 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards deployment-centric multimodal AI beyond vision and language
Apr 04, 2025Multimodal artificial intelligence (AI) integrates diverse types of data via machine learning to improve understanding, prediction, and decision-making across disciplines such as healthcare, science, and engineering. However, most multimodal AI advances focus on models for vision and language data, while their deployability remains a key challenge. We advocate a deployment-centric workflow that incorporates deployment constraints early to reduce the likelihood of undeployable solutions, complementing data-centric and model-centric approaches. We also emphasise deeper integration across multiple levels of multimodality and multidisciplinary collaboration to significantly broaden the research scope beyond vision and language. To facilitate this approach, we identify common multimodal-AI-specific challenges shared across disciplines and examine three real-world use cases: pandemic response, self-driving car design, and climate change adaptation, drawing expertise from healthcare, social science, engineering, science, sustainability, and finance. By fostering multidisciplinary dialogue and open research practices, our community can accelerate deployment-centric development for broad societal impact.
Quantum Circuit Synthesis and Compilation Optimization: Overview and Prospects
Jun 30, 2024Quantum computing is regarded as a promising paradigm that may overcome the current computational power bottlenecks in the post-Moore era. The increasing maturity of quantum processors, especially superconducting ones, provides more possibilities for the development and implementation of quantum algorithms. As the crucial stages for quantum algorithm implementation, the logic circuit design and quantum compiling have also received significant attention, which covers key technologies such as quantum logic circuit synthesis (also widely known as quantum architecture search) and optimization, as well as qubit mapping and routing. Recent studies suggest that the scale and precision of related algorithms are steadily increasing, especially with the integration of artificial intelligence methods. In this survey, we systematically review and summarize a vast body of literature, exploring the feasibility of an integrated design and optimization scheme that spans from the algorithmic level to quantum hardware, combining the steps of logic circuit design and compilation optimization. Leveraging the exceptional cognitive and learning capabilities of AI algorithms, one can reduce manual design costs, enhance the precision and efficiency of execution, and facilitate the implementation and validation of the superiority of quantum algorithms on hardware.
DGDNN: Decoupled Graph Diffusion Neural Network for Stock Movement Prediction
Jan 03, 2024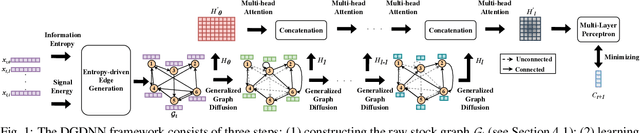



Forecasting future stock trends remains challenging for academia and industry due to stochastic inter-stock dynamics and hierarchical intra-stock dynamics influencing stock prices. In recent years, graph neural networks have achieved remarkable performance in this problem by formulating multiple stocks as graph-structured data. However, most of these approaches rely on artificially defined factors to construct static stock graphs, which fail to capture the intrinsic interdependencies between stocks that rapidly evolve. In addition, these methods often ignore the hierarchical features of the stocks and lose distinctive information within. In this work, we propose a novel graph learning approach implemented without expert knowledge to address these issues. First, our approach automatically constructs dynamic stock graphs by entropy-driven edge generation from a signal processing perspective. Then, we further learn task-optimal dependencies between stocks via a generalized graph diffusion process on constructed stock graphs. Last, a decoupled representation learning scheme is adopted to capture distinctive hierarchical intra-stock features. Experimental results demonstrate substantial improvements over state-of-the-art baselines on real-world datasets. Moreover, the ablation study and sensitivity study further illustrate the effectiveness of the proposed method in modeling the time-evolving inter-stock and intra-stock dynamics.
Automatic Data Visualization Generation from Chinese Natural Language Questions
Sep 14, 2023



Data visualization has emerged as an effective tool for getting insights from massive datasets. Due to the hardness of manipulating the programming languages of data visualization, automatic data visualization generation from natural languages (Text-to-Vis) is becoming increasingly popular. Despite the plethora of research effort on the English Text-to-Vis, studies have yet to be conducted on data visualization generation from questions in Chinese. Motivated by this, we propose a Chinese Text-to-Vis dataset in the paper and demonstrate our first attempt to tackle this problem. Our model integrates multilingual BERT as the encoder, boosts the cross-lingual ability, and infuses the $n$-gram information into our word representation learning. Our experimental results show that our dataset is challenging and deserves further research.
Higher-order Graph Attention Network for Stock Selection with Joint Analysis
Jun 27, 2023



Stock selection is important for investors to construct profitable portfolios. Graph neural networks (GNNs) are increasingly attracting researchers for stock prediction due to their strong ability of relation modelling and generalisation. However, the existing GNN methods only focus on simple pairwise stock relation and do not capture complex higher-order structures modelling relations more than two nodes. In addition, they only consider factors of technical analysis and overlook factors of fundamental analysis that can affect the stock trend significantly. Motivated by them, we propose higher-order graph attention network with joint analysis (H-GAT). H-GAT is able to capture higher-order structures and jointly incorporate factors of fundamental analysis with factors of technical analysis. Specifically, the sequential layer of H-GAT take both types of factors as the input of a long-short term memory model. The relation embedding layer of H-GAT constructs a higher-order graph and learn node embedding with GAT. We then predict the ranks of stock return. Extensive experiments demonstrate the superiority of our H-GAT method on the profitability test and Sharp ratio over both NSDAQ and NYSE datasets
Knowledge-aware Neural Collective Matrix Factorization for Cross-domain Recommendation
Jun 27, 2022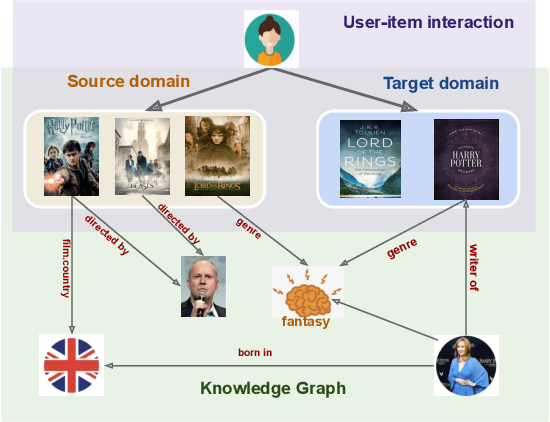
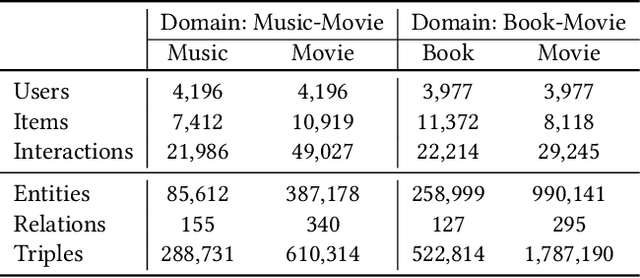
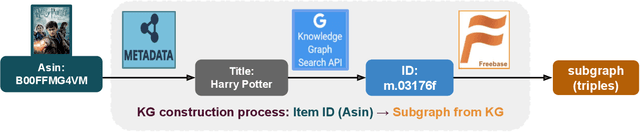
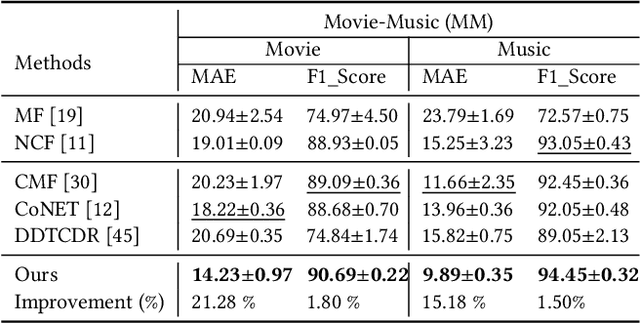
Cross-domain recommendation (CDR) can help customers find more satisfying items in different domains. Existing CDR models mainly use common users or mapping functions as bridges between domains but have very limited exploration in fully utilizing extra knowledge across domains. In this paper, we propose to incorporate the knowledge graph (KG) for CDR, which enables items in different domains to share knowledge. To this end, we first construct a new dataset AmazonKG4CDR from the Freebase KG and a subset (two domain pairs: movies-music, movie-book) of Amazon Review Data. This new dataset facilitates linking knowledge to bridge within- and cross-domain items for CDR. Then we propose a new framework, KG-aware Neural Collective Matrix Factorization (KG-NeuCMF), leveraging KG to enrich item representations. It first learns item embeddings by graph convolutional autoencoder to capture both domain-specific and domain-general knowledge from adjacent and higher-order neighbours in the KG. Then, we maximize the mutual information between item embeddings learned from the KG and user-item matrix to establish cross-domain relationships for better CDR. Finally, we conduct extensive experiments on the newly constructed dataset and demonstrate that our model significantly outperforms the best-performing baselines.
Unifying Homophily and Heterophily Network Transformation via Motifs
Dec 27, 2020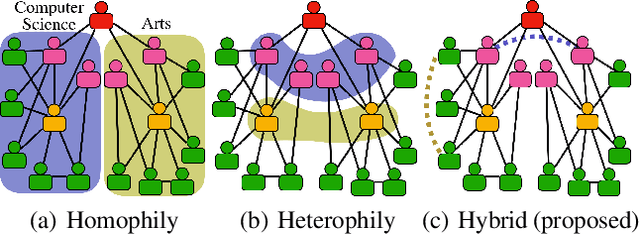

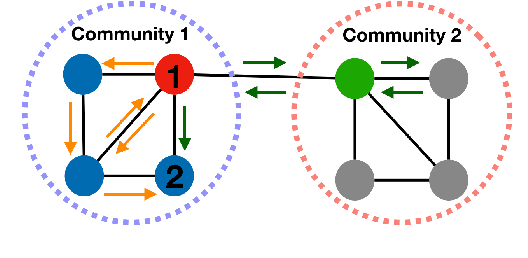
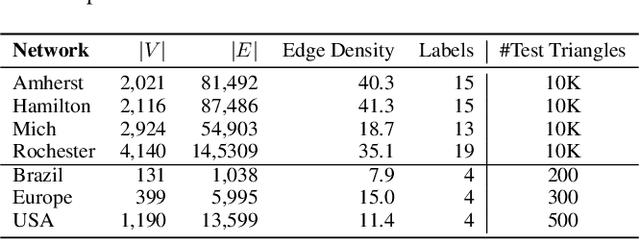
Higher-order proximity (HOP) is fundamental for most network embedding methods due to its significant effects on the quality of node embedding and performance on downstream network analysis tasks. Most existing HOP definitions are based on either homophily to place close and highly interconnected nodes tightly in embedding space or heterophily to place distant but structurally similar nodes together after embedding. In real-world networks, both can co-exist, and thus considering only one could limit the prediction performance and interpretability. However, there is no general and universal solution that takes both into consideration. In this paper, we propose such a simple yet powerful framework called homophily and heterophliy preserving network transformation (H2NT) to capture HOP that flexibly unifies homophily and heterophily. Specifically, H2NT utilises motif representations to transform a network into a new network with a hybrid assumption via micro-level and macro-level walk paths. H2NT can be used as an enhancer to be integrated with any existing network embedding methods without requiring any changes to latter methods. Because H2NT can sparsify networks with motif structures, it can also improve the computational efficiency of existing network embedding methods when integrated. We conduct experiments on node classification, structural role classification and motif prediction to show the superior prediction performance and computational efficiency over state-of-the-art methods. In particular, DeepWalk-based H2 NT achieves 24% improvement in terms of precision on motif prediction, while reducing 46% computational time compared to the original DeepWalk.
Hop-Hop Relation-aware Graph Neural Networks
Dec 21, 2020
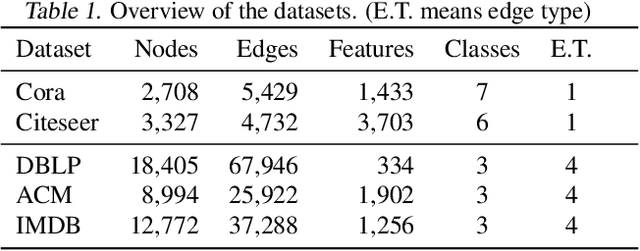
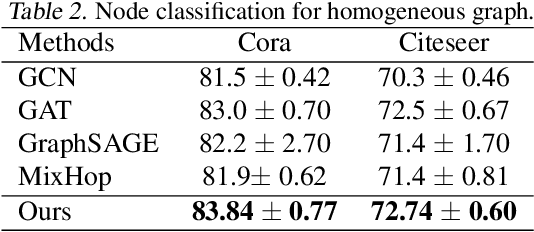
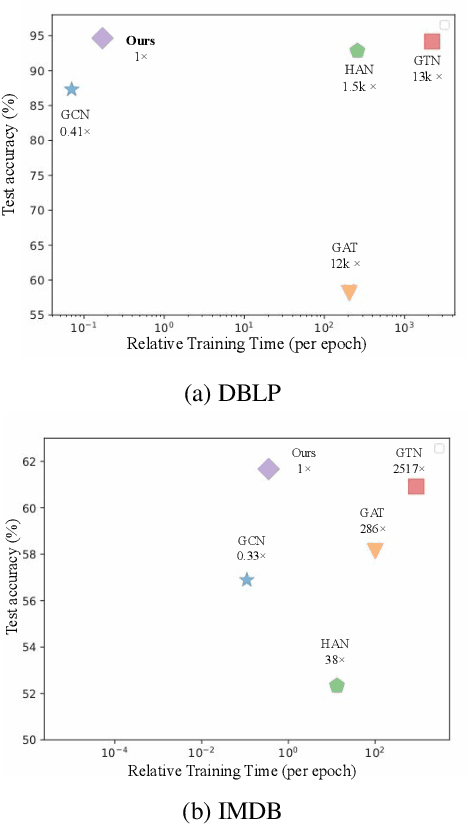
Graph Neural Networks (GNNs) are widely used in graph representation learning. However, most GNN methods are designed for either homogeneous or heterogeneous graphs. In this paper, we propose a new model, Hop-Hop Relation-aware Graph Neural Network (HHR-GNN), to unify representation learning for these two types of graphs. HHR-GNN learns a personalized receptive field for each node by leveraging knowledge graph embedding to learn relation scores between the central node's representations at different hops. In neighborhood aggregation, our model simultaneously allows for hop-aware projection and aggregation. This mechanism enables the central node to learn a hop-wise neighborhood mixing that can be applied to both homogeneous and heterogeneous graphs. Experimental results on five benchmarks show the competitive performance of our model compared to state-of-the-art GNNs, e.g., up to 13K faster in terms of time cost per training epoch on large heterogeneous graphs.
Cell Mechanics Based Computational Classification of Red Blood Cells Via Machine Intelligence Applied to Morpho-Rheological Markers
Mar 02, 2020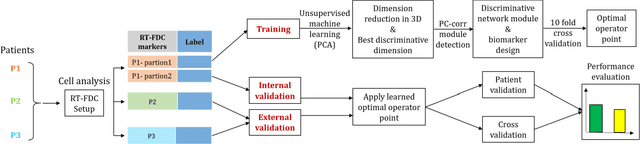
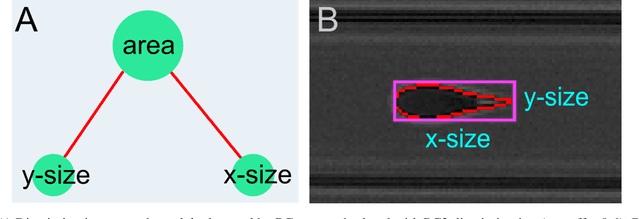
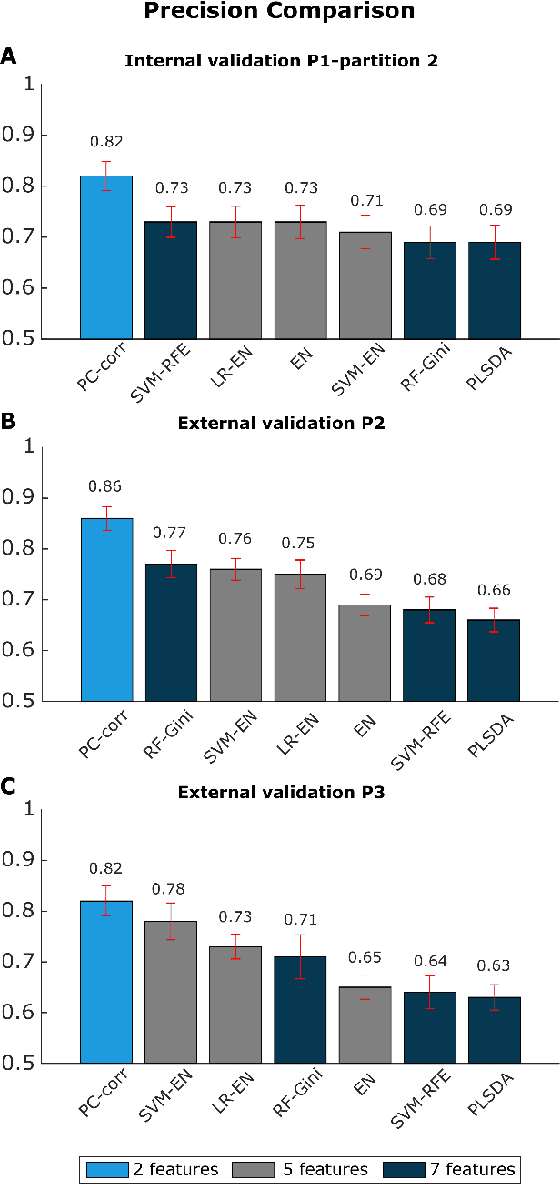
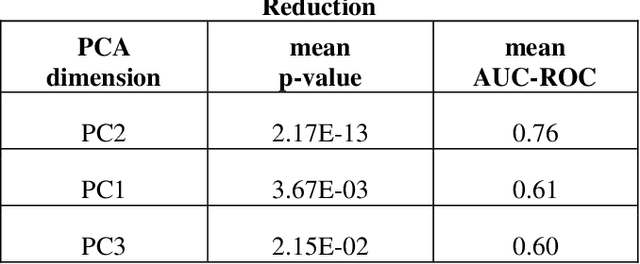
Despite fluorescent cell-labelling being widely employed in biomedical studies, some of its drawbacks are inevitable, with unsuitable fluorescent probes or probes inducing a functional change being the main limitations. Consequently, the demand for and development of label-free methodologies to classify cells is strong and its impact on precision medicine is relevant. Towards this end, high-throughput techniques for cell mechanical phenotyping have been proposed to get a multidimensional biophysical characterization of single cells. With this motivation, our goal here is to investigate the extent to which an unsupervised machine learning methodology, which is applied exclusively on morpho-rheological markers obtained by real-time deformability and fluorescence cytometry (RT-FDC), can address the difficult task of providing label-free discrimination of reticulocytes from mature red blood cells. We focused on this problem, since the characterization of reticulocytes (their percentage and cellular features) in the blood is vital in multiple human disease conditions, especially bone-marrow disorders such as anemia and leukemia. Our approach reports promising label-free results in the classification of reticulocytes from mature red blood cells, and it represents a step forward in the development of high-throughput morpho-rheological-based methodologies for the computational categorization of single cells. Besides, our methodology can be an alternative but also a complementary method to integrate with existing cell-labelling techniques.
* 13 pages, 3 figures, 4 tables
Mixed-Order Spectral Clustering for Networks
Dec 25, 2018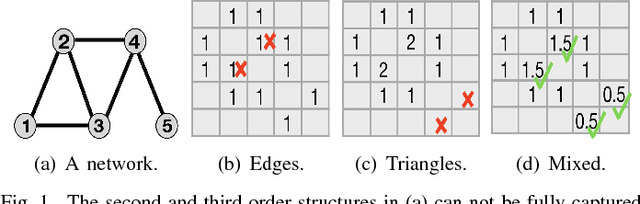
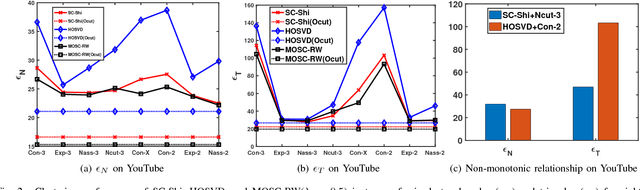
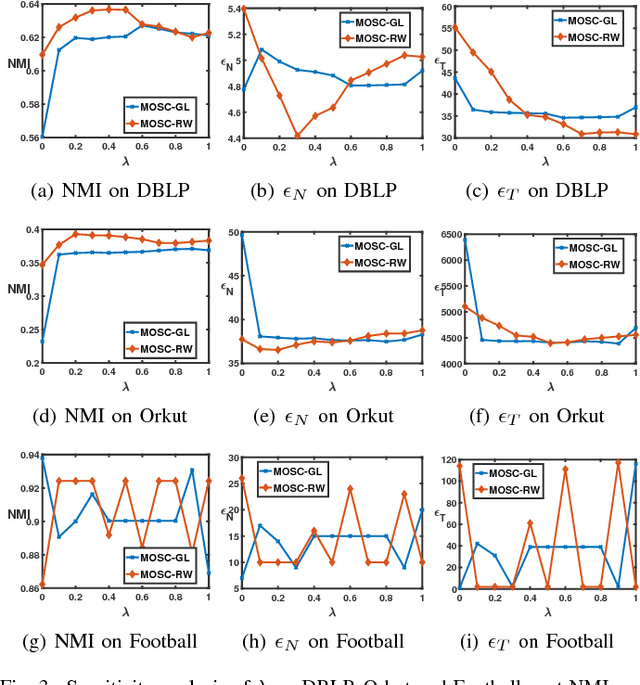
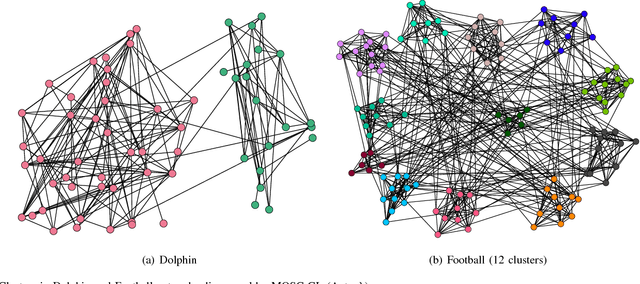
Clustering is fundamental for gaining insights from complex networks, and spectral clustering (SC) is a popular approach. Conventional SC focuses on second-order structures (e.g., edges connecting two nodes) without direct consideration of higher-order structures (e.g., triangles and cliques). This has motivated SC extensions that directly consider higher-order structures. However, both approaches are limited to considering a single order. This paper proposes a new Mixed-Order Spectral Clustering (MOSC) approach to model both second-order and third-order structures simultaneously, with two MOSC methods developed based on Graph Laplacian (GL) and Random Walks (RW). MOSC-GL combines edge and triangle adjacency matrices, with theoretical performance guarantee. MOSC-RW combines first-order and second-order random walks for a probabilistic interpretation. We automatically determine the mixing parameter based on cut criteria or triangle density, and construct new structure-aware error metrics for performance evaluation. Experiments on real-world networks show 1) the superior performance of two MOSC methods over existing SC methods, 2) the effectiveness of the mixing parameter determination strategy, and 3) insights offered by the structure-aware error metrics.