 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPSL: Representing Volumetric Video via Content-Promoted Scene Layers
Nov 18, 2025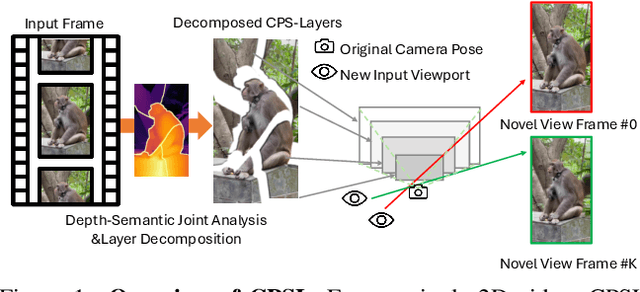

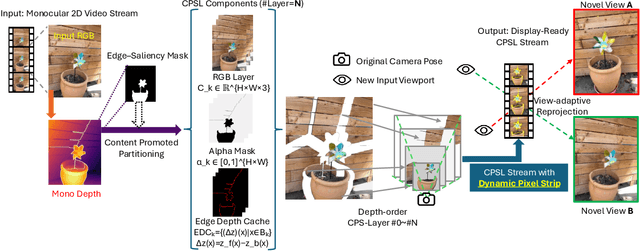
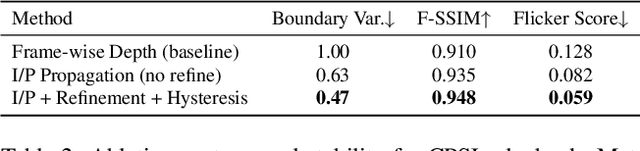
Volumetric video enables immersive and interactive visual experiences by supporting free viewpoint exploration and realistic motion parallax. However, existing volumetric representations from explicit point clouds to implicit neural fields, remain costly in capture, computation, and rendering, which limits their scalability for on-demand video and reduces their feasibility for real-time communication. To bridge this gap, we propose Content-Promoted Scene Layers (CPSL), a compact 2.5D video representation that brings the perceptual benefits of volumetric video to conventional 2D content. Guided by per-frame depth and content saliency, CPSL decomposes each frame into a small set of geometry-consistent layers equipped with soft alpha bands and an edge-depth cache that jointly preserve occlusion ordering and boundary continuity. These lightweight, 2D-encodable assets enable parallax-corrected novel-view synthesis via depth-weighted warping and front-to-back alpha compositing, bypassing expensive 3D reconstruction. Temporally, CPSL maintains inter-frame coherence using motion-guided propagation and per-layer encoding, supporting real-time playback with standard video codecs. Across multiple benchmarks, CPSL achieves superior perceptual quality and boundary fidelity compared with layer-based and neural-field baselines while reducing storage and rendering cost by several folds. Our approach offer a practical path from 2D video to scalable 2.5D immersive media.
Self-Supervised Compression and Artifact Correction for Streaming Underwater Imaging Sonar
Nov 17, 2025Real-time imaging sonar has become an important tool for underwater monitoring in environments where optical sensing is unreliable. Its broader use is constrained by two coupled challenges: highly limited uplink bandwidth and severe sonar-specific artifacts (speckle, motion blur, reverberation, acoustic shadows) that affect up to 98% of frames. We present SCOPE, a self-supervised framework that jointly performs compression and artifact correction without clean-noise pairs or synthetic assumptions. SCOPE combines (i) Adaptive Codebook Compression (ACC), which learns frequency-encoded latent representations tailored to sonar, with (ii) Frequency-Aware Multiscale Segmentation (FAMS), which decomposes frames into low-frequency structure and sparse high-frequency dynamics while suppressing rapidly fluctuating artifacts. A hedging training strategy further guides frequency-aware learning using low-pass proxy pairs generated without labels. Evaluated on months of in-situ ARIS sonar data, SCOPE achieves a structural similarity index (SSIM) of 0.77, representing a 40% improvement over prior self-supervised denoising baselines, at bitrates down to <= 0.0118 bpp. It reduces uplink bandwidth by more than 80% while improving downstream detection. The system runs in real time, with 3.1 ms encoding on an embedded GPU and 97 ms full multi-layer decoding on the server end. SCOPE has been deployed for months in three Pacific Northwest rivers to support real-time salmon enumeration and environmental monitoring in the wild. Results demonstrate that learning frequency-structured latents enables practical, low-bitrate sonar streaming with preserved signal details under real-world deployment conditions.
Generative AI for Multimedia Communication: Recent Advances, An Information-Theoretic Framework, and Future Opportunities
Aug 23, 2025Recent breakthroughs in generative artificial intelligence (AI) are transforming multimedia communication. This paper systematically reviews key recent advancements across generative AI for multimedia communication, emphasizing transformative models like diffusion and transformers. However, conventional information-theoretic frameworks fail to address semantic fidelity, critical to human perception. We propose an innovative semantic information-theoretic framework, introducing semantic entropy, mutual information, channel capacity, and rate-distortion concepts specifically adapted to multimedia applications. This framework redefines multimedia communication from purely syntactic data transmission to semantic information conveyance. We further highlight future opportunities and critical research directions. We chart a path toward robust, efficient, and semantically meaningful multimedia communication systems by bridging generative AI innovations with information theory. This exploratory paper aims to inspire a semantic-first paradigm shift, offering a fresh perspective with significant implications for future multimedia research.
Generative Flow Networks for Personalized Multimedia Systems: A Case Study on Short Video Feeds
Aug 23, 2025Multimedia systems underpin modern digital interactions, facilitating seamless integration and optimization of resources across diverse multimedia applications. To meet growing personalization demands, multimedia systems must efficiently manage competing resource needs, adaptive content, and user-specific data handling. This paper introduces Generative Flow Networks (GFlowNets, GFNs) as a brave new framework for enabling personalized multimedia systems. By integrating multi-candidate generative modeling with flow-based principles, GFlowNets offer a scalable and flexible solution for enhancing user-specific multimedia experiences. To illustrate the effectiveness of GFlowNets, we focus on short video feeds, a multimedia application characterized by high personalization demands and significant resource constraints, as a case study. Our proposed GFlowNet-based personalized feeds algorithm demonstrates superior performance compared to traditional rule-based and reinforcement learning methods across critical metrics, including video quality, resource utilization efficiency, and delivery cost. Moreover, we propose a unified GFlowNet-based framework generalizable to other multimedia systems, highlighting its adaptability and wide-ranging applicability. These findings underscore the potential of GFlowNets to advance personalized multimedia systems by addressing complex optimization challenges and supporting sophisticated multimedia application scenarios.
Exploring Multimodal Foundation AI and Expert-in-the-Loop for Sustainable Management of Wild Salmon Fisheries in Indigenous Rivers
May 10, 2025


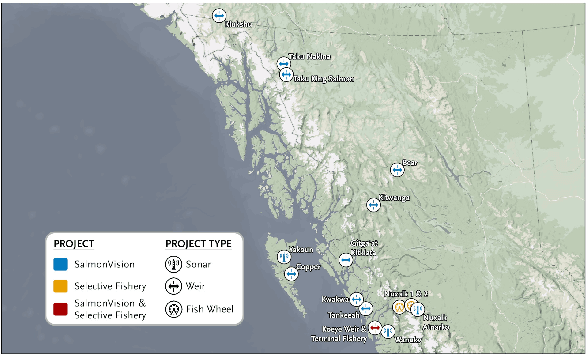
Wild salmon are essential to the ecological, economic, and cultural sustainability of the North Pacific Rim. Yet climate variability, habitat loss, and data limitations in remote ecosystems that lack basic infrastructure support pose significant challenges to effective fisheries management. This project explores the integration of multimodal foundation AI and expert-in-the-loop frameworks to enhance wild salmon monitoring and sustainable fisheries management in Indigenous rivers across Pacific Northwest. By leveraging video and sonar-based monitoring, we develop AI-powered tools for automated species identification, counting, and length measurement, reducing manual effort, expediting delivery of results, and improving decision-making accuracy. Expert validation and active learning frameworks ensure ecological relevance while reducing annotation burdens. To address unique technical and societal challenges, we bring together a cross-domain, interdisciplinary team of university researchers, fisheries biologists, Indigenous stewardship practitioners, government agencies, and conservation organizations. Through these collaborations, our research fosters ethical AI co-development, open data sharing, and culturally informed fisheries management.
Large Language Model (LLM) for Telecommunications: A Comprehensive Survey on Principles, Key Techniques, and Opportunities
May 17, 2024
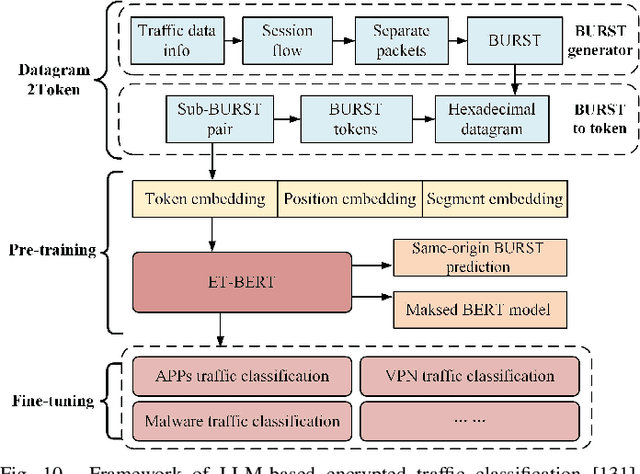
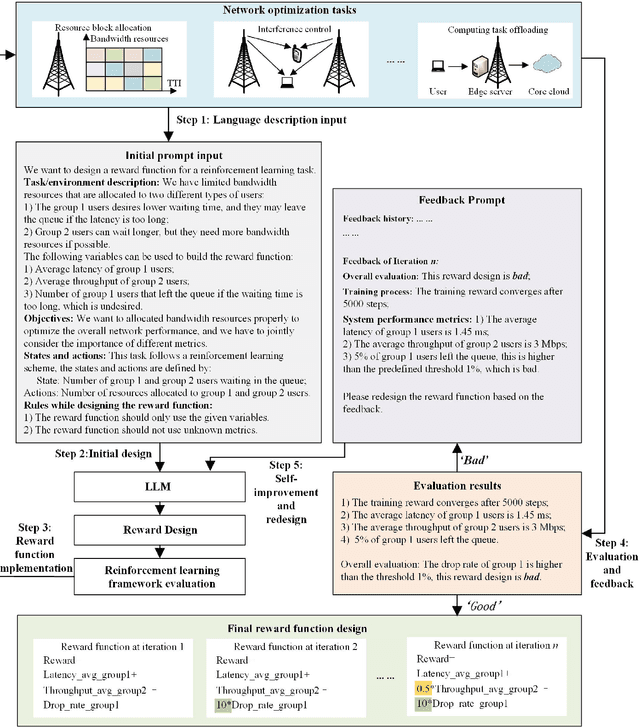
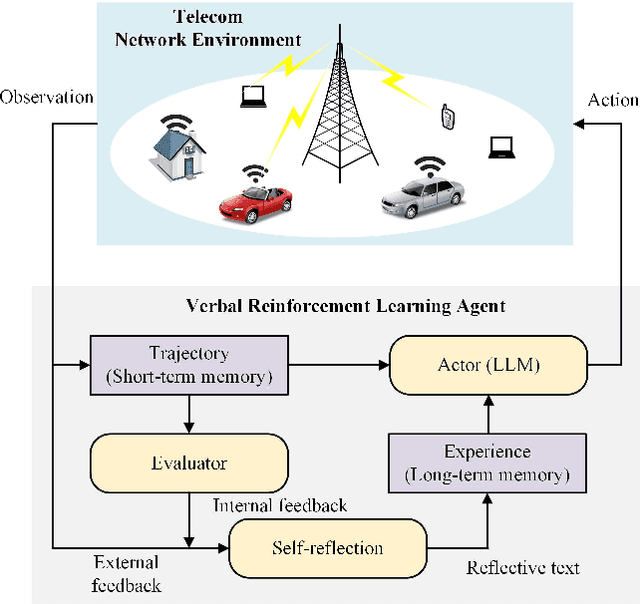
Large language models (LLMs) have received considerable attention recently due to their outstanding comprehension and reasoning capabilities, leading to great progress in many fields. The advancement of LLM techniques also offers promising opportunities to automate many tasks in the telecommunication (telecom) field. After pre-training and fine-tuning, LLMs can perform diverse downstream tasks based on human instructions, paving the way to artificial general intelligence (AGI)-enabled 6G. Given the great potential of LLM technologies, this work aims to provide a comprehensive overview of LLM-enabled telecom networks. In particular, we first present LLM fundamentals, including model architecture, pre-training, fine-tuning, inference and utilization, model evaluation, and telecom deployment. Then, we introduce LLM-enabled key techniques and telecom applications in terms of generation, classification, optimization, and prediction problems. Specifically, the LLM-enabled generation applications include telecom domain knowledge, code, and network configuration generation. After that, the LLM-based classification applications involve network security, text, image, and traffic classification problems. Moreover, multiple LLM-enabled optimization techniques are introduced, such as automated reward function design for reinforcement learning and verbal reinforcement learning. Furthermore, for LLM-aided prediction problems, we discussed time-series prediction models and multi-modality prediction problems for telecom. Finally, we highlight the challenges and identify the future directions of LLM-enabled telecom networks.
From Capture to Display: A Survey on Volumetric Video
Sep 11, 2023Volumetric video, which offers immersive viewing experiences, is gaining increasing prominence. With its six degrees of freedom, it provides viewers with greater immersion and interactivity compared to traditional videos. Despite their potential, volumetric video services poses significant challenges. This survey conducts a comprehensive review of the existing literature on volumetric video. We firstly provide a general framework of volumetric video services, followed by a discussion on prerequisites for volumetric video, encompassing representations, open datasets, and quality assessment metrics. Then we delve into the current methodologies for each stage of the volumetric video service pipeline, detailing capturing, compression, transmission, rendering, and display techniques. Lastly, we explore various applications enabled by this pioneering technology and we present an array of research challenges and opportunities in the domain of volumetric video services. This survey aspires to provide a holistic understanding of this burgeoning field and shed light on potential future research trajectories, aiming to bring the vision of volumetric video to fruition.
FSVVD: A Dataset of Full Scene Volumetric Video
Mar 07, 2023Recent years have witnessed a rapid development of immersive multimedia which bridges the gap between the real world and virtual space. Volumetric videos, as an emerging representative 3D video paradigm that empowers extended reality, stand out to provide unprecedented immersive and interactive video watching experience. Despite the tremendous potential, the research towards 3D volumetric video is still in its infancy, relying on sufficient and complete datasets for further exploration. However, existing related volumetric video datasets mostly only include a single object, lacking details about the scene and the interaction between them. In this paper, we focus on the current most widely used data format, point cloud, and for the first time release a full-scene volumetric video dataset that includes multiple people and their daily activities interacting with the external environments. Comprehensive dataset description and analysis are conducted, with potential usage of this dataset. The dataset and additional tools can be accessed via the following website: https://cuhksz-inml.github.io/full_scene_volumetric_video_dataset/.
SemEval-2020 Task 4: Commonsense Validation and Explanation
Jul 01, 2020



In this paper, we present SemEval-2020 Task 4, Commonsense Validation and Explanation (ComVE), which includes three subtasks, aiming to evaluate whether a system can distinguish a natural language statement that makes sense to human from one that does not, and provide the reasons. Specifically, in our first subtask, the participating systems are required to choose from two natural language statements of similar wording the one that makes sense and the one does not. The second subtask additionally asks a system to select the key reason from three options why a given statement does not make sense. In the third subtask, a participating system needs to generate the reason automatically.