 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinToolSyn: A forward synthesis Framework for Financial Tool-Use Dialogue Data with Dynamic Tool Retrieval
Mar 25, 2026Tool-use capabilities are vital for Large Language Models (LLMs) in finance, a domain characterized by massive investment targets and data-intensive inquiries. However, existing data synthesis methods typically rely on a reverse synthesis paradigm, generating user queries from pre-sampled tools. This approach inevitably introduces artificial explicitness, yielding queries that fail to capture the implicit, event-driven nature of real-world needs. Moreover, its reliance on static tool sets overlooks the dynamic retrieval process required to navigate massive tool spaces. To address these challenges, we introduce \textit{FinToolSyn}, a forward synthesis framework designed to generate high-quality financial dialogues. Progressing from persona instruction and atomic tool synthesis to dynamic retrieval dialogue generation, our pipeline constructs a repository of 43,066 tools and synthesizes over 148k dialogue instances, incorporating dynamic retrieval to emulate the noisy candidate sets typical of massive tool spaces. We also establish a dedicated benchmark to evaluate tool-calling capabilities in realistic financial scenarios. Extensive experiments demonstrate that models trained on FinToolSyn achieve a 21.06\% improvement, providing a robust foundation for tool learning in financial scenarios.
Multimodal Representation Learning Conditioned on Semantic Relations
Aug 24, 2025Multimodal representation learning has advanced rapidly with contrastive models such as CLIP, which align image-text pairs in a shared embedding space. However, these models face limitations: (1) they typically focus on image-text pairs, underutilizing the semantic relations across different pairs. (2) they directly match global embeddings without contextualization, overlooking the need for semantic alignment along specific subspaces or relational dimensions; and (3) they emphasize cross-modal contrast, with limited support for intra-modal consistency. To address these issues, we propose Relation-Conditioned Multimodal Learning RCML, a framework that learns multimodal representations under natural-language relation descriptions to guide both feature extraction and alignment. Our approach constructs many-to-many training pairs linked by semantic relations and introduces a relation-guided cross-attention mechanism that modulates multimodal representations under each relation context. The training objective combines inter-modal and intra-modal contrastive losses, encouraging consistency across both modalities and semantically related samples. Experiments on different datasets show that RCML consistently outperforms strong baselines on both retrieval and classification tasks, highlighting the effectiveness of leveraging semantic relations to guide multimodal representation learning.
MCFNet: A Multimodal Collaborative Fusion Network for Fine-Grained Semantic Classification
May 29, 2025



Multimodal information processing has become increasingly important for enhancing image classification performance. However, the intricate and implicit dependencies across different modalities often hinder conventional methods from effectively capturing fine-grained semantic interactions, thereby limiting their applicability in high-precision classification tasks. To address this issue, we propose a novel Multimodal Collaborative Fusion Network (MCFNet) designed for fine-grained classification. The proposed MCFNet architecture incorporates a regularized integrated fusion module that improves intra-modal feature representation through modality-specific regularization strategies, while facilitating precise semantic alignment via a hybrid attention mechanism. Additionally, we introduce a multimodal decision classification module, which jointly exploits inter-modal correlations and unimodal discriminative features by integrating multiple loss functions within a weighted voting paradigm. Extensive experiments and ablation studies on benchmark datasets demonstrate that the proposed MCFNet framework achieves consistent improvements in classification accuracy, confirming its effectiveness in modeling subtle cross-modal semantics.
Benchmarking for Deep Uplift Modeling in Online Marketing
Jun 01, 2024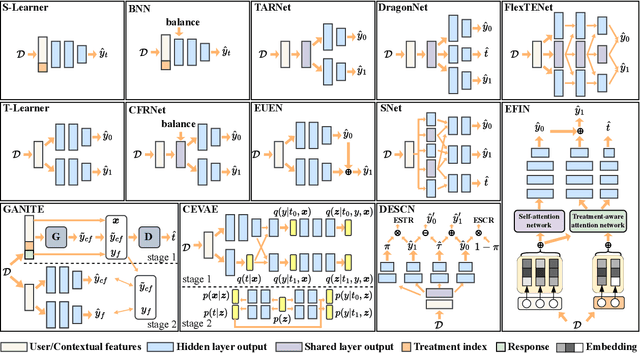



Online marketing is critical for many industrial platforms and business applications, aiming to increase user engagement and platform revenue by identifying corresponding delivery-sensitive groups for specific incentives, such as coupons and bonuses. As the scale and complexity of features in industrial scenarios increase, deep uplift modeling (DUM) as a promising technique has attracted increased research from academia and industry, resulting in various predictive models. However, current DUM still lacks some standardized benchmarks and unified evaluation protocols, which limit the reproducibility of experimental results in existing studies and the practical value and potential impact in this direction. In this paper, we provide an open benchmark for DUM and present comparison results of existing models in a reproducible and uniform manner. To this end, we conduct extensive experiments on two representative industrial datasets with different preprocessing settings to re-evaluate 13 existing models. Surprisingly, our experimental results show that the most recent work differs less than expected from traditional work in many cases. In addition, our experiments also reveal the limitations of DUM in generalization, especially for different preprocessing and test distributions. Our benchmarking work allows researchers to evaluate the performance of new models quickly but also reasonably demonstrates fair comparison results with existing models. It also gives practitioners valuable insights into often overlooked considerations when deploying DUM. We will make this benchmarking library, evaluation protocol, and experimental setup available on GitHub.
Touch the Core: Exploring Task Dependence Among Hybrid Targets for Recommendation
Mar 26, 2024As user behaviors become complicated on business platforms, online recommendations focus more on how to touch the core conversions, which are highly related to the interests of platforms. These core conversions are usually continuous targets, such as \textit{watch time}, \textit{revenue}, and so on, whose predictions can be enhanced by previous discrete conversion actions. Therefore, multi-task learning (MTL) can be adopted as the paradigm to learn these hybrid targets. However, existing works mainly emphasize investigating the sequential dependence among discrete conversion actions, which neglects the complexity of dependence between discrete conversions and the final continuous conversion. Moreover, simultaneously optimizing hybrid tasks with stronger task dependence will suffer from volatile issues where the core regression task might have a larger influence on other tasks. In this paper, we study the MTL problem with hybrid targets for the first time and propose the model named Hybrid Targets Learning Network (HTLNet) to explore task dependence and enhance optimization. Specifically, we introduce label embedding for each task to explicitly transfer the label information among these tasks, which can effectively explore logical task dependence. We also further design the gradient adjustment regime between the final regression task and other classification tasks to enhance the optimization. Extensive experiments on two offline public datasets and one real-world industrial dataset are conducted to validate the effectiveness of HTLNet. Moreover, online A/B tests on the financial recommender system also show our model has superior improvement.
Treatment-Aware Hyperbolic Representation Learning for Causal Effect Estimation with Social Networks
Jan 12, 2024Estimating the individual treatment effect (ITE) from observational data is a crucial research topic that holds significant value across multiple domains. How to identify hidden confounders poses a key challenge in ITE estimation. Recent studies have incorporated the structural information of social networks to tackle this challenge, achieving notable advancements. However, these methods utilize graph neural networks to learn the representation of hidden confounders in Euclidean space, disregarding two critical issues: (1) the social networks often exhibit a scalefree structure, while Euclidean embeddings suffer from high distortion when used to embed such graphs, and (2) each ego-centric network within a social network manifests a treatment-related characteristic, implying significant patterns of hidden confounders. To address these issues, we propose a novel method called Treatment-Aware Hyperbolic Representation Learning (TAHyper). Firstly, TAHyper employs the hyperbolic space to encode the social networks, thereby effectively reducing the distortion of confounder representation caused by Euclidean embeddings. Secondly, we design a treatment-aware relationship identification module that enhances the representation of hidden confounders by identifying whether an individual and her neighbors receive the same treatment. Extensive experiments on two benchmark datasets are conducted to demonstrate the superiority of our method.
Higher-order Graph Attention Network for Stock Selection with Joint Analysis
Jun 27, 2023



Stock selection is important for investors to construct profitable portfolios. Graph neural networks (GNNs) are increasingly attracting researchers for stock prediction due to their strong ability of relation modelling and generalisation. However, the existing GNN methods only focus on simple pairwise stock relation and do not capture complex higher-order structures modelling relations more than two nodes. In addition, they only consider factors of technical analysis and overlook factors of fundamental analysis that can affect the stock trend significantly. Motivated by them, we propose higher-order graph attention network with joint analysis (H-GAT). H-GAT is able to capture higher-order structures and jointly incorporate factors of fundamental analysis with factors of technical analysis. Specifically, the sequential layer of H-GAT take both types of factors as the input of a long-short term memory model. The relation embedding layer of H-GAT constructs a higher-order graph and learn node embedding with GAT. We then predict the ranks of stock return. Extensive experiments demonstrate the superiority of our H-GAT method on the profitability test and Sharp ratio over both NSDAQ and NYSE datasets
OptMSM: Optimizing Multi-Scenario Modeling for Click-Through Rate Prediction
Jun 23, 2023A large-scale industrial recommendation platform typically consists of multiple associated scenarios, requiring a unified click-through rate (CTR) prediction model to serve them simultaneously. Existing approaches for multi-scenario CTR prediction generally consist of two main modules: i) a scenario-aware learning module that learns a set of multi-functional representations with scenario-shared and scenario-specific information from input features, and ii) a scenario-specific prediction module that serves each scenario based on these representations. However, most of these approaches primarily focus on improving the former module and neglect the latter module. This can result in challenges such as increased model parameter size, training difficulty, and performance bottlenecks for each scenario. To address these issues, we propose a novel framework called OptMSM (\textbf{Opt}imizing \textbf{M}ulti-\textbf{S}cenario \textbf{M}odeling). First, we introduce a simplified yet effective scenario-enhanced learning module to alleviate the aforementioned challenges. Specifically, we partition the input features into scenario-specific and scenario-shared features, which are mapped to specific information embedding encodings and a set of shared information embeddings, respectively. By imposing an orthogonality constraint on the shared information embeddings to facilitate the disentanglement of shared information corresponding to each scenario, we combine them with the specific information embeddings to obtain multi-functional representations. Second, we introduce a scenario-specific hypernetwork in the scenario-specific prediction module to capture interactions within each scenario more effectively, thereby alleviating the performance bottlenecks. Finally, we conduct extensive offline experiments and an online A/B test to demonstrate the effectiveness of OptMSM.
Self-Sampling Training and Evaluation for the Accuracy-Bias Tradeoff in Recommendation
Feb 07, 2023



Research on debiased recommendation has shown promising results. However, some issues still need to be handled for its application in industrial recommendation. For example, most of the existing methods require some specific data, architectures and training methods. In this paper, we first argue through an online study that arbitrarily removing all the biases in industrial recommendation may not consistently yield a desired performance improvement. For the situation that a randomized dataset is not available, we propose a novel self-sampling training and evaluation (SSTE) framework to achieve the accuracy-bias tradeoff in recommendation, i.e., eliminate the harmful biases and preserve the beneficial ones. Specifically, SSTE uses a self-sampling module to generate some subsets with different degrees of bias from the original training and validation data. A self-training module infers the beneficial biases and learns better tradeoff based on these subsets, and a self-evaluation module aims to use these subsets to construct more plausible references to reflect the optimized model. Finally, we conduct extensive offline experiments on two datasets to verify the effectiveness of our SSTE. Moreover, we deploy our SSTE in homepage recommendation of a famous financial management product called Tencent Licaitong, and find very promising results in an online A/B test.
Unsupervised Inductive Whole-Graph Embedding by Preserving Graph Proximity
Apr 01, 2019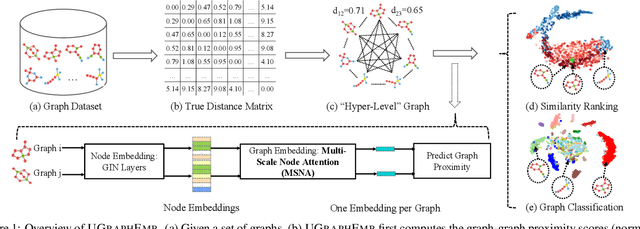



We introduce a novel approach to graph-level representation learning, which is to embed an entire graph into a vector space where the embeddings of two graphs preserve their graph-graph proximity. Our approach, UGRAPHEMB, is a general framework that provides a novel means to performing graph-level embedding in a completely unsupervised and inductive manner. The learned neural network can be considered as a function that receives any graph as input, either seen or unseen in the training set, and transforms it into an embedding. A novel graph-level embedding generation mechanism called Multi-Scale Node Attention (MSNA), is proposed. Experiments on five real graph datasets show that UGRAPHEMB achieves competitive accuracy in the tasks of graph classification, similarity ranking, and graph visualization.