 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Attention with Basis Decomposition
Oct 02, 2025Attention is a core operation in large language models (LLMs) and vision-language models (VLMs). We present BD Attention (BDA), the first lossless algorithmic reformulation of attention. BDA is enabled by a simple matrix identity from Basis Decomposition (BD), which restructures multi-head projections into a compact form while preserving exact outputs. Unlike I/O-aware system optimizations such as FlashAttention, BDA provides a mathematically guaranteed acceleration that is architecture-agnostic. On DeepSeek-V2-Lite (16B, FP16), BDA requires only 4s of offline preparation with no retraining required and, on modern GPUs, achieves 32% faster key/value projections and 25% smaller weights, while increasing end-to-end perplexity (PPL) by just 0.02% (FP16) or 0.0004% (FP32), a negligible effect on model performance. These results position BDA as the first theoretically exact method for lossless attention acceleration that is complementary to existing engineering-level optimizations. Our code is available at https://github.com/abcbdf/basis-decomposition-official.
Pivoting Factorization: A Compact Meta Low-Rank Representation of Sparsity for Efficient Inference in Large Language Models
Jan 31, 2025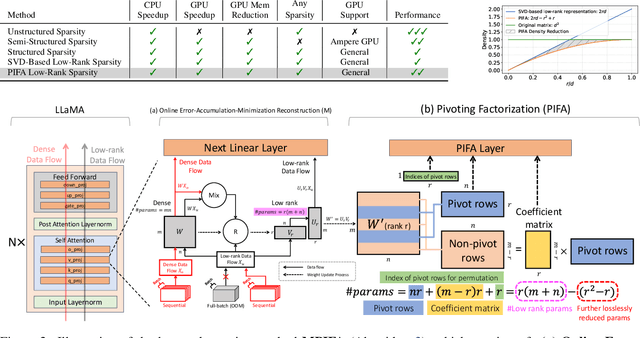
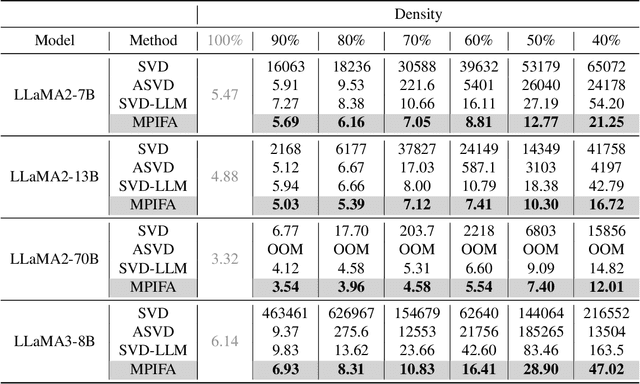
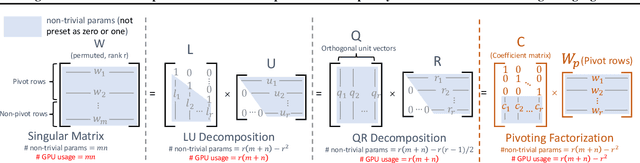
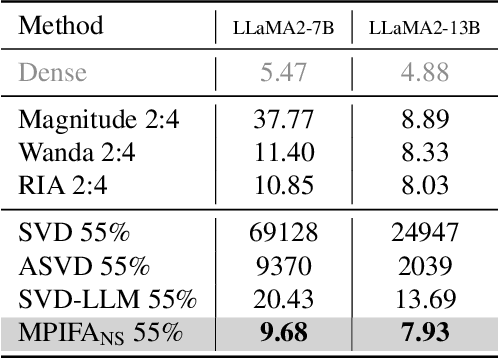
The rapid growth of Large Language Models has driven demand for effective model compression techniques to reduce memory and computation costs. Low-rank pruning has gained attention for its tensor coherence and GPU compatibility across all densities. However, low-rank pruning has struggled to match the performance of semi-structured pruning, often doubling perplexity (PPL) at similar densities. In this paper, we propose Pivoting Factorization (PIFA), a novel lossless meta low-rank representation that unsupervisedly learns a compact form of any low-rank representation, effectively eliminating redundant information. PIFA identifies pivot rows (linearly independent rows) and expresses non-pivot rows as linear combinations, achieving an additional 24.2\% memory savings and 24.6\% faster inference over low-rank layers at r/d = 0.5, thereby significantly enhancing performance at the same density. To mitigate the performance degradation caused by low-rank pruning, we introduce a novel, retraining-free low-rank reconstruction method that minimizes error accumulation (M). MPIFA, combining M and PIFA into an end-to-end framework, significantly outperforms existing low-rank pruning methods and, for the first time, achieves performance comparable to semi-structured pruning, while surpassing it in GPU efficiency and compatibility.
Brain-inspired sparse training enables Transformers and LLMs to perform as fully connected
Jan 31, 2025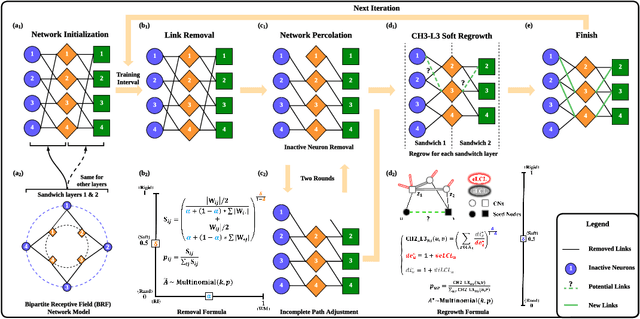
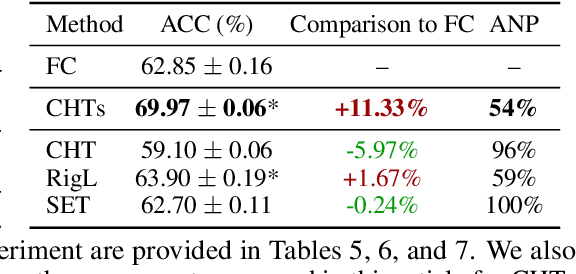
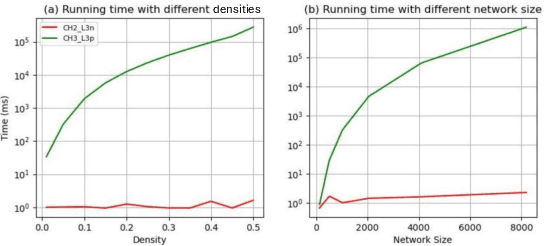
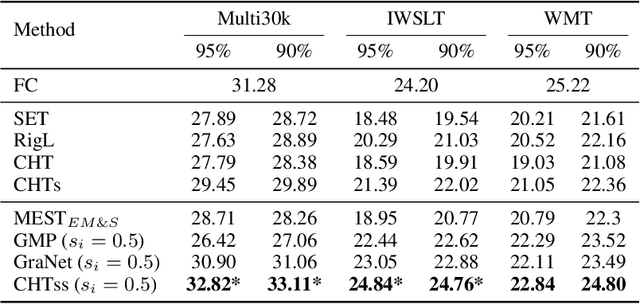
This study aims to enlarge our current knowledge on application of brain-inspired network science principles for training artificial neural networks (ANNs) with sparse connectivity. Dynamic sparse training (DST) can reduce the computational demands in ANNs, but faces difficulties to keep peak performance at high sparsity levels. The Cannistraci-Hebb training (CHT) is a brain-inspired method for growing connectivity in DST. CHT leverages a gradient-free, topology-driven link regrowth, which has shown ultra-sparse (1% connectivity or lower) advantage across various tasks compared to fully connected networks. Yet, CHT suffers two main drawbacks: (i) its time complexity is O(Nd^3) - N node network size, d node degree - hence it can apply only to ultra-sparse networks. (ii) it selects top link prediction scores, which is inappropriate for the early training epochs, when the network presents unreliable connections. We propose a GPU-friendly approximation of the CH link predictor, which reduces the computational complexity to O(N^3), enabling a fast implementation of CHT in large-scale models. We introduce the Cannistraci-Hebb training soft rule (CHTs), which adopts a strategy for sampling connections in both link removal and regrowth, balancing the exploration and exploitation of network topology. To improve performance, we integrate CHTs with a sigmoid gradual density decay (CHTss). Empirical results show that, using 1% of connections, CHTs outperforms fully connected networks in MLP on visual classification tasks, compressing some networks to < 30% nodes. Using 5% of the connections, CHTss outperforms fully connected networks in two Transformer-based machine translation tasks. Using 30% of the connections, CHTss achieves superior performance compared to other dynamic sparse training methods in language modeling, and it surpasses the fully connected counterpart in zero-shot evaluations.
Sparse Spectral Training and Inference on Euclidean and Hyperbolic Neural Networks
May 24, 2024The growing computational demands posed by increasingly number of neural network's parameters necessitate low-memory-consumption training approaches. Previous memory reduction techniques, such as Low-Rank Adaptation (LoRA) and ReLoRA, suffer from the limitation of low rank and saddle point issues, particularly during intensive tasks like pre-training. In this paper, we propose Sparse Spectral Training (SST), an advanced training methodology that updates all singular values and selectively updates singular vectors of network weights, thereby optimizing resource usage while closely approximating full-rank training. SST refines the training process by employing a targeted updating strategy for singular vectors, which is determined by a multinomial sampling method weighted by the significance of the singular values, ensuring both high performance and memory reduction. Through comprehensive testing on both Euclidean and hyperbolic neural networks across various tasks, including natural language generation, machine translation, node classification and link prediction, SST demonstrates its capability to outperform existing memory reduction training methods and is comparable with full-rank training in some cases. On OPT-125M, with rank equating to 8.3% of embedding dimension, SST reduces the perplexity gap to full-rank training by 67.6%, demonstrating a significant reduction of the performance loss with prevalent low-rank methods. This approach offers a strong alternative to traditional training techniques, paving the way for more efficient and scalable neural network training solutions.