast future traffic accidents based on previous data through our model, which can help designers to make better plans.