 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing User Profiles via Contextual Bandits for Retrieval-Augmented LLM Personalization
Jan 17, 2026Large Language Models (LLMs) excel at general-purpose tasks, yet adapting their responses to individual users remains challenging. Retrieval augmentation provides a lightweight alternative to fine-tuning by conditioning LLMs on user history records, and existing approaches typically select these records based on semantic relevance. We argue that relevance serves as an unreliable proxy for utility: a record may be semantically similar to a query yet fail to improve generation quality or even degrade it due to redundancy or conflicting information. To bridge this gap, we propose PURPLE, a contextual bandit framework that oPtimizes UseR Profiles for Llm pErsonalization. In contrast to a greedy selection of the most relevant records, PURPLE treats profile construction as a set generation process and utilizes a Plackett-Luce ranking model to capture complex inter-record dependencies. By training with dense feedback provided by the likelihood of the reference response, our method aligns retrieval directly with generation quality. Extensive experiments on nine personalization tasks demonstrate that PURPLE consistently outperforms strong heuristic and retrieval-augmented baselines in both effectiveness and efficiency, establishing a principled and scalable solution for optimizing user profiles.
Exploring Test-time Scaling via Prediction Merging on Large-Scale Recommendation
Dec 08, 2025Inspired by the success of language models (LM), scaling up deep learning recommendation systems (DLRS) has become a recent trend in the community. All previous methods tend to scale up the model parameters during training time. However, how to efficiently utilize and scale up computational resources during test time remains underexplored, which can prove to be a scaling-efficient approach and bring orthogonal improvements in LM domains. The key point in applying test-time scaling to DLRS lies in effectively generating diverse yet meaningful outputs for the same instance. We propose two ways: One is to explore the heterogeneity of different model architectures. The other is to utilize the randomness of model initialization under a homogeneous architecture. The evaluation is conducted across eight models, including both classic and SOTA models, on three benchmarks. Sufficient evidence proves the effectiveness of both solutions. We further prove that under the same inference budget, test-time scaling can outperform parameter scaling. Our test-time scaling can also be seamlessly accelerated with the increase in parallel servers when deployed online, without affecting the inference time on the user side. Code is available.
Timing is important: Risk-aware Fund Allocation based on Time-Series Forecasting
May 30, 2025Fund allocation has been an increasingly important problem in the financial domain. In reality, we aim to allocate the funds to buy certain assets within a certain future period. Naive solutions such as prediction-only or Predict-then-Optimize approaches suffer from goal mismatch. Additionally, the introduction of the SOTA time series forecasting model inevitably introduces additional uncertainty in the predicted result. To solve both problems mentioned above, we introduce a Risk-aware Time-Series Predict-and-Allocate (RTS-PnO) framework, which holds no prior assumption on the forecasting models. Such a framework contains three features: (i) end-to-end training with objective alignment measurement, (ii) adaptive forecasting uncertainty calibration, and (iii) agnostic towards forecasting models. The evaluation of RTS-PnO is conducted over both online and offline experiments. For offline experiments, eight datasets from three categories of financial applications are used: Currency, Stock, and Cryptos. RTS-PnO consistently outperforms other competitive baselines. The online experiment is conducted on the Cross-Border Payment business at FiT, Tencent, and an 8.4\% decrease in regret is witnessed when compared with the product-line approach. The code for the offline experiment is available at https://github.com/fuyuanlyu/RTS-PnO.
What, How, Where, and How Well? A Survey on Test-Time Scaling in Large Language Models
Mar 31, 2025As enthusiasm for scaling computation (data and parameters) in the pretraining era gradually diminished, test-time scaling (TTS), also referred to as ``test-time computing'' has emerged as a prominent research focus. Recent studies demonstrate that TTS can further elicit the problem-solving capabilities of large language models (LLMs), enabling significant breakthroughs not only in specialized reasoning tasks, such as mathematics and coding, but also in general tasks like open-ended Q&A. However, despite the explosion of recent efforts in this area, there remains an urgent need for a comprehensive survey offering a systemic understanding. To fill this gap, we propose a unified, multidimensional framework structured along four core dimensions of TTS research: what to scale, how to scale, where to scale, and how well to scale. Building upon this taxonomy, we conduct an extensive review of methods, application scenarios, and assessment aspects, and present an organized decomposition that highlights the unique functional roles of individual techniques within the broader TTS landscape. From this analysis, we distill the major developmental trajectories of TTS to date and offer hands-on guidelines for practical deployment. Furthermore, we identify several open challenges and offer insights into promising future directions, including further scaling, clarifying the functional essence of techniques, generalizing to more tasks, and more attributions.
A Predict-Then-Optimize Customer Allocation Framework for Online Fund Recommendation
Mar 05, 2025With the rapid growth of online investment platforms, funds can be distributed to individual customers online. The central issue is to match funds with potential customers under constraints. Most mainstream platforms adopt the recommendation formulation to tackle the problem. However, the traditional recommendation regime has its inherent drawbacks when applying the fund-matching problem with multiple constraints. In this paper, we model the fund matching under the allocation formulation. We design PTOFA, a Predict-Then-Optimize Fund Allocation framework. This data-driven framework consists of two stages, i.e., prediction and optimization, which aim to predict expected revenue based on customer behavior and optimize the impression allocation to achieve the maximum revenue under the necessary constraints, respectively. Extensive experiments on real-world datasets from an industrial online investment platform validate the effectiveness and efficiency of our solution. Additionally, the online A/B tests demonstrate PTOFA's effectiveness in the real-world fund recommendation scenario.
Crowd Comparative Reasoning: Unlocking Comprehensive Evaluations for LLM-as-a-Judge
Feb 18, 2025



LLM-as-a-Judge, which generates chain-of-thought (CoT) judgments, has become a widely adopted auto-evaluation method. However, its reliability is compromised by the CoT reasoning's inability to capture comprehensive and deeper details, often leading to incomplete outcomes. Existing methods mainly rely on majority voting or criteria expansion, which is insufficient to address the limitation in CoT. We propose Crowd-based Comparative Evaluation, which introduces additional crowd responses to compare with the candidate responses, thereby exposing deeper and more comprehensive details within the candidate responses. This process effectively guides LLM-as-a-Judge to provide a more detailed CoT judgment. Extensive experiments demonstrate that our approach enhances evaluation reliability, achieving an average accuracy gain of 6.7% across five benchmarks. Moreover, our method produces higher-quality CoTs that facilitate judge distillation and exhibit superior performance in rejection sampling for supervised fine-tuning (SFT), referred to as crowd rejection sampling, thereby enabling more efficient SFT. Our analysis confirms that CoTs generated by ours are more comprehensive and of higher quality, and evaluation accuracy improves as inference scales.
Fusion Matters: Learning Fusion in Deep Click-through Rate Prediction Models
Nov 24, 2024



The evolution of previous Click-Through Rate (CTR) models has mainly been driven by proposing complex components, whether shallow or deep, that are adept at modeling feature interactions. However, there has been less focus on improving fusion design. Instead, two naive solutions, stacked and parallel fusion, are commonly used. Both solutions rely on pre-determined fusion connections and fixed fusion operations. It has been repetitively observed that changes in fusion design may result in different performances, highlighting the critical role that fusion plays in CTR models. While there have been attempts to refine these basic fusion strategies, these efforts have often been constrained to specific settings or dependent on specific components. Neural architecture search has also been introduced to partially deal with fusion design, but it comes with limitations. The complexity of the search space can lead to inefficient and ineffective results. To bridge this gap, we introduce OptFusion, a method that automates the learning of fusion, encompassing both the connection learning and the operation selection. We have proposed a one-shot learning algorithm tackling these tasks concurrently. Our experiments are conducted over three large-scale datasets. Extensive experiments prove both the effectiveness and efficiency of OptFusion in improving CTR model performance. Our code implementation is available here\url{https://github.com/kexin-kxzhang/OptFusion}.
Comprehending Knowledge Graphs with Large Language Models for Recommender Systems
Oct 16, 2024Recently, the introduction of knowledge graphs (KGs) has significantly advanced recommender systems by facilitating the discovery of potential associations between items. However, existing methods still face several limitations. First, most KGs suffer from missing facts or limited scopes. This can lead to biased knowledge representations, thereby constraining the model's performance. Second, existing methods typically convert textual information into IDs, resulting in the loss of natural semantic connections between different items. Third, existing methods struggle to capture high-order relationships in global KGs due to their inefficient layer-by-layer information propagation mechanisms, which are prone to introducing significant noise. To address these limitations, we propose a novel method called CoLaKG, which leverages large language models (LLMs) for knowledge-aware recommendation. The extensive world knowledge and remarkable reasoning capabilities of LLMs enable them to supplement KGs. Additionally, the strong text comprehension abilities of LLMs allow for a better understanding of semantic information. Based on this, we first extract subgraphs centered on each item from the KG and convert them into textual inputs for the LLM. The LLM then outputs its comprehension of these item-centered subgraphs, which are subsequently transformed into semantic embeddings. Furthermore, to utilize the global information of the KG, we construct an item-item graph using these semantic embeddings, which can directly capture higher-order associations between items. Both the semantic embeddings and the structural information from the item-item graph are effectively integrated into the recommendation model through our designed representation alignment and neighbor augmentation modules. Extensive experiments on four real-world datasets demonstrate the superiority of our method.
RevisEval: Improving LLM-as-a-Judge via Response-Adapted References
Oct 07, 2024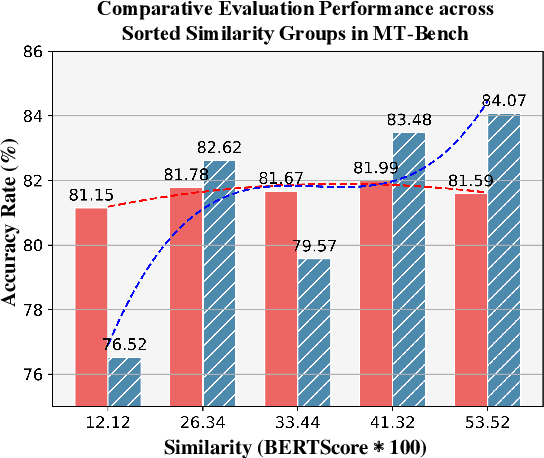
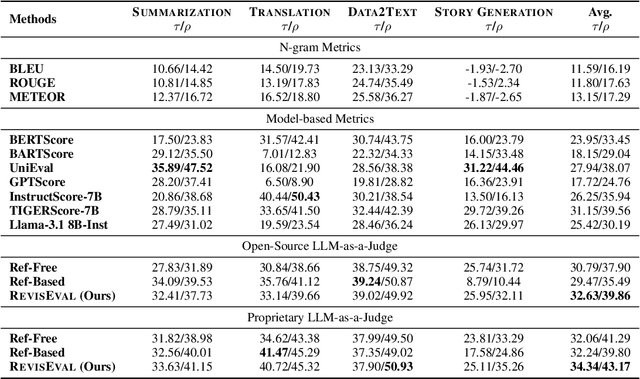
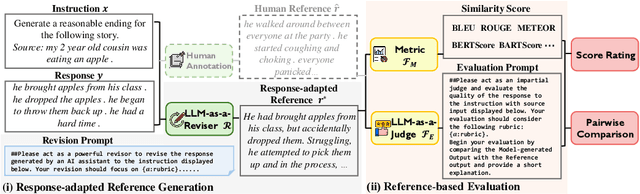
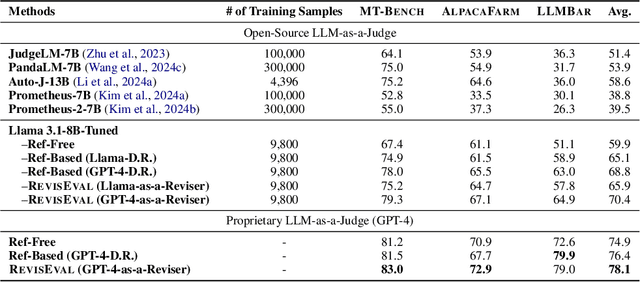
With significant efforts in recent studies, LLM-as-a-Judge has become a cost-effective alternative to human evaluation for assessing the text generation quality in a wide range of tasks. However, there still remains a reliability gap between LLM-as-a-Judge and human evaluation. One important reason is the lack of guided oracles in the evaluation process. Motivated by the role of reference pervasively used in classic text evaluation, we introduce RevisEval, a novel text generation evaluation paradigm via the response-adapted references. RevisEval is driven by the key observation that an ideal reference should maintain the necessary relevance to the response to be evaluated. Specifically, RevisEval leverages the text revision capabilities of large language models (LLMs) to adaptively revise the response, then treat the revised text as the reference (response-adapted reference) for the subsequent evaluation. Extensive experiments demonstrate that RevisEval outperforms traditional reference-free and reference-based evaluation paradigms that use LLM-as-a-Judge across NLG tasks and open-ended instruction-following tasks. More importantly, our response-adapted references can further boost the classical text metrics, e.g., BLEU and BERTScore, compared to traditional references and even rival the LLM-as-a-Judge. A detailed analysis is also conducted to confirm RevisEval's effectiveness in bias reduction, the impact of inference cost, and reference relevance.
Mixed-Precision Embeddings for Large-Scale Recommendation Models
Sep 30, 2024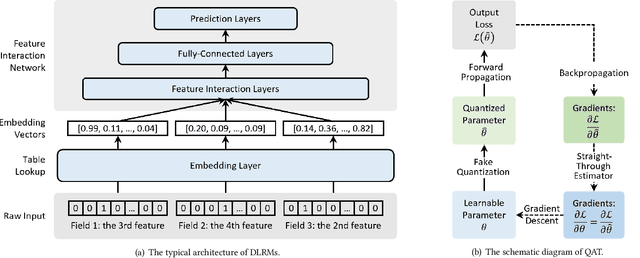
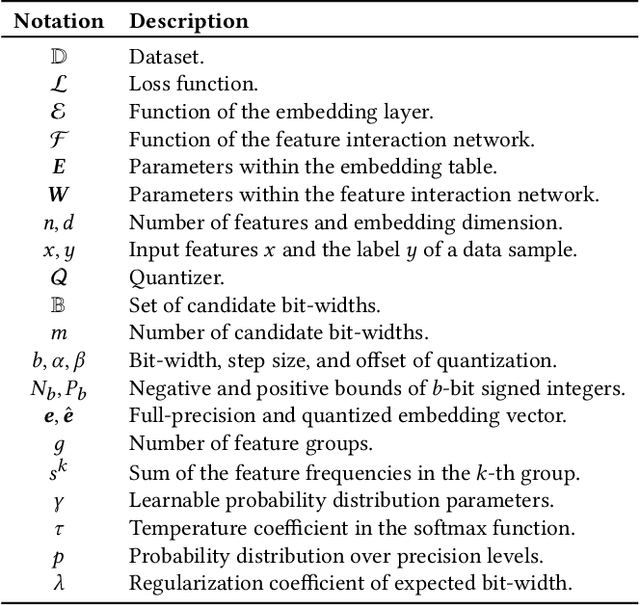
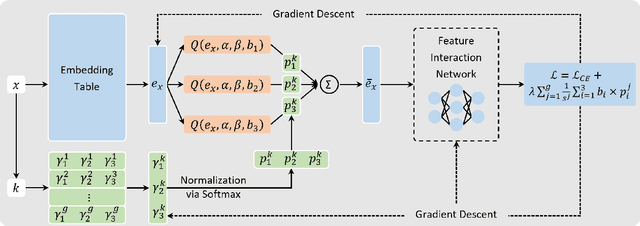
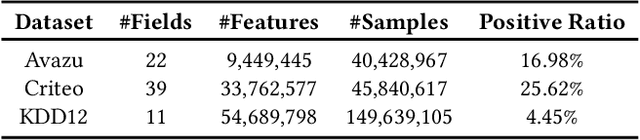
Embedding techniques have become essential components of large databases in the deep learning era. By encoding discrete entities, such as words, items, or graph nodes, into continuous vector spaces, embeddings facilitate more efficient storage, retrieval, and processing in large databases. Especially in the domain of recommender systems, millions of categorical features are encoded as unique embedding vectors, which facilitates the modeling of similarities and interactions among features. However, numerous embedding vectors can result in significant storage overhead. In this paper, we aim to compress the embedding table through quantization techniques. Given that features vary in importance levels, we seek to identify an appropriate precision for each feature to balance model accuracy and memory usage. To this end, we propose a novel embedding compression method, termed Mixed-Precision Embeddings (MPE). Specifically, to reduce the size of the search space, we first group features by frequency and then search precision for each feature group. MPE further learns the probability distribution over precision levels for each feature group, which can be used to identify the most suitable precision with a specially designed sampling strategy. Extensive experiments on three public datasets demonstrate that MPE significantly outperforms existing embedding compression methods. Remarkably, MPE achieves about 200x compression on the Criteo dataset without comprising the prediction accuracy.