 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePivoting Factorization: A Compact Meta Low-Rank Representation of Sparsity for Efficient Inference in Large Language Models
Jan 31, 2025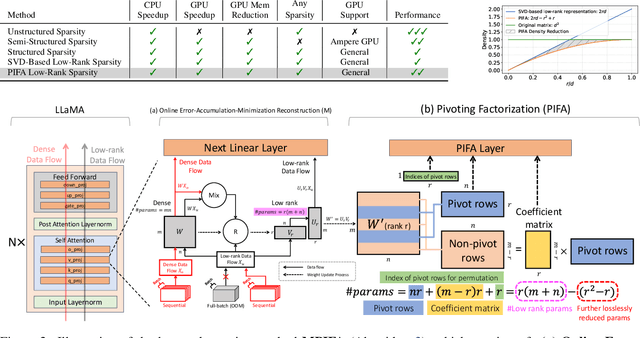
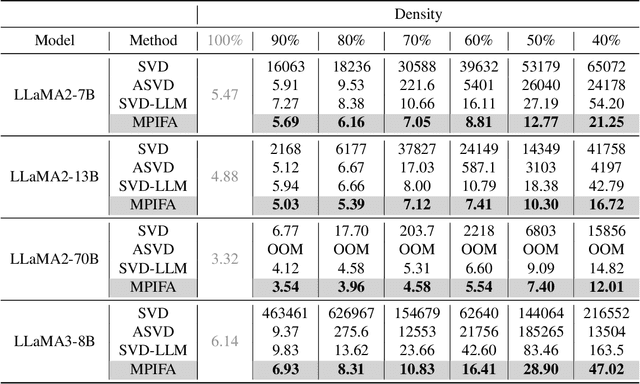
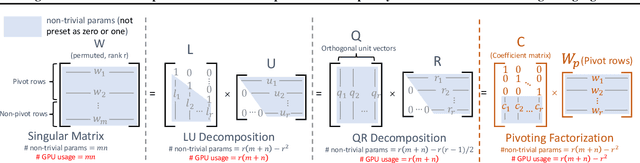
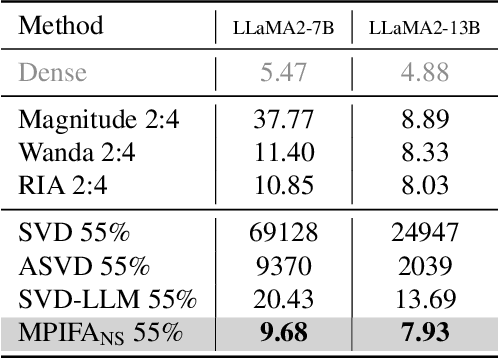
The rapid growth of Large Language Models has driven demand for effective model compression techniques to reduce memory and computation costs. Low-rank pruning has gained attention for its tensor coherence and GPU compatibility across all densities. However, low-rank pruning has struggled to match the performance of semi-structured pruning, often doubling perplexity (PPL) at similar densities. In this paper, we propose Pivoting Factorization (PIFA), a novel lossless meta low-rank representation that unsupervisedly learns a compact form of any low-rank representation, effectively eliminating redundant information. PIFA identifies pivot rows (linearly independent rows) and expresses non-pivot rows as linear combinations, achieving an additional 24.2\% memory savings and 24.6\% faster inference over low-rank layers at r/d = 0.5, thereby significantly enhancing performance at the same density. To mitigate the performance degradation caused by low-rank pruning, we introduce a novel, retraining-free low-rank reconstruction method that minimizes error accumulation (M). MPIFA, combining M and PIFA into an end-to-end framework, significantly outperforms existing low-rank pruning methods and, for the first time, achieves performance comparable to semi-structured pruning, while surpassing it in GPU efficiency and compatibility.
Brain-inspired sparse training enables Transformers and LLMs to perform as fully connected
Jan 31, 2025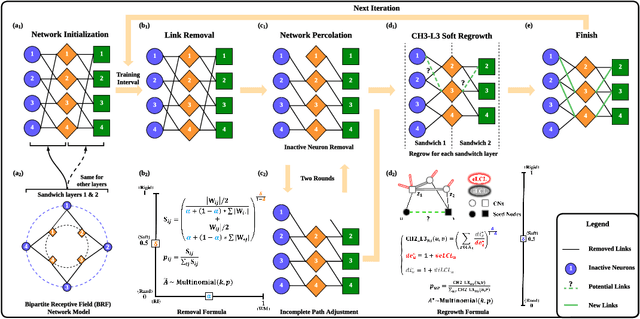
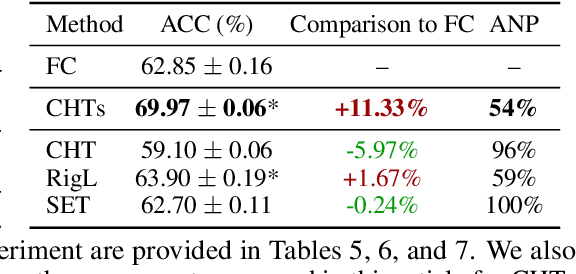
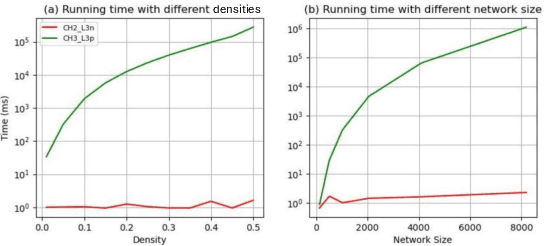
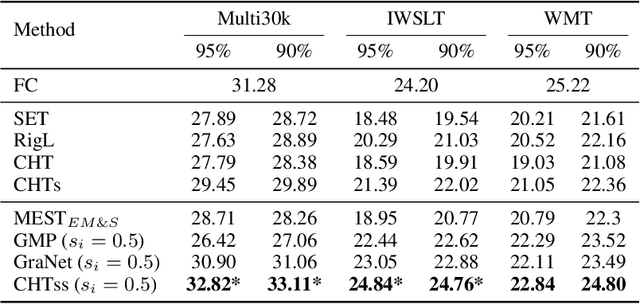
This study aims to enlarge our current knowledge on application of brain-inspired network science principles for training artificial neural networks (ANNs) with sparse connectivity. Dynamic sparse training (DST) can reduce the computational demands in ANNs, but faces difficulties to keep peak performance at high sparsity levels. The Cannistraci-Hebb training (CHT) is a brain-inspired method for growing connectivity in DST. CHT leverages a gradient-free, topology-driven link regrowth, which has shown ultra-sparse (1% connectivity or lower) advantage across various tasks compared to fully connected networks. Yet, CHT suffers two main drawbacks: (i) its time complexity is O(Nd^3) - N node network size, d node degree - hence it can apply only to ultra-sparse networks. (ii) it selects top link prediction scores, which is inappropriate for the early training epochs, when the network presents unreliable connections. We propose a GPU-friendly approximation of the CH link predictor, which reduces the computational complexity to O(N^3), enabling a fast implementation of CHT in large-scale models. We introduce the Cannistraci-Hebb training soft rule (CHTs), which adopts a strategy for sampling connections in both link removal and regrowth, balancing the exploration and exploitation of network topology. To improve performance, we integrate CHTs with a sigmoid gradual density decay (CHTss). Empirical results show that, using 1% of connections, CHTs outperforms fully connected networks in MLP on visual classification tasks, compressing some networks to < 30% nodes. Using 5% of the connections, CHTss outperforms fully connected networks in two Transformer-based machine translation tasks. Using 30% of the connections, CHTss achieves superior performance compared to other dynamic sparse training methods in language modeling, and it surpasses the fully connected counterpart in zero-shot evaluations.
Sparse Spectral Training and Inference on Euclidean and Hyperbolic Neural Networks
May 24, 2024The growing computational demands posed by increasingly number of neural network's parameters necessitate low-memory-consumption training approaches. Previous memory reduction techniques, such as Low-Rank Adaptation (LoRA) and ReLoRA, suffer from the limitation of low rank and saddle point issues, particularly during intensive tasks like pre-training. In this paper, we propose Sparse Spectral Training (SST), an advanced training methodology that updates all singular values and selectively updates singular vectors of network weights, thereby optimizing resource usage while closely approximating full-rank training. SST refines the training process by employing a targeted updating strategy for singular vectors, which is determined by a multinomial sampling method weighted by the significance of the singular values, ensuring both high performance and memory reduction. Through comprehensive testing on both Euclidean and hyperbolic neural networks across various tasks, including natural language generation, machine translation, node classification and link prediction, SST demonstrates its capability to outperform existing memory reduction training methods and is comparable with full-rank training in some cases. On OPT-125M, with rank equating to 8.3% of embedding dimension, SST reduces the perplexity gap to full-rank training by 67.6%, demonstrating a significant reduction of the performance loss with prevalent low-rank methods. This approach offers a strong alternative to traditional training techniques, paving the way for more efficient and scalable neural network training solutions.
Cell Mechanics Based Computational Classification of Red Blood Cells Via Machine Intelligence Applied to Morpho-Rheological Markers
Mar 02, 2020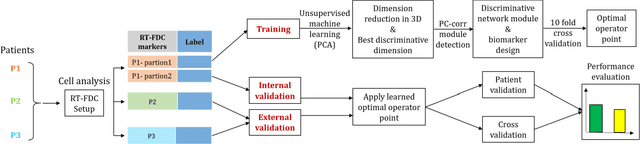
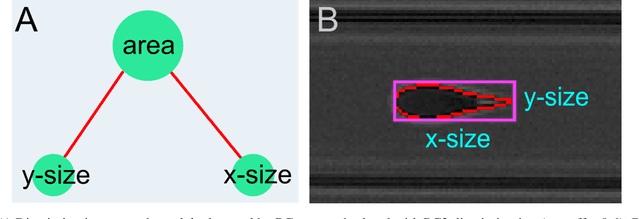
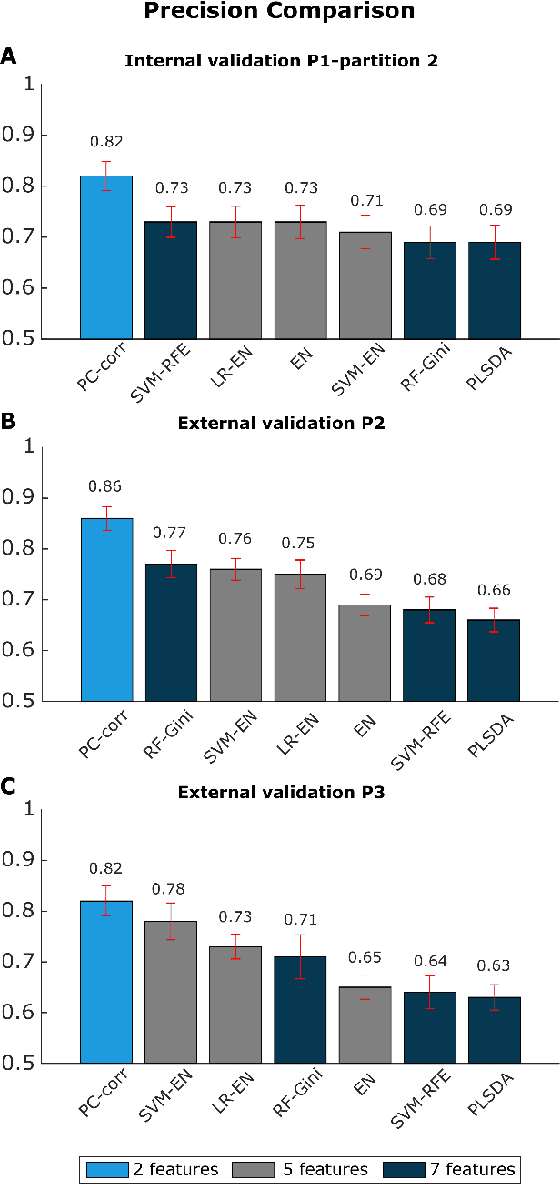
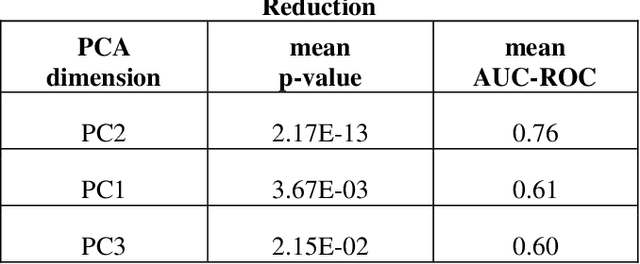
Despite fluorescent cell-labelling being widely employed in biomedical studies, some of its drawbacks are inevitable, with unsuitable fluorescent probes or probes inducing a functional change being the main limitations. Consequently, the demand for and development of label-free methodologies to classify cells is strong and its impact on precision medicine is relevant. Towards this end, high-throughput techniques for cell mechanical phenotyping have been proposed to get a multidimensional biophysical characterization of single cells. With this motivation, our goal here is to investigate the extent to which an unsupervised machine learning methodology, which is applied exclusively on morpho-rheological markers obtained by real-time deformability and fluorescence cytometry (RT-FDC), can address the difficult task of providing label-free discrimination of reticulocytes from mature red blood cells. We focused on this problem, since the characterization of reticulocytes (their percentage and cellular features) in the blood is vital in multiple human disease conditions, especially bone-marrow disorders such as anemia and leukemia. Our approach reports promising label-free results in the classification of reticulocytes from mature red blood cells, and it represents a step forward in the development of high-throughput morpho-rheological-based methodologies for the computational categorization of single cells. Besides, our methodology can be an alternative but also a complementary method to integrate with existing cell-labelling techniques.
* 13 pages, 3 figures, 4 tables
Angular separability of data clusters or network communities in geometrical space and its relevance to hyperbolic embedding
Jun 28, 2019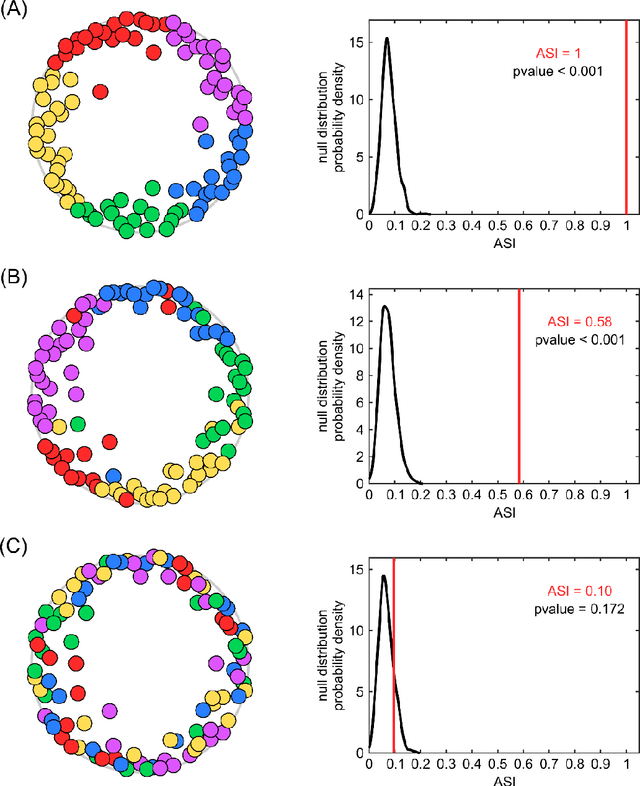
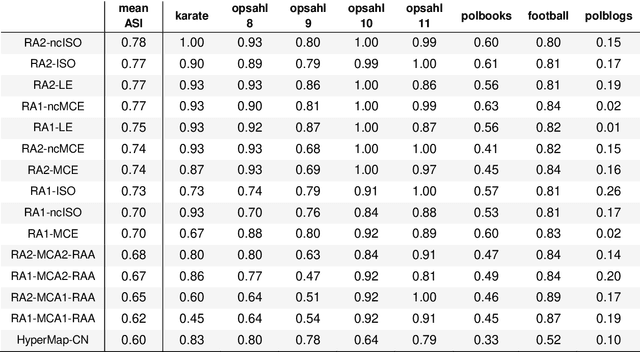
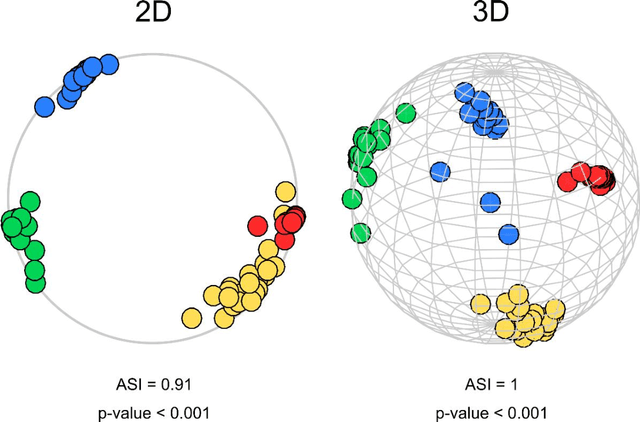
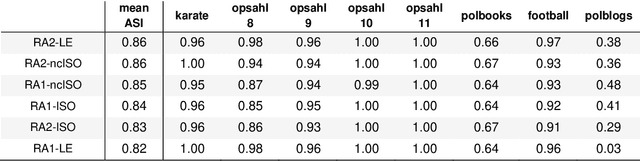
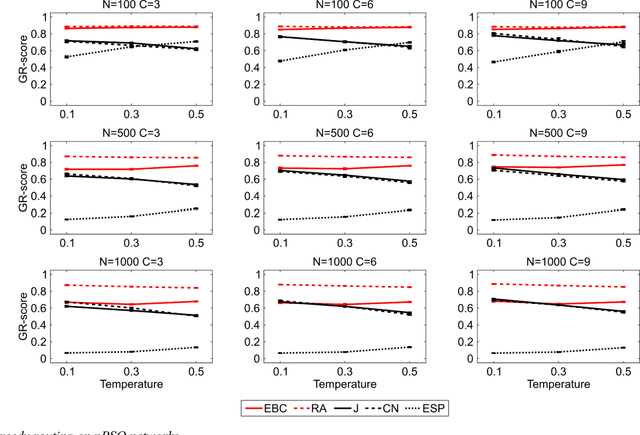
Analysis of 'big data' characterized by high-dimensionality such as word vectors and complex networks requires often their representation in a geometrical space by embedding. Recent developments in machine learning and network geometry have pointed out the hyperbolic space as a useful framework for the representation of this data derived by real complex physical systems. In the hyperbolic space, the radial coordinate of the nodes characterizes their hierarchy, whereas the angular distance between them represents their similarity. Several studies have highlighted the relationship between the angular coordinates of the nodes embedded in the hyperbolic space and the community metadata available. However, such analyses have been often limited to a visual or qualitative assessment. Here, we introduce the angular separation index (ASI), to quantitatively evaluate the separation of node network communities or data clusters over the angular coordinates of a geometrical space. ASI is particularly useful in the hyperbolic space - where it is extensively tested along this study - but can be used in general for any assessment of angular separation regardless of the adopted geometry. ASI is proposed together with an exact test statistic based on a uniformly random null model to assess the statistical significance of the separation. We show that ASI allows to discover two significant phenomena in network geometry. The first is that the increase of temperature in 2D hyperbolic network generative models, not only reduces the network clustering but also induces a 'dimensionality jump' of the network to dimensions higher than two. The second is that ASI can be successfully applied to detect the intrinsic dimensionality of network structures that grow in a hidden geometrical space.
Latent Geometry Inspired Graph Dissimilarities Enhance Affinity Propagation Community Detection in Complex Networks
Aug 29, 2018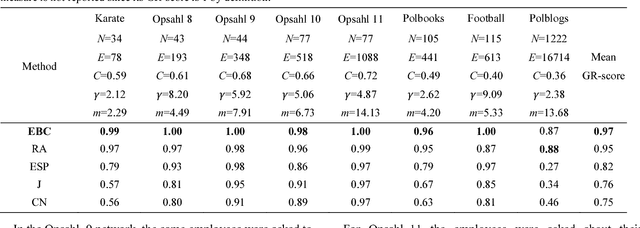
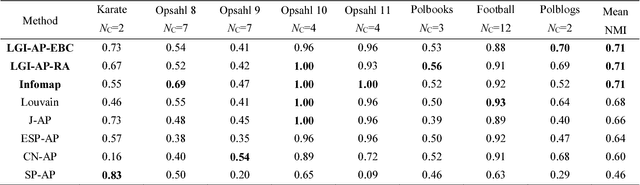

Affinity propagation is one of the most effective unsupervised pattern recognition algorithms for data clustering in high-dimensional feature space. However, the numerous attempts to test its performance for community detection in complex networks have been attaining results very far from the state of the art methods such as Infomap and Louvain. Yet, all these studies agreed that the crucial problem is to convert the unweighted network topology in a 'smart-enough' node dissimilarity matrix that is able to properly address the message passing procedure behind affinity propagation clustering. Here we introduce a conceptual innovation and we discuss how to leverage network latent geometry notions in order to design dissimilarity matrices for affinity propagation community detection. Our results demonstrate that the latent geometry inspired dissimilarity measures we design bring affinity propagation to equal or outperform current state of the art methods for community detection. These findings are solidly proven considering both synthetic 'realistic' networks (with known ground-truth communities) and real networks (with community metadata), even when the data structure is corrupted by noise artificially induced by missing or spurious connectivity.
Machine learning meets network science: dimensionality reduction for fast and efficient embedding of networks in the hyperbolic space
Feb 21, 2016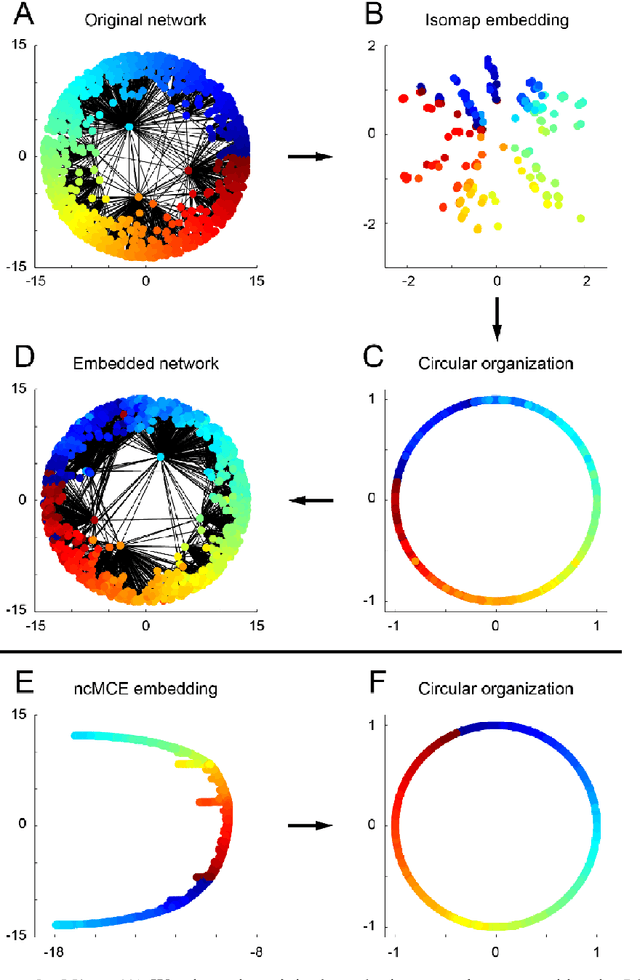
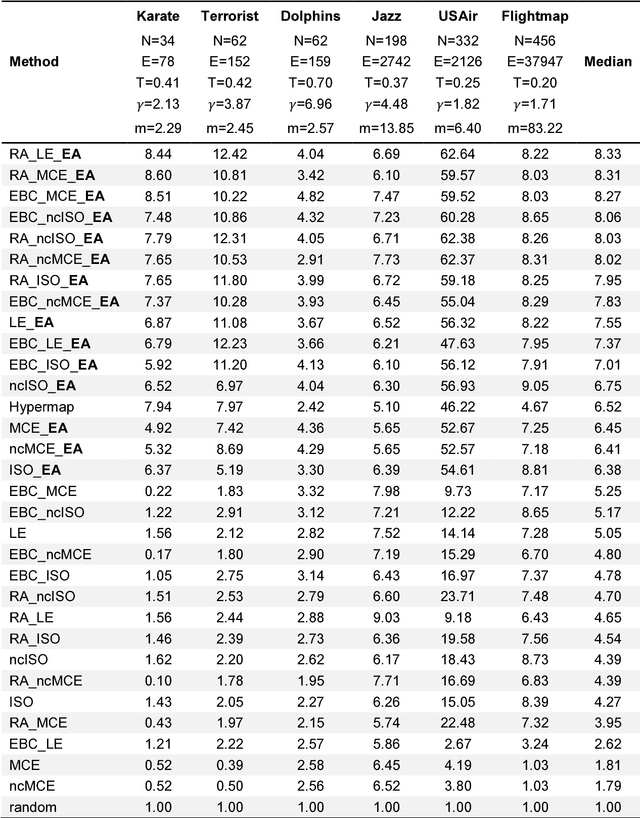
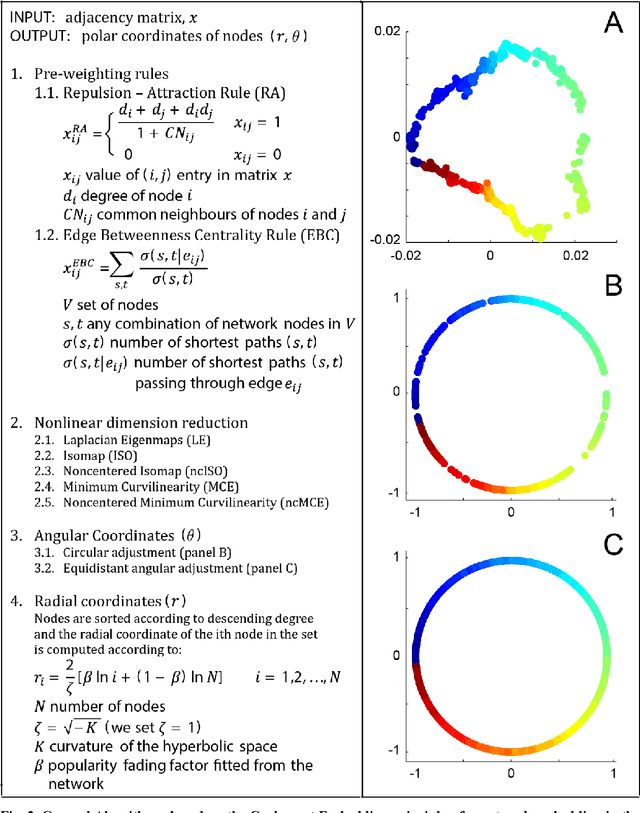
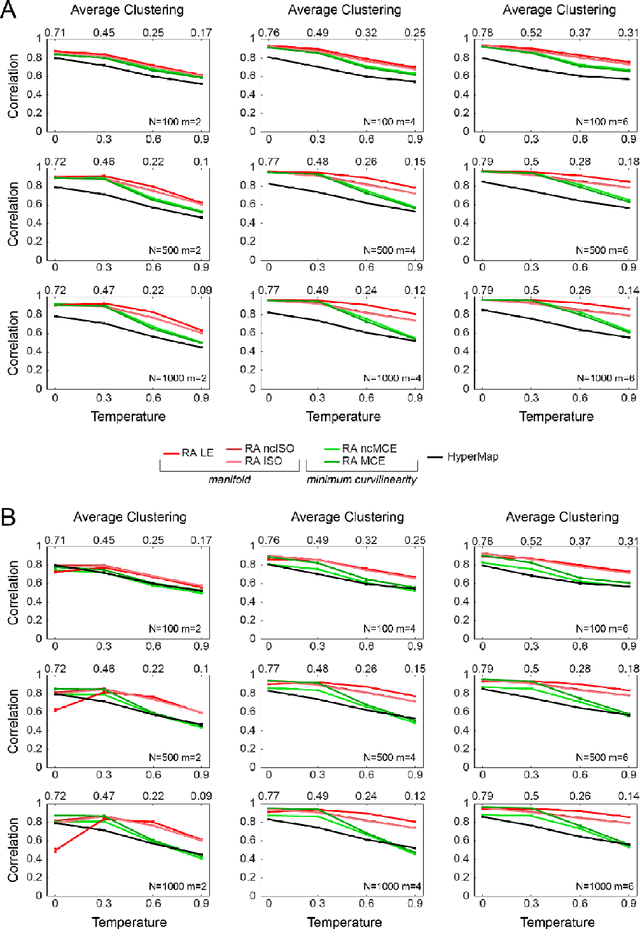
Complex network topologies and hyperbolic geometry seem specularly connected, and one of the most fascinating and challenging problems of recent complex network theory is to map a given network to its hyperbolic space. The Popularity Similarity Optimization (PSO) model represents - at the moment - the climax of this theory. It suggests that the trade-off between node popularity and similarity is a mechanism to explain how complex network topologies emerge - as discrete samples - from the continuous world of hyperbolic geometry. The hyperbolic space seems appropriate to represent real complex networks. In fact, it preserves many of their fundamental topological properties, and can be exploited for real applications such as, among others, link prediction and community detection. Here, we observe for the first time that a topological-based machine learning class of algorithms - for nonlinear unsupervised dimensionality reduction - can directly approximate the network's node angular coordinates of the hyperbolic model into a two-dimensional space, according to a similar topological organization that we named angular coalescence. On the basis of this phenomenon, we propose a new class of algorithms that offers fast and accurate coalescent embedding of networks in the hyperbolic space even for graphs with thousands of nodes.