 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompting Wireless Networks: Reinforced In-Context Learning for Power Control
Jun 06, 2025To manage and optimize constantly evolving wireless networks, existing machine learning (ML)- based studies operate as black-box models, leading to increased computational costs during training and a lack of transparency in decision-making, which limits their practical applicability in wireless networks. Motivated by recent advancements in large language model (LLM)-enabled wireless networks, this paper proposes ProWin, a novel framework that leverages reinforced in-context learning to design task-specific demonstration Prompts for Wireless Network optimization, relying on the inference capabilities of LLMs without the need for dedicated model training or finetuning. The task-specific prompts are designed to incorporate natural language descriptions of the task description and formulation, enhancing interpretability and eliminating the need for specialized expertise in network optimization. We further propose a reinforced in-context learning scheme that incorporates a set of advisable examples into task-specific prompts, wherein informative examples capturing historical environment states and decisions are adaptively selected to guide current decision-making. Evaluations on a case study of base station power control showcases that the proposed ProWin outperforms reinforcement learning (RL)-based methods, highlighting the potential for next-generation future wireless network optimization.
Large Language Model (LLM) for Telecommunications: A Comprehensive Survey on Principles, Key Techniques, and Opportunities
May 17, 2024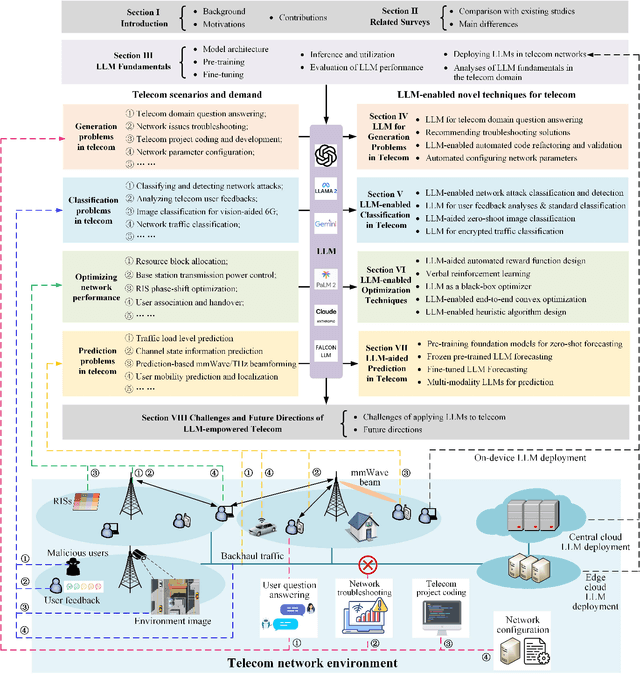
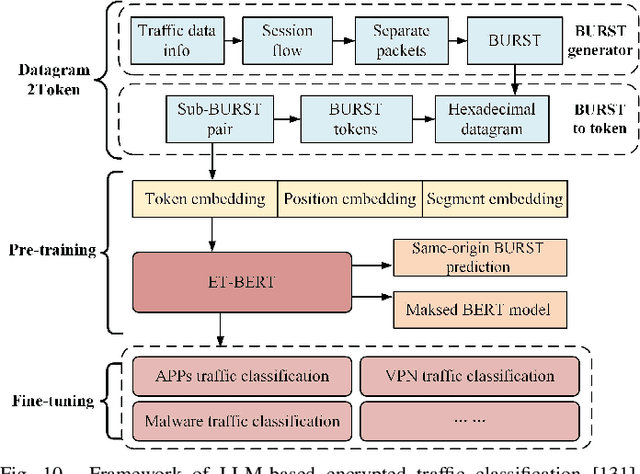
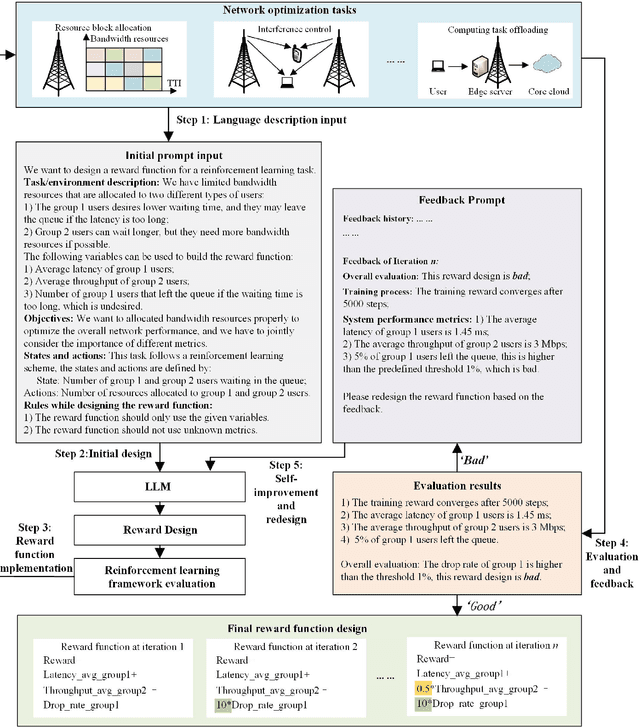
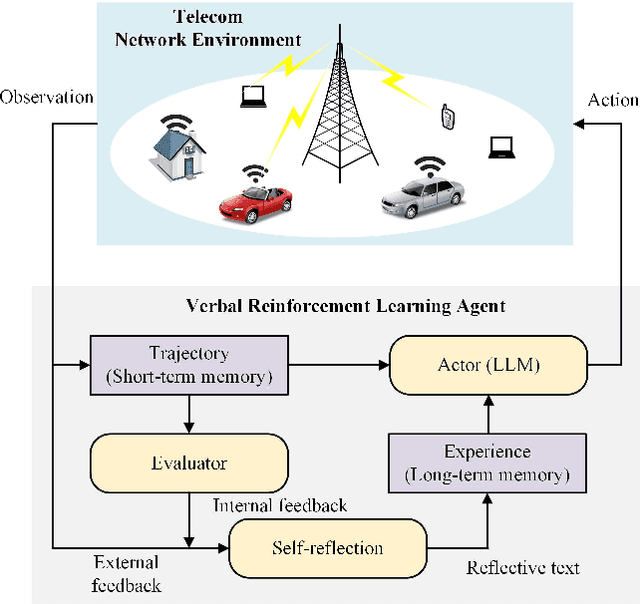
Large language models (LLMs) have received considerable attention recently due to their outstanding comprehension and reasoning capabilities, leading to great progress in many fields. The advancement of LLM techniques also offers promising opportunities to automate many tasks in the telecommunication (telecom) field. After pre-training and fine-tuning, LLMs can perform diverse downstream tasks based on human instructions, paving the way to artificial general intelligence (AGI)-enabled 6G. Given the great potential of LLM technologies, this work aims to provide a comprehensive overview of LLM-enabled telecom networks. In particular, we first present LLM fundamentals, including model architecture, pre-training, fine-tuning, inference and utilization, model evaluation, and telecom deployment. Then, we introduce LLM-enabled key techniques and telecom applications in terms of generation, classification, optimization, and prediction problems. Specifically, the LLM-enabled generation applications include telecom domain knowledge, code, and network configuration generation. After that, the LLM-based classification applications involve network security, text, image, and traffic classification problems. Moreover, multiple LLM-enabled optimization techniques are introduced, such as automated reward function design for reinforcement learning and verbal reinforcement learning. Furthermore, for LLM-aided prediction problems, we discussed time-series prediction models and multi-modality prediction problems for telecom. Finally, we highlight the challenges and identify the future directions of LLM-enabled telecom networks.
Less or More From Teacher: Exploiting Trilateral Geometry For Knowledge Distillation
Jan 01, 2024



Knowledge distillation aims to train a compact student network using soft supervision from a larger teacher network and hard supervision from ground truths. However, determining an optimal knowledge fusion ratio that balances these supervisory signals remains challenging. Prior methods generally resort to a constant or heuristic-based fusion ratio, which often falls short of a proper balance. In this study, we introduce a novel adaptive method for learning a sample-wise knowledge fusion ratio, exploiting both the correctness of teacher and student, as well as how well the student mimics the teacher on each sample. Our method naturally leads to the intra-sample trilateral geometric relations among the student prediction ($S$), teacher prediction ($T$), and ground truth ($G$). To counterbalance the impact of outliers, we further extend to the inter-sample relations, incorporating the teacher's global average prediction $\bar{T}$ for samples within the same class. A simple neural network then learns the implicit mapping from the intra- and inter-sample relations to an adaptive, sample-wise knowledge fusion ratio in a bilevel-optimization manner. Our approach provides a simple, practical, and adaptable solution for knowledge distillation that can be employed across various architectures and model sizes. Extensive experiments demonstrate consistent improvements over other loss re-weighting methods on image classification, attack detection, and click-through rate prediction.
Teacher-Student Architecture for Knowledge Distillation: A Survey
Aug 08, 2023



Although Deep neural networks (DNNs) have shown a strong capacity to solve large-scale problems in many areas, such DNNs are hard to be deployed in real-world systems due to their voluminous parameters. To tackle this issue, Teacher-Student architectures were proposed, where simple student networks with a few parameters can achieve comparable performance to deep teacher networks with many parameters. Recently, Teacher-Student architectures have been effectively and widely embraced on various knowledge distillation (KD) objectives, including knowledge compression, knowledge expansion, knowledge adaptation, and knowledge enhancement. With the help of Teacher-Student architectures, current studies are able to achieve multiple distillation objectives through lightweight and generalized student networks. Different from existing KD surveys that primarily focus on knowledge compression, this survey first explores Teacher-Student architectures across multiple distillation objectives. This survey presents an introduction to various knowledge representations and their corresponding optimization objectives. Additionally, we provide a systematic overview of Teacher-Student architectures with representative learning algorithms and effective distillation schemes. This survey also summarizes recent applications of Teacher-Student architectures across multiple purposes, including classification, recognition, generation, ranking, and regression. Lastly, potential research directions in KD are investigated, focusing on architecture design, knowledge quality, and theoretical studies of regression-based learning, respectively. Through this comprehensive survey, industry practitioners and the academic community can gain valuable insights and guidelines for effectively designing, learning, and applying Teacher-Student architectures on various distillation objectives.
Phase Matching for Out-of-Distribution Generalization
Aug 07, 2023



The Fourier transform, serving as an explicit decomposition method for visual signals, has been employed to explain the out-of-distribution generalization behaviors of Convolutional Neural Networks (CNNs). Previous studies have indicated that the amplitude spectrum is susceptible to the disturbance caused by distribution shifts. On the other hand, the phase spectrum preserves highly-structured spatial information, which is crucial for robust visual representation learning. However, the spatial relationships of phase spectrum remain unexplored in previous researches. In this paper, we aim to clarify the relationships between Domain Generalization (DG) and the frequency components, and explore the spatial relationships of the phase spectrum. Specifically, we first introduce a Fourier-based structural causal model which interprets the phase spectrum as semi-causal factors and the amplitude spectrum as non-causal factors. Then, we propose Phase Matching (PhaMa) to address DG problems. Our method introduces perturbations on the amplitude spectrum and establishes spatial relationships to match the phase components. Through experiments on multiple benchmarks, we demonstrate that our proposed method achieves state-of-the-art performance in domain generalization and out-of-distribution robustness tasks.
Teacher-Student Architecture for Knowledge Learning: A Survey
Oct 28, 2022
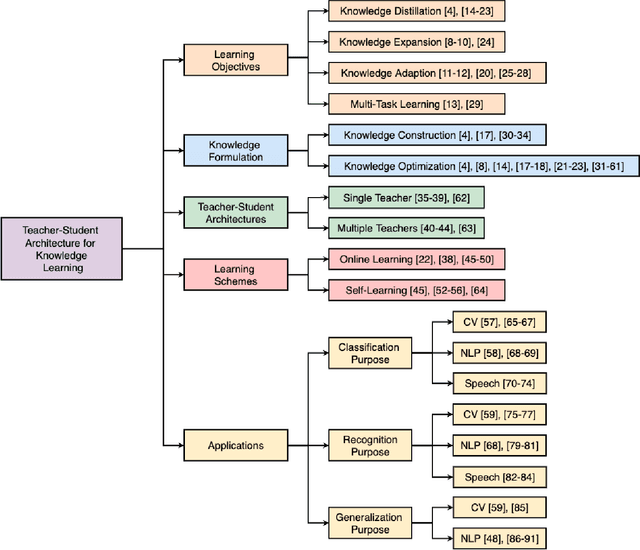
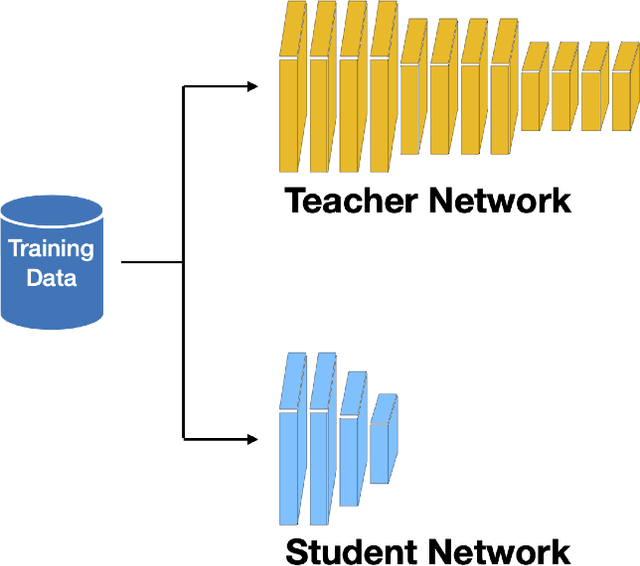
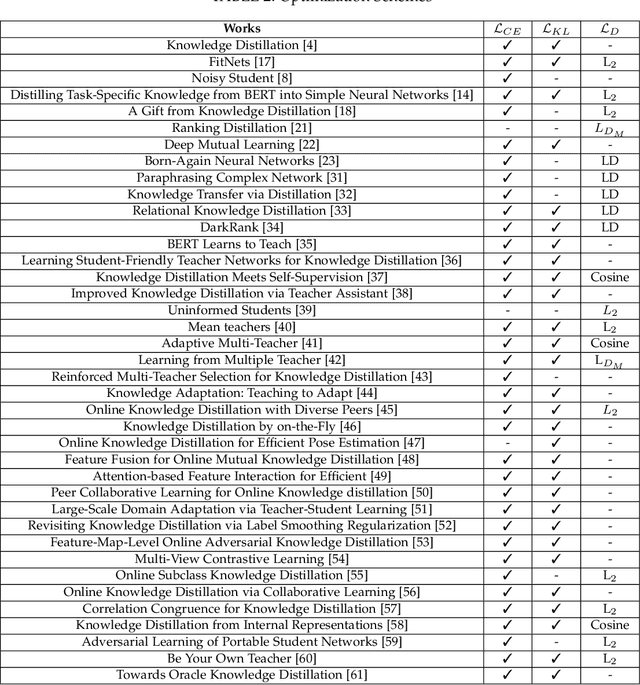
Although Deep Neural Networks (DNNs) have shown a strong capacity to solve large-scale problems in many areas, such DNNs with voluminous parameters are hard to be deployed in a real-time system. To tackle this issue, Teacher-Student architectures were first utilized in knowledge distillation, where simple student networks can achieve comparable performance to deep teacher networks. Recently, Teacher-Student architectures have been effectively and widely embraced on various knowledge learning objectives, including knowledge distillation, knowledge expansion, knowledge adaption, and multi-task learning. With the help of Teacher-Student architectures, current studies are able to achieve multiple knowledge-learning objectives through lightweight and effective student networks. Different from the existing knowledge distillation surveys, this survey detailedly discusses Teacher-Student architectures with multiple knowledge learning objectives. In addition, we systematically introduce the knowledge construction and optimization process during the knowledge learning and then analyze various Teacher-Student architectures and effective learning schemes that have been leveraged to learn representative and robust knowledge. This paper also summarizes the latest applications of Teacher-Student architectures based on different purposes (i.e., classification, recognition, and generation). Finally, the potential research directions of knowledge learning are investigated on the Teacher-Student architecture design, the quality of knowledge, and the theoretical studies of regression-based learning, respectively. With this comprehensive survey, both industry practitioners and the academic community can learn insightful guidelines about Teacher-Student architectures on multiple knowledge learning objectives.
Encoder-Decoder Architecture for Supervised Dynamic Graph Learning: A Survey
Mar 27, 2022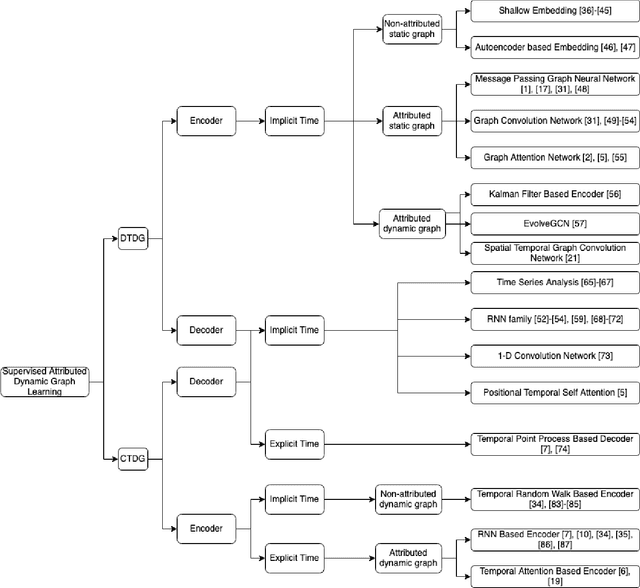

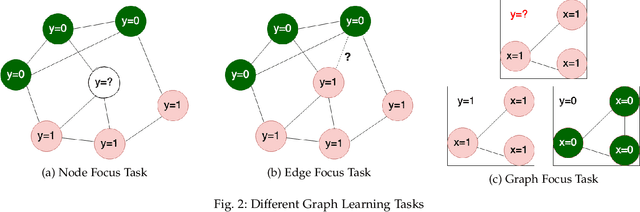
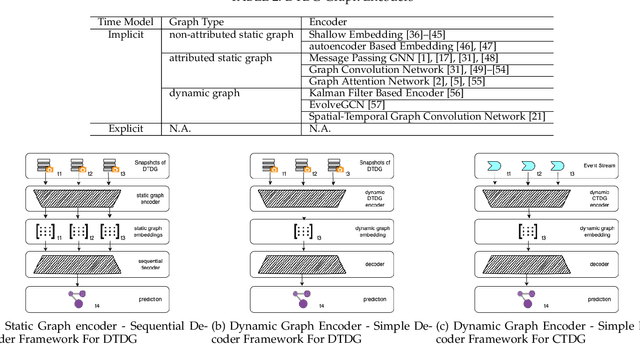
In recent years, the prevalent online services generate a sheer volume of user activity data. Service providers collect these data in order to perform client behavior analysis, and offer better and more customized services. Majority of these data can be modeled and stored as graph, such as the social graph in Facebook, user-video interaction graph in Youtube. These graphs need to evolve over time to capture the dynamics in the real world, leading to the invention of dynamic graphs. However, the temporal information embedded in the dynamic graphs brings new challenges in analyzing and deploying them. Events staleness, temporal information learning and explicit time dimension usage are some example challenges in dynamic graph learning. In order to offer a convenient reference to both the industry and academia, this survey presents the Three Stages Recurrent Temporal Learning Framework based on dynamic graph evolution theories, so as to interpret the learning of temporal information with a generalized framework. Under this framework, this survey categories and reviews different learnable encoder-decoder architectures for supervised dynamic graph learning. We believe that this survey could supply useful guidelines to researchers and engineers in finding suitable graph structures for their dynamic learning tasks.