 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooking Farther with Confidence: Uncertainty-Guided Future Learning for Sequential Recommendation
May 27, 2026Sequential recommendation effectively models dynamic user interests but continues to face challenges related to data sparsity. While self-supervised learning has alleviated this issue to some extent, most existing methods focus exclusively on immediate next-item prediction during training, thereby neglecting the rich information embedded in longer-term future interactions. Although a few studies have explored the utilization of future data, existing attempts typically apply future supervision signals with uniform intensity across all samples, which may lead to suboptimal solutions. In this paper, we propose an adaptive future learning framework, UFRec, which encourages the model to look further ahead when it is confident in the current state, while focusing on the immediate task when it is uncertain. Specifically, UFRec incorporates an Uncertainty-Guided Future Supervision module that dynamically modulates the weight of multi-step future supervision based on the model's confidence in the primary next-item prediction task. Furthermore, we complement step-wise future supervision with a Future-Aware Contrastive Learning module that treats the future trajectory as a holistic entity. Notably, both auxiliary modules are utilized exclusively during training and incur no inference overhead. Extensive experiments on four benchmark datasets demonstrate that our method significantly outperforms state-of-the-art approaches by effectively leveraging future data.
Retrieve-then-Adapt: Retrieval-Augmented Test-Time Adaptation for Sequential Recommendation
Apr 07, 2026The sequential recommendation (SR) task aims to predict the next item based on users' historical interaction sequences. Typically trained on historical data, SR models often struggle to adapt to real-time preference shifts during inference due to challenges posed by distributional divergence and parameterized constraints. Existing approaches to address this issue include test-time training, test-time augmentation, and retrieval-augmented fine-tuning. However, these methods either introduce significant computational overhead, rely on random augmentation strategies, or require a carefully designed two-stage training paradigm. In this paper, we argue that the key to effective test-time adaptation lies in achieving both effective augmentation and efficient adaptation. To this end, we propose Retrieve-then-Adapt (ReAd), a novel framework that dynamically adapts a deployed SR model to the test distribution through retrieved user preference signals. Specifically, given a trained SR model, ReAd first retrieves collaboratively similar items for a test user from a constructed collaborative memory database. A lightweight retrieval learning module then integrates these items into an informative augmentation embedding that captures both collaborative signals and prediction-refinement cues. Finally, the initial SR prediction is refined via a fusion mechanism that incorporates this embedding. Extensive experiments across five benchmark datasets demonstrate that ReAd consistently outperforms existing SR methods.
From Token to Item: Enhancing Large Language Models for Recommendation via Item-aware Attention Mechanism
Mar 20, 2026Large Language Models (LLMs) have recently gained increasing attention in the field of recommendation. Existing LLM-based methods typically represent items as token sequences, and apply attention layers on these tokens to generate recommendations. However, by inheriting the standard attention mechanism, these methods focus on modeling token-level relations. This token-centric focus overlooks the item as the fundamental unit of recommendation, preventing existing methods from effectively capturing collaborative relations at the item level. In this work, we revisit the role of tokens in LLM-driven recommendation and categorize their relations into two types: (1) intra-item token relations, which present the content semantics of an item, e.g., name, color, and size; and (2) inter-item token relations, which encode collaborative relations across items. Building on these insights, we propose a novel framework with an item-aware attention mechanism (IAM) to enhance LLMs for recommendation. Specifically, IAM devises two complementary attention layers: (1) an intra-item attention layer, which restricts attention to tokens within the same item, modeling item content semantics; and (2) an inter-item attention layer, which attends exclusively to token relations across items, capturing item collaborative relations. Through this stacked design, IAM explicitly emphasizes items as the fundamental units in recommendation, enabling LLMs to effectively exploit item-level collaborative relations. Extensive experiments on several public datasets demonstrate the effectiveness of IAM in enhancing LLMs for personalized recommendation.
Have We Really Understood Collaborative Information? An Empirical Investigation
Nov 10, 2025Collaborative information serves as the cornerstone of recommender systems which typically focus on capturing it from user-item interactions to deliver personalized services. However, current understanding of this crucial resource remains limited. Specifically, a quantitative definition of collaborative information is missing, its manifestation within user-item interactions remains unclear, and its impact on recommendation performance is largely unknown. To bridge this gap, this work conducts a systematic investigation of collaborative information. We begin by clarifying collaborative information in terms of item co-occurrence patterns, identifying its main characteristics, and presenting a quantitative definition. We then estimate the distribution of collaborative information from several aspects, shedding light on how collaborative information is structured in practice. Furthermore, we evaluate the impact of collaborative information on the performance of various recommendation algorithms. Finally, we highlight challenges in effectively capturing collaborative information and outlook promising directions for future research. By establishing an empirical framework, we uncover many insightful observations that advance our understanding of collaborative information and offer valuable guidelines for developing more effective recommender systems.
Beyond Higher Rank: Token-wise Input-Output Projections for Efficient Low-Rank Adaptation
Oct 27, 2025



Low-rank adaptation (LoRA) is a parameter-efficient fine-tuning (PEFT) method widely used in large language models (LLMs). LoRA essentially describes the projection of an input space into a low-dimensional output space, with the dimensionality determined by the LoRA rank. In standard LoRA, all input tokens share the same weights and undergo an identical input-output projection. This limits LoRA's ability to capture token-specific information due to the inherent semantic differences among tokens. To address this limitation, we propose Token-wise Projected Low-Rank Adaptation (TopLoRA), which dynamically adjusts LoRA weights according to the input token, thereby learning token-wise input-output projections in an end-to-end manner. Formally, the weights of TopLoRA can be expressed as $B\Sigma_X A$, where $A$ and $B$ are low-rank matrices (as in standard LoRA), and $\Sigma_X$ is a diagonal matrix generated from each input token $X$. Notably, TopLoRA does not increase the rank of LoRA weights but achieves more granular adaptation by learning token-wise LoRA weights (i.e., token-wise input-output projections). Extensive experiments across multiple models and datasets demonstrate that TopLoRA consistently outperforms LoRA and its variants. The code is available at https://github.com/Leopold1423/toplora-neurips25.
Who Stole Your Data? A Method for Detecting Unauthorized RAG Theft
Oct 09, 2025Retrieval-augmented generation (RAG) enhances Large Language Models (LLMs) by mitigating hallucinations and outdated information issues, yet simultaneously facilitates unauthorized data appropriation at scale. This paper addresses this challenge through two key contributions. First, we introduce RPD, a novel dataset specifically designed for RAG plagiarism detection that encompasses diverse professional domains and writing styles, overcoming limitations in existing resources. Second, we develop a dual-layered watermarking system that embeds protection at both semantic and lexical levels, complemented by an interrogator-detective framework that employs statistical hypothesis testing on accumulated evidence. Extensive experimentation demonstrates our approach's effectiveness across varying query volumes, defense prompts, and retrieval parameters, while maintaining resilience against adversarial evasion techniques. This work establishes a foundational framework for intellectual property protection in retrieval-augmented AI systems.
Queries Are Not Alone: Clustering Text Embeddings for Video Search
Oct 09, 2025
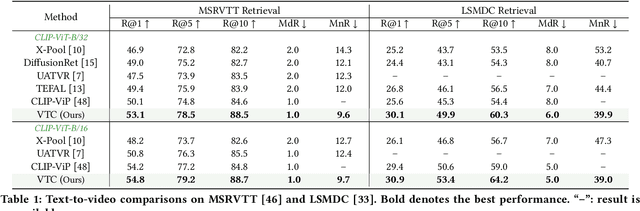
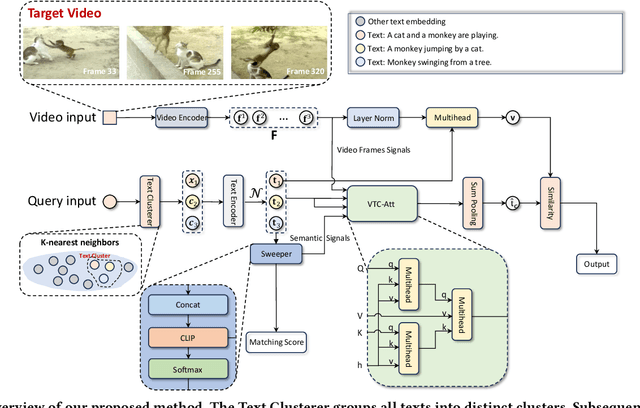
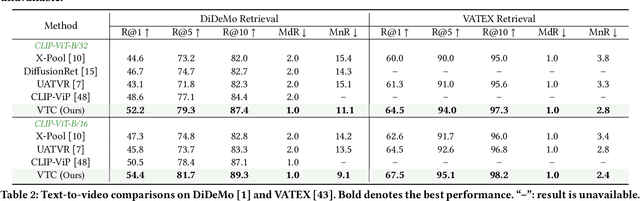
The rapid proliferation of video content across various platforms has highlighted the urgent need for advanced video retrieval systems. Traditional methods, which primarily depend on directly matching textual queries with video metadata, often fail to bridge the semantic gap between text descriptions and the multifaceted nature of video content. This paper introduces a novel framework, the Video-Text Cluster (VTC), which enhances video retrieval by clustering text queries to capture a broader semantic scope. We propose a unique clustering mechanism that groups related queries, enabling our system to consider multiple interpretations and nuances of each query. This clustering is further refined by our innovative Sweeper module, which identifies and mitigates noise within these clusters. Additionally, we introduce the Video-Text Cluster-Attention (VTC-Att) mechanism, which dynamically adjusts focus within the clusters based on the video content, ensuring that the retrieval process emphasizes the most relevant textual features. Further experiments have demonstrated that our proposed model surpasses existing state-of-the-art models on five public datasets.
BoRA: Towards More Expressive Low-Rank Adaptation with Block Diversity
Aug 09, 2025



Low-rank adaptation (LoRA) is a parameter-efficient fine-tuning (PEFT) method widely used in large language models (LLMs). It approximates the update of a pretrained weight matrix $W\in\mathbb{R}^{m\times n}$ by the product of two low-rank matrices, $BA$, where $A \in\mathbb{R}^{r\times n}$ and $B\in\mathbb{R}^{m\times r} (r\ll\min\{m,n\})$. Increasing the dimension $r$ can raise the rank of LoRA weights (i.e., $BA$), which typically improves fine-tuning performance but also significantly increases the number of trainable parameters. In this paper, we propose Block Diversified Low-Rank Adaptation (BoRA), which improves the rank of LoRA weights with a small number of additional parameters. Specifically, BoRA treats the product $BA$ as a block matrix multiplication, where $A$ and $B$ are partitioned into $b$ blocks along the columns and rows, respectively (i.e., $A=[A_1,\dots,A_b]$ and $B=[B_1,\dots,B_b]^\top$). Consequently, the product $BA$ becomes the concatenation of the block products $B_iA_j$ for $i,j\in[b]$. To enhance the diversity of different block products, BoRA introduces a unique diagonal matrix $\Sigma_{i,j} \in \mathbb{R}^{r\times r}$ for each block multiplication, resulting in $B_i \Sigma_{i,j} A_j$. By leveraging these block-wise diagonal matrices, BoRA increases the rank of LoRA weights by a factor of $b$ while only requiring $b^2r$ additional parameters. Extensive experiments across multiple datasets and models demonstrate the superiority of BoRA, and ablation studies further validate its scalability.
Shapley Value-driven Data Pruning for Recommender Systems
May 28, 2025Recommender systems often suffer from noisy interactions like accidental clicks or popularity bias. Existing denoising methods typically identify users' intent in their interactions, and filter out noisy interactions that deviate from the assumed intent. However, they ignore that interactions deemed noisy could still aid model training, while some ``clean'' interactions offer little learning value. To bridge this gap, we propose Shapley Value-driven Valuation (SVV), a framework that evaluates interactions based on their objective impact on model training rather than subjective intent assumptions. In SVV, a real-time Shapley value estimation method is devised to quantify each interaction's value based on its contribution to reducing training loss. Afterward, SVV highlights the interactions with high values while downplaying low ones to achieve effective data pruning for recommender systems. In addition, we develop a simulated noise protocol to examine the performance of various denoising approaches systematically. Experiments on four real-world datasets show that SVV outperforms existing denoising methods in both accuracy and robustness. Further analysis also demonstrates that our SVV can preserve training-critical interactions and offer interpretable noise assessment. This work shifts denoising from heuristic filtering to principled, model-driven interaction valuation.
Semantic Retrieval Augmented Contrastive Learning for Sequential Recommendation
Mar 06, 2025Sequential recommendation aims to model user preferences based on historical behavior sequences, which is crucial for various online platforms. Data sparsity remains a significant challenge in this area as most users have limited interactions and many items receive little attention. To mitigate this issue, contrastive learning has been widely adopted. By constructing positive sample pairs from the data itself and maximizing their agreement in the embedding space,it can leverage available data more effectively. Constructing reasonable positive sample pairs is crucial for the success of contrastive learning. However, current approaches struggle to generate reliable positive pairs as they either rely on representations learned from inherently sparse collaborative signals or use random perturbations which introduce significant uncertainty. To address these limitations, we propose a novel approach named Semantic Retrieval Augmented Contrastive Learning (SRA-CL), which leverages semantic information to improve the reliability of contrastive samples. SRA-CL comprises two main components: (1) Cross-Sequence Contrastive Learning via User Semantic Retrieval, which utilizes large language models (LLMs) to understand diverse user preferences and retrieve semantically similar users to form reliable positive samples through a learnable sample synthesis method; and (2) Intra-Sequence Contrastive Learning via Item Semantic Retrieval, which employs LLMs to comprehend items and retrieve similar items to perform semantic-based item substitution, thereby creating semantically consistent augmented views for contrastive learning. SRA-CL is plug-and-play and can be integrated into standard sequential recommendation models. Extensive experiments on four public datasets demonstrate the effectiveness and generalizability of the proposed approach.