 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrain-inspired sparse training enables Transformers and LLMs to perform as fully connected
Jan 31, 2025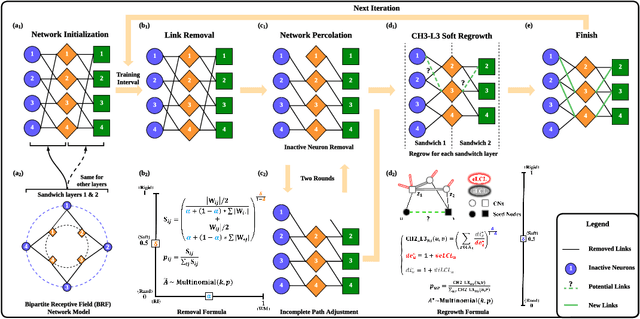
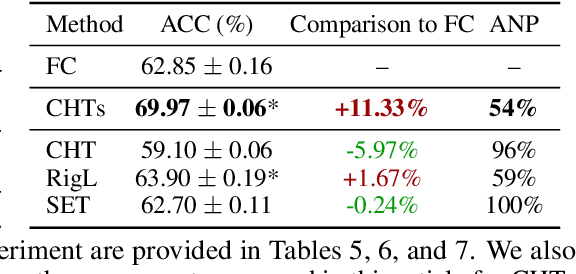
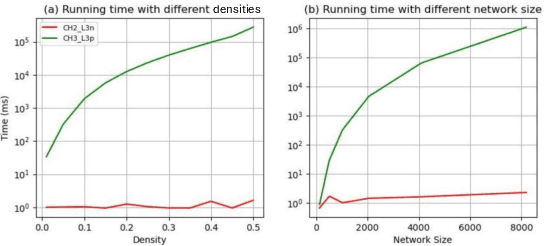
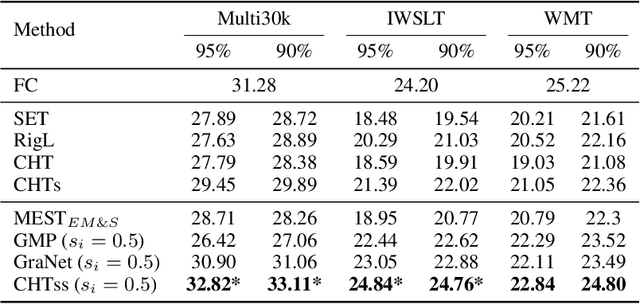
This study aims to enlarge our current knowledge on application of brain-inspired network science principles for training artificial neural networks (ANNs) with sparse connectivity. Dynamic sparse training (DST) can reduce the computational demands in ANNs, but faces difficulties to keep peak performance at high sparsity levels. The Cannistraci-Hebb training (CHT) is a brain-inspired method for growing connectivity in DST. CHT leverages a gradient-free, topology-driven link regrowth, which has shown ultra-sparse (1% connectivity or lower) advantage across various tasks compared to fully connected networks. Yet, CHT suffers two main drawbacks: (i) its time complexity is O(Nd^3) - N node network size, d node degree - hence it can apply only to ultra-sparse networks. (ii) it selects top link prediction scores, which is inappropriate for the early training epochs, when the network presents unreliable connections. We propose a GPU-friendly approximation of the CH link predictor, which reduces the computational complexity to O(N^3), enabling a fast implementation of CHT in large-scale models. We introduce the Cannistraci-Hebb training soft rule (CHTs), which adopts a strategy for sampling connections in both link removal and regrowth, balancing the exploration and exploitation of network topology. To improve performance, we integrate CHTs with a sigmoid gradual density decay (CHTss). Empirical results show that, using 1% of connections, CHTs outperforms fully connected networks in MLP on visual classification tasks, compressing some networks to < 30% nodes. Using 5% of the connections, CHTss outperforms fully connected networks in two Transformer-based machine translation tasks. Using 30% of the connections, CHTss achieves superior performance compared to other dynamic sparse training methods in language modeling, and it surpasses the fully connected counterpart in zero-shot evaluations.