 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforced Attention Learning
Feb 04, 2026Post-training with Reinforcement Learning (RL) has substantially improved reasoning in Large Language Models (LLMs) via test-time scaling. However, extending this paradigm to Multimodal LLMs (MLLMs) through verbose rationales yields limited gains for perception and can even degrade performance. We propose Reinforced Attention Learning (RAL), a policy-gradient framework that directly optimizes internal attention distributions rather than output token sequences. By shifting optimization from what to generate to where to attend, RAL promotes effective information allocation and improved grounding in complex multimodal inputs. Experiments across diverse image and video benchmarks show consistent gains over GRPO and other baselines. We further introduce On-Policy Attention Distillation, demonstrating that transferring latent attention behaviors yields stronger cross-modal alignment than standard knowledge distillation. Our results position attention policies as a principled and general alternative for multimodal post-training.
Adapting Decoder-Based Language Models for Diverse Encoder Downstream Tasks
Mar 04, 2025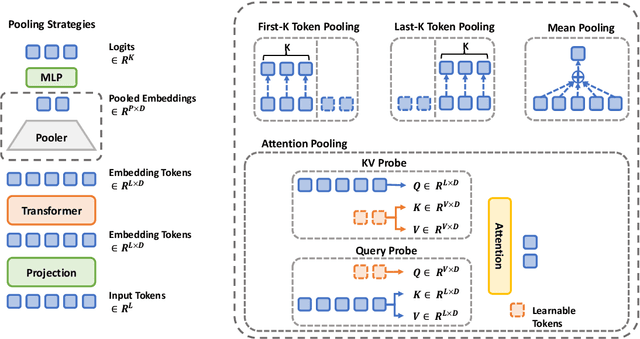
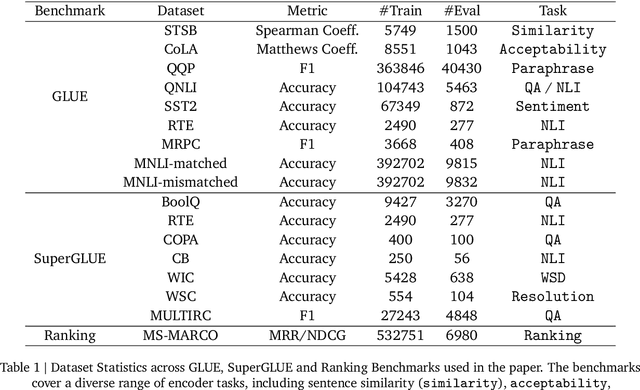
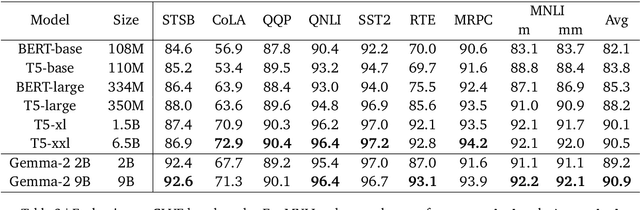
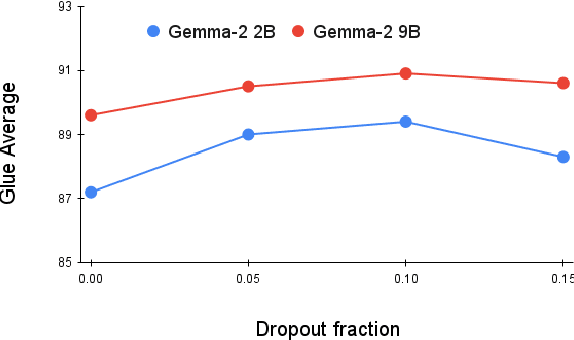
Decoder-based transformers, while revolutionizing language modeling and scaling to immense sizes, have not completely overtaken encoder-heavy architectures in natural language processing. Specifically, encoder-only models remain dominant in tasks like classification, regression, and ranking. This is primarily due to the inherent structure of decoder-based models, which limits their direct applicability to these tasks. In this paper, we introduce Gemma Encoder, adapting the powerful Gemma decoder model to an encoder architecture, thereby unlocking its potential for a wider range of non-generative applications. To optimize the adaptation from decoder to encoder, we systematically analyze various pooling strategies, attention mechanisms, and hyperparameters (e.g., dropout rate). Furthermore, we benchmark Gemma Encoder against established approaches on the GLUE benchmarks, and MS MARCO ranking benchmark, demonstrating its effectiveness and versatility.
ActionPiece: Contextually Tokenizing Action Sequences for Generative Recommendation
Feb 19, 2025Generative recommendation (GR) is an emerging paradigm where user actions are tokenized into discrete token patterns and autoregressively generated as predictions. However, existing GR models tokenize each action independently, assigning the same fixed tokens to identical actions across all sequences without considering contextual relationships. This lack of context-awareness can lead to suboptimal performance, as the same action may hold different meanings depending on its surrounding context. To address this issue, we propose ActionPiece to explicitly incorporate context when tokenizing action sequences. In ActionPiece, each action is represented as a set of item features, which serve as the initial tokens. Given the action sequence corpora, we construct the vocabulary by merging feature patterns as new tokens, based on their co-occurrence frequency both within individual sets and across adjacent sets. Considering the unordered nature of feature sets, we further introduce set permutation regularization, which produces multiple segmentations of action sequences with the same semantics. Experiments on public datasets demonstrate that ActionPiece consistently outperforms existing action tokenization methods, improving NDCG@$10$ by $6.00\%$ to $12.82\%$.
How to Train Data-Efficient LLMs
Feb 15, 2024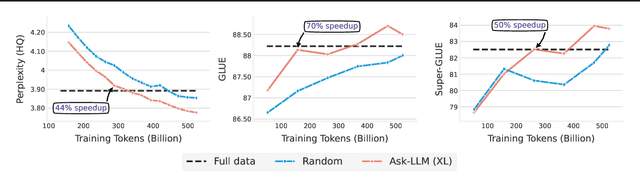
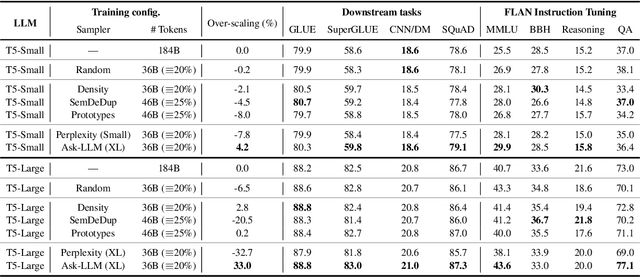
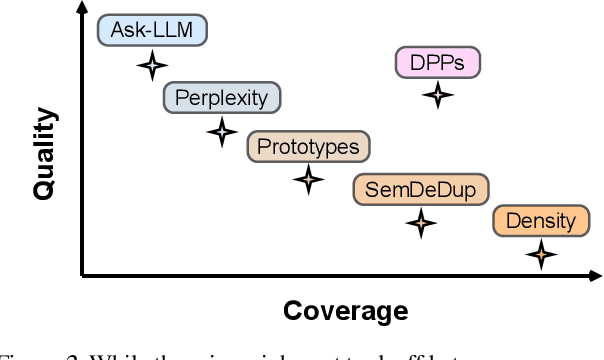

The training of large language models (LLMs) is expensive. In this paper, we study data-efficient approaches for pre-training LLMs, i.e., techniques that aim to optimize the Pareto frontier of model quality and training resource/data consumption. We seek to understand the tradeoffs associated with data selection routines based on (i) expensive-to-compute data-quality estimates, and (ii) maximization of coverage and diversity-based measures in the feature space. Our first technique, Ask-LLM, leverages the zero-shot reasoning capabilities of instruction-tuned LLMs to directly assess the quality of a training example. To target coverage, we propose Density sampling, which models the data distribution to select a diverse sample. In our comparison of 19 samplers, involving hundreds of evaluation tasks and pre-training runs, we find that Ask-LLM and Density are the best methods in their respective categories. Coverage sampling can recover the performance of the full data, while models trained on Ask-LLM data consistently outperform full-data training -- even when we reject 90% of the original dataset, while converging up to 70% faster.
Leveraging LLMs for Synthesizing Training Data Across Many Languages in Multilingual Dense Retrieval
Nov 10, 2023



Dense retrieval models have predominantly been studied for English, where models have shown great success, due to the availability of human-labeled training pairs. However, there has been limited success for multilingual retrieval so far, as training data is uneven or scarcely available across multiple languages. Synthetic training data generation is promising (e.g., InPars or Promptagator), but has been investigated only for English. Therefore, to study model capabilities across both cross-lingual and monolingual retrieval tasks, we develop SWIM-IR, a synthetic retrieval training dataset containing 33 (high to very-low resource) languages for training multilingual dense retrieval models without requiring any human supervision. To construct SWIM-IR, we propose SAP (summarize-then-ask prompting), where the large language model (LLM) generates a textual summary prior to the query generation step. SAP assists the LLM in generating informative queries in the target language. Using SWIM-IR, we explore synthetic fine-tuning of multilingual dense retrieval models and evaluate them robustly on three retrieval benchmarks: XOR-Retrieve (cross-lingual), XTREME-UP (cross-lingual) and MIRACL (monolingual). Our models, called SWIM-X, are competitive with human-supervised dense retrieval models, e.g., mContriever, finding that SWIM-IR can cheaply substitute for expensive human-labeled retrieval training data.
Farzi Data: Autoregressive Data Distillation
Oct 15, 2023



We study data distillation for auto-regressive machine learning tasks, where the input and output have a strict left-to-right causal structure. More specifically, we propose Farzi, which summarizes an event sequence dataset into a small number of synthetic sequences -- Farzi Data -- which are optimized to maintain (if not improve) model performance compared to training on the full dataset. Under the hood, Farzi conducts memory-efficient data distillation by (i) deriving efficient reverse-mode differentiation of the Adam optimizer by leveraging Hessian-Vector Products; and (ii) factorizing the high-dimensional discrete event-space into a latent-space which provably promotes implicit regularization. Empirically, for sequential recommendation and language modeling tasks, we are able to achieve 98-120% of downstream full-data performance when training state-of-the-art models on Farzi Data of size as little as 0.1% of the original dataset. Notably, being able to train better models with significantly less data sheds light on the design of future large auto-regressive models, and opens up new opportunities to further scale up model and data sizes.
Do LLMs Understand User Preferences? Evaluating LLMs On User Rating Prediction
May 10, 2023Large Language Models (LLMs) have demonstrated exceptional capabilities in generalizing to new tasks in a zero-shot or few-shot manner. However, the extent to which LLMs can comprehend user preferences based on their previous behavior remains an emerging and still unclear research question. Traditionally, Collaborative Filtering (CF) has been the most effective method for these tasks, predominantly relying on the extensive volume of rating data. In contrast, LLMs typically demand considerably less data while maintaining an exhaustive world knowledge about each item, such as movies or products. In this paper, we conduct a thorough examination of both CF and LLMs within the classic task of user rating prediction, which involves predicting a user's rating for a candidate item based on their past ratings. We investigate various LLMs in different sizes, ranging from 250M to 540B parameters and evaluate their performance in zero-shot, few-shot, and fine-tuning scenarios. We conduct comprehensive analysis to compare between LLMs and strong CF methods, and find that zero-shot LLMs lag behind traditional recommender models that have the access to user interaction data, indicating the importance of user interaction data. However, through fine-tuning, LLMs achieve comparable or even better performance with only a small fraction of the training data, demonstrating their potential through data efficiency.
WikiWeb2M: A Page-Level Multimodal Wikipedia Dataset
May 09, 2023


Webpages have been a rich resource for language and vision-language tasks. Yet only pieces of webpages are kept: image-caption pairs, long text articles, or raw HTML, never all in one place. Webpage tasks have resultingly received little attention and structured image-text data underused. To study multimodal webpage understanding, we introduce the Wikipedia Webpage 2M (WikiWeb2M) suite; the first to retain the full set of images, text, and structure data available in a page. WikiWeb2M can be used for tasks like page description generation, section summarization, and contextual image captioning.
A Suite of Generative Tasks for Multi-Level Multimodal Webpage Understanding
May 05, 2023Webpages have been a rich, scalable resource for vision-language and language only tasks. Yet only pieces of webpages are kept: image-caption pairs, long text articles, or raw HTML, never all in one place. Webpage tasks have resultingly received little attention and structured image-text data left underused. To study multimodal webpage understanding, we introduce the Wikipedia Webpage suite (WikiWeb2M) of 2M pages. We verify its utility on three generative tasks: page description generation, section summarization, and contextual image captioning. We design a novel attention mechanism Prefix Global, which selects the most relevant image and text content as global tokens to attend to the rest of the webpage for context. By using page structure to separate such tokens, it performs better than full attention with lower computational complexity. Experiments show that the new annotations from WikiWeb2M improve task performance compared to data from prior work. We also include ablations on sequence length, input features, and model size.
HYRR: Hybrid Infused Reranking for Passage Retrieval
Dec 20, 2022

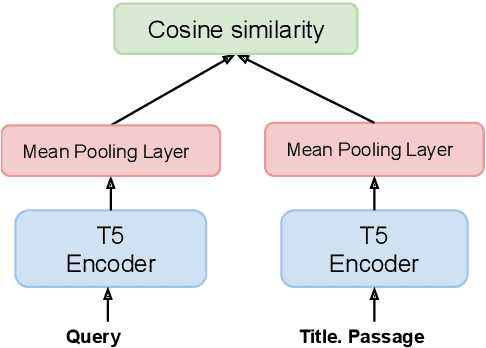

We present Hybrid Infused Reranking for Passages Retrieval (HYRR), a framework for training rerankers based on a hybrid of BM25 and neural retrieval models. Retrievers based on hybrid models have been shown to outperform both BM25 and neural models alone. Our approach exploits this improved performance when training a reranker, leading to a robust reranking model. The reranker, a cross-attention neural model, is shown to be robust to different first-stage retrieval systems, achieving better performance than rerankers simply trained upon the first-stage retrievers in the multi-stage systems. We present evaluations on a supervised passage retrieval task using MS MARCO and zero-shot retrieval tasks using BEIR. The empirical results show strong performance on both evaluations.