 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisEval: Improving LLM-as-a-Judge via Response-Adapted References
Paper and Code
Oct 07, 2024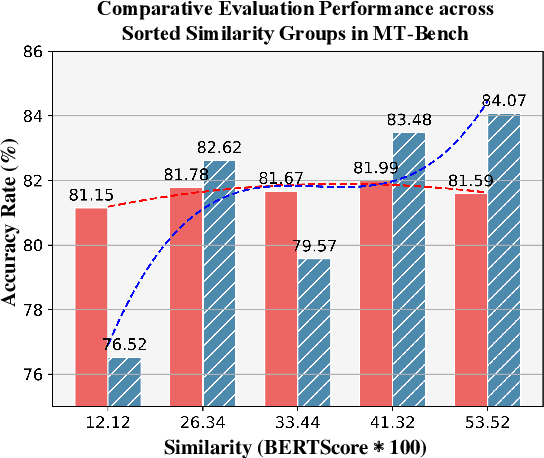
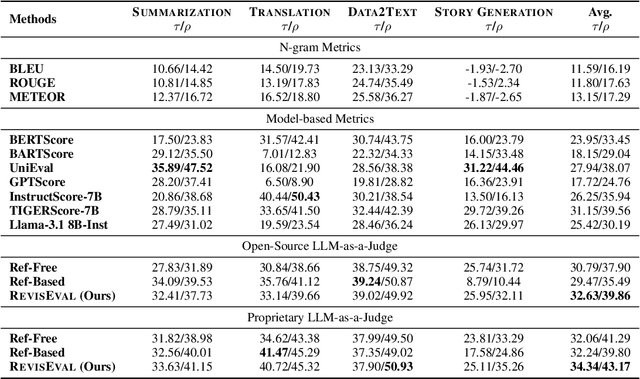
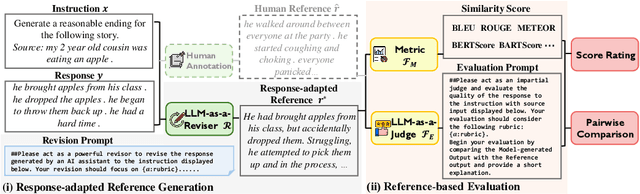
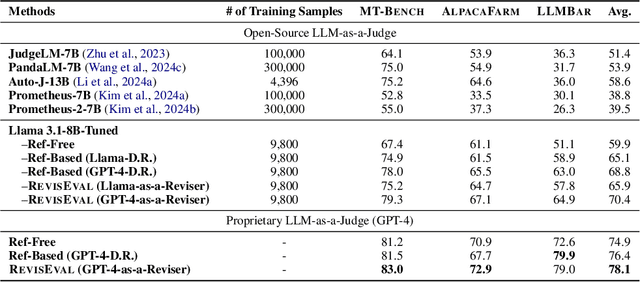
With significant efforts in recent studies, LLM-as-a-Judge has become a cost-effective alternative to human evaluation for assessing the text generation quality in a wide range of tasks. However, there still remains a reliability gap between LLM-as-a-Judge and human evaluation. One important reason is the lack of guided oracles in the evaluation process. Motivated by the role of reference pervasively used in classic text evaluation, we introduce RevisEval, a novel text generation evaluation paradigm via the response-adapted references. RevisEval is driven by the key observation that an ideal reference should maintain the necessary relevance to the response to be evaluated. Specifically, RevisEval leverages the text revision capabilities of large language models (LLMs) to adaptively revise the response, then treat the revised text as the reference (response-adapted reference) for the subsequent evaluation. Extensive experiments demonstrate that RevisEval outperforms traditional reference-free and reference-based evaluation paradigms that use LLM-as-a-Judge across NLG tasks and open-ended instruction-following tasks. More importantly, our response-adapted references can further boost the classical text metrics, e.g., BLEU and BERTScore, compared to traditional references and even rival the LLM-as-a-Judge. A detailed analysis is also conducted to confirm RevisEval's effectiveness in bias reduction, the impact of inference cost, and reference relevance.