 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed-Precision Embeddings for Large-Scale Recommendation Models
Paper and Code
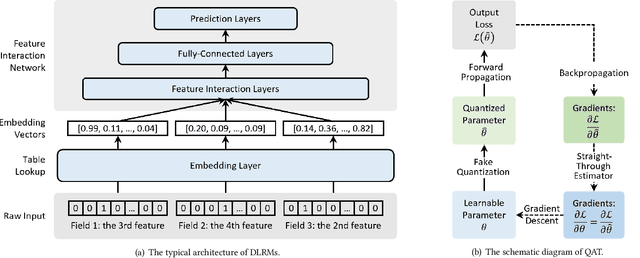
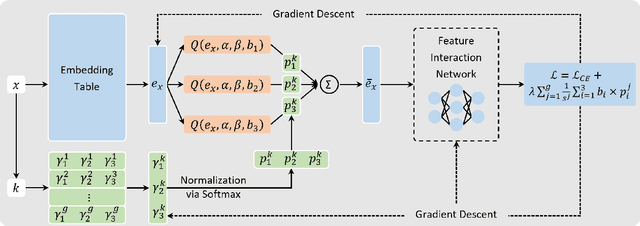
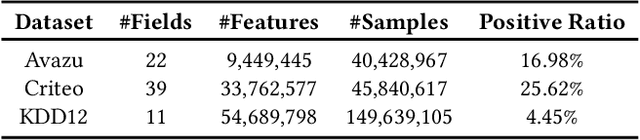
Embedding techniques have become essential components of large databases in the deep learning era. By encoding discrete entities, such as words, items, or graph nodes, into continuous vector spaces, embeddings facilitate more efficient storage, retrieval, and processing in large databases. Especially in the domain of recommender systems, millions of categorical features are encoded as unique embedding vectors, which facilitates the modeling of similarities and interactions among features. However, numerous embedding vectors can result in significant storage overhead. In this paper, we aim to compress the embedding table through quantization techniques. Given that features vary in importance levels, we seek to identify an appropriate precision for each feature to balance model accuracy and memory usage. To this end, we propose a novel embedding compression method, termed Mixed-Precision Embeddings (MPE). Specifically, to reduce the size of the search space, we first group features by frequency and then search precision for each feature group. MPE further learns the probability distribution over precision levels for each feature group, which can be used to identify the most suitable precision with a specially designed sampling strategy. Extensive experiments on three public datasets demonstrate that MPE significantly outperforms existing embedding compression methods. Remarkably, MPE achieves about 200x compression on the Criteo dataset without comprising the prediction accuracy.