 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgenticTagger: Structured Item Representation for Recommendation with LLM Agents
Feb 05, 2026High-quality representations are a core requirement for effective recommendation. In this work, we study the problem of LLM-based descriptor generation, i.e., keyphrase-like natural language item representation generation frameworks with minimal constraints on downstream applications. We propose AgenticTagger, a framework that queries LLMs for representing items with sequences of text descriptors. However, open-ended generation provides little control over the generation space, leading to high cardinality, low-performance descriptors that renders downstream modeling challenging. To this end, AgenticTagger features two core stages: (1) a vocabulary building stage where a set of hierarchical, low-cardinality, and high-quality descriptors is identified, and (2) a vocabulary assignment stage where LLMs assign in-vocabulary descriptors to items. To effectively and efficiently ground vocabulary in the item corpus of interest, we design a multi-agent reflection mechanism where an architect LLM iteratively refines the vocabulary guided by parallelized feedback from annotator LLMs that validates the vocabulary against item data. Experiments on public and private data show AgenticTagger brings consistent improvements across diverse recommendation scenarios, including generative and term-based retrieval, ranking, and controllability-oriented, critique-based recommendation.
PACEvolve: Enabling Long-Horizon Progress-Aware Consistent Evolution
Jan 15, 2026Large Language Models (LLMs) have emerged as powerful operators for evolutionary search, yet the design of efficient search scaffolds remains ad hoc. While promising, current LLM-in-the-loop systems lack a systematic approach to managing the evolutionary process. We identify three distinct failure modes: Context Pollution, where experiment history biases future candidate generation; Mode Collapse, where agents stagnate in local minima due to poor exploration-exploitation balance; and Weak Collaboration, where rigid crossover strategies fail to leverage parallel search trajectories effectively. We introduce Progress-Aware Consistent Evolution (PACEvolve), a framework designed to robustly govern the agent's context and search dynamics, to address these challenges. PACEvolve combines hierarchical context management (HCM) with pruning to address context pollution; momentum-based backtracking (MBB) to escape local minima; and a self-adaptive sampling policy that unifies backtracking and crossover for dynamic search coordination (CE), allowing agents to balance internal refinement with cross-trajectory collaboration. We demonstrate that PACEvolve provides a systematic path to consistent, long-horizon self-improvement, achieving state-of-the-art results on LLM-SR and KernelBench, while discovering solutions surpassing the record on Modded NanoGPT.
ActionPiece: Contextually Tokenizing Action Sequences for Generative Recommendation
Feb 19, 2025Generative recommendation (GR) is an emerging paradigm where user actions are tokenized into discrete token patterns and autoregressively generated as predictions. However, existing GR models tokenize each action independently, assigning the same fixed tokens to identical actions across all sequences without considering contextual relationships. This lack of context-awareness can lead to suboptimal performance, as the same action may hold different meanings depending on its surrounding context. To address this issue, we propose ActionPiece to explicitly incorporate context when tokenizing action sequences. In ActionPiece, each action is represented as a set of item features, which serve as the initial tokens. Given the action sequence corpora, we construct the vocabulary by merging feature patterns as new tokens, based on their co-occurrence frequency both within individual sets and across adjacent sets. Considering the unordered nature of feature sets, we further introduce set permutation regularization, which produces multiple segmentations of action sequences with the same semantics. Experiments on public datasets demonstrate that ActionPiece consistently outperforms existing action tokenization methods, improving NDCG@$10$ by $6.00\%$ to $12.82\%$.
How to Train Data-Efficient LLMs
Feb 15, 2024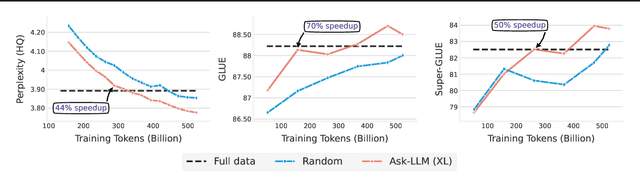
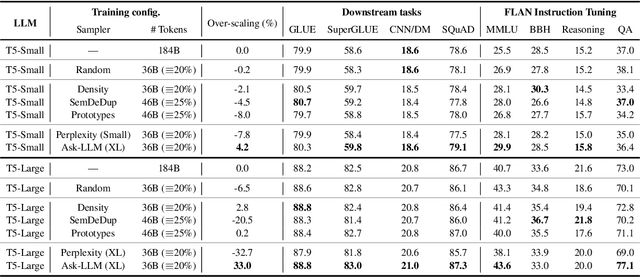
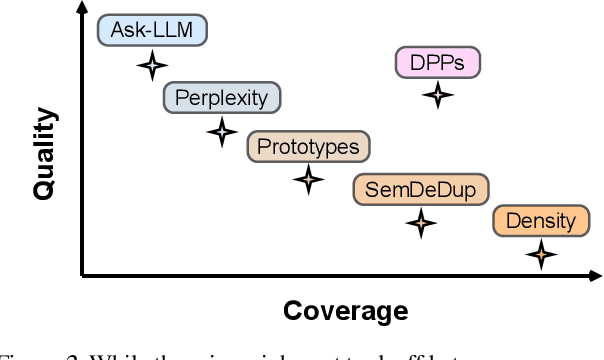

The training of large language models (LLMs) is expensive. In this paper, we study data-efficient approaches for pre-training LLMs, i.e., techniques that aim to optimize the Pareto frontier of model quality and training resource/data consumption. We seek to understand the tradeoffs associated with data selection routines based on (i) expensive-to-compute data-quality estimates, and (ii) maximization of coverage and diversity-based measures in the feature space. Our first technique, Ask-LLM, leverages the zero-shot reasoning capabilities of instruction-tuned LLMs to directly assess the quality of a training example. To target coverage, we propose Density sampling, which models the data distribution to select a diverse sample. In our comparison of 19 samplers, involving hundreds of evaluation tasks and pre-training runs, we find that Ask-LLM and Density are the best methods in their respective categories. Coverage sampling can recover the performance of the full data, while models trained on Ask-LLM data consistently outperform full-data training -- even when we reject 90% of the original dataset, while converging up to 70% faster.
Farzi Data: Autoregressive Data Distillation
Oct 15, 2023



We study data distillation for auto-regressive machine learning tasks, where the input and output have a strict left-to-right causal structure. More specifically, we propose Farzi, which summarizes an event sequence dataset into a small number of synthetic sequences -- Farzi Data -- which are optimized to maintain (if not improve) model performance compared to training on the full dataset. Under the hood, Farzi conducts memory-efficient data distillation by (i) deriving efficient reverse-mode differentiation of the Adam optimizer by leveraging Hessian-Vector Products; and (ii) factorizing the high-dimensional discrete event-space into a latent-space which provably promotes implicit regularization. Empirically, for sequential recommendation and language modeling tasks, we are able to achieve 98-120% of downstream full-data performance when training state-of-the-art models on Farzi Data of size as little as 0.1% of the original dataset. Notably, being able to train better models with significantly less data sheds light on the design of future large auto-regressive models, and opens up new opportunities to further scale up model and data sizes.
Unified Embedding: Battle-Tested Feature Representations for Web-Scale ML Systems
May 20, 2023Learning high-quality feature embeddings efficiently and effectively is critical for the performance of web-scale machine learning systems. A typical model ingests hundreds of features with vocabularies on the order of millions to billions of tokens. The standard approach is to represent each feature value as a d-dimensional embedding, introducing hundreds of billions of parameters for extremely high-cardinality features. This bottleneck has led to substantial progress in alternative embedding algorithms. Many of these methods, however, make the assumption that each feature uses an independent embedding table. This work introduces a simple yet highly effective framework, Feature Multiplexing, where one single representation space is used across many different categorical features. Our theoretical and empirical analysis reveals that multiplexed embeddings can be decomposed into components from each constituent feature, allowing models to distinguish between features. We show that multiplexed representations lead to Pareto-optimal parameter-accuracy tradeoffs for three public benchmark datasets. Further, we propose a highly practical approach called Unified Embedding with three major benefits: simplified feature configuration, strong adaptation to dynamic data distributions, and compatibility with modern hardware. Unified embedding gives significant improvements in offline and online metrics compared to highly competitive baselines across five web-scale search, ads, and recommender systems, where it serves billions of users across the world in industry-leading products.
Do LLMs Understand User Preferences? Evaluating LLMs On User Rating Prediction
May 10, 2023



Large Language Models (LLMs) have demonstrated exceptional capabilities in generalizing to new tasks in a zero-shot or few-shot manner. However, the extent to which LLMs can comprehend user preferences based on their previous behavior remains an emerging and still unclear research question. Traditionally, Collaborative Filtering (CF) has been the most effective method for these tasks, predominantly relying on the extensive volume of rating data. In contrast, LLMs typically demand considerably less data while maintaining an exhaustive world knowledge about each item, such as movies or products. In this paper, we conduct a thorough examination of both CF and LLMs within the classic task of user rating prediction, which involves predicting a user's rating for a candidate item based on their past ratings. We investigate various LLMs in different sizes, ranging from 250M to 540B parameters and evaluate their performance in zero-shot, few-shot, and fine-tuning scenarios. We conduct comprehensive analysis to compare between LLMs and strong CF methods, and find that zero-shot LLMs lag behind traditional recommender models that have the access to user interaction data, indicating the importance of user interaction data. However, through fine-tuning, LLMs achieve comparable or even better performance with only a small fraction of the training data, demonstrating their potential through data efficiency.
Deep Hash Embedding for Large-Vocab Categorical Feature Representations
Oct 21, 2020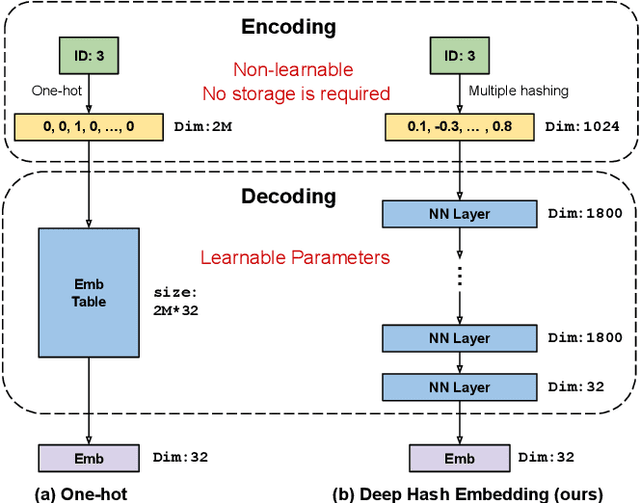

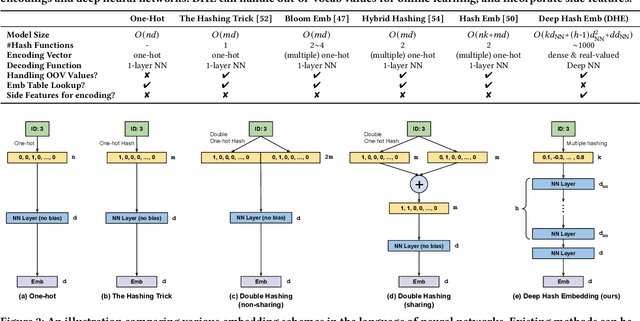
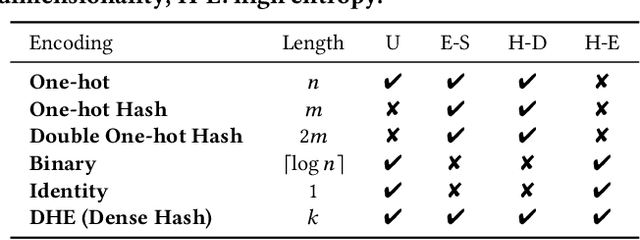
Embedding learning for large-vocabulary categorical features (e.g. user/item IDs, and words) is crucial for deep learning, and especially neural models for recommendation systems and natural language understanding tasks. Typically, the model creates a huge embedding table that each row represents a dedicated embedding vector for every feature value. In practice, to handle new (i.e., out-of-vocab) feature values and reduce the storage cost, the hashing trick is often adopted, that randomly maps feature values to a smaller number of hashing buckets. Essentially, thess embedding methods can be viewed as 1-layer wide neural networks with one-hot encodings. In this paper, we propose an alternative embedding framework Deep Hash Embedding (DHE), with non-one-hot encodings and a deep neural network (embedding network) to compute embeddings on the fly without having to store them. DHE first encodes the feature value to a dense vector with multiple hashing functions and then applies a DNN to generate the embedding. DHE is collision-free as the dense hashing encodings are unique identifiers for both in-vocab and out-of-vocab feature values. The encoding module is deterministic, non-learnable, and free of storage, while the embedding network is updated during the training time to memorize embedding information. Empirical results show that DHE outperforms state-of-the-art hashing-based embedding learning algorithms, and achieves comparable AUC against the standard one-hot encoding, with significantly smaller model sizes. Our work sheds light on design of DNN-based alternative embedding schemes for categorical features without using embedding table lookup.
CosRec: 2D Convolutional Neural Networks for Sequential Recommendation
Aug 27, 2019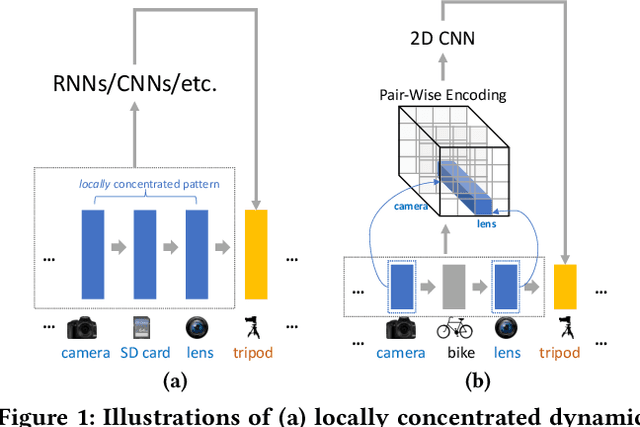
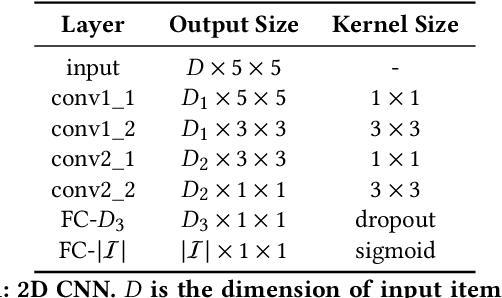
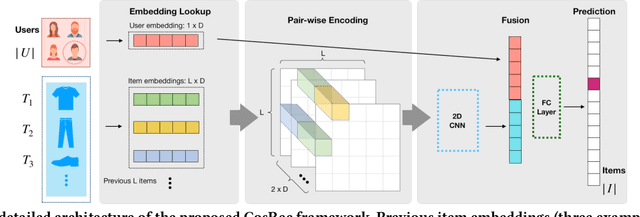
Sequential patterns play an important role in building modern recommender systems. To this end, several recommender systems have been built on top of Markov Chains and Recurrent Models (among others). Although these sequential models have proven successful at a range of tasks, they still struggle to uncover complex relationships nested in user purchase histories. In this paper, we argue that modeling pairwise relationships directly leads to an efficient representation of sequential features and captures complex item correlations. Specifically, we propose a 2D convolutional network for sequential recommendation (CosRec). It encodes a sequence of items into a three-way tensor; learns local features using 2D convolutional filters; and aggregates high-order interactions in a feedforward manner. Quantitative results on two public datasets show that our method outperforms both conventional methods and recent sequence-based approaches, achieving state-of-the-art performance on various evaluation metrics.
Complete the Look: Scene-based Complementary Product Recommendation
Dec 04, 2018

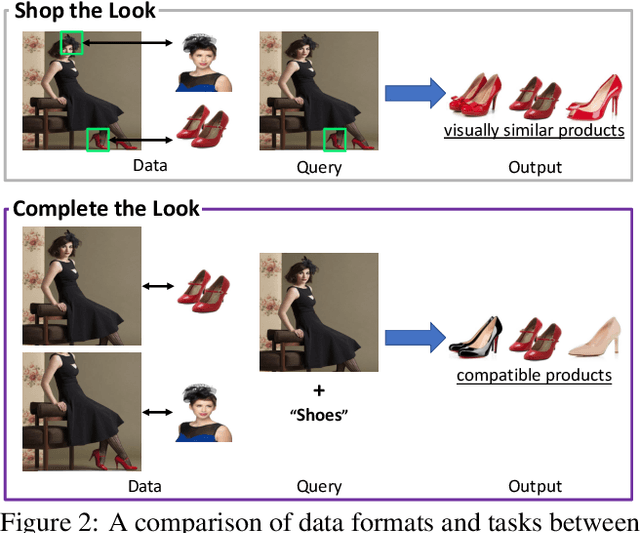
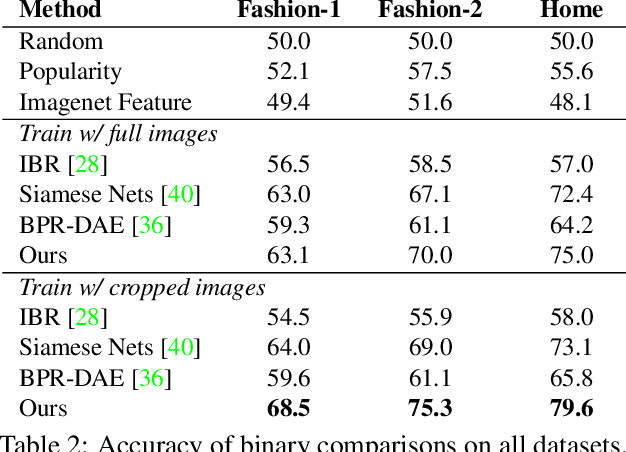
Modeling fashion compatibility is challenging due to its complexity and subjectivity. Existing work focuses on predicting compatibility between product images (e.g. an image containing a t-shirt and an image containing a pair of jeans). However, these approaches ignore real-world 'scene' images (e.g. selfies); such images are hard to deal with due to their complexity, clutter, variations in lighting and pose (etc.) but on the other hand could potentially provide key context (e.g. the user's body type, or the season) for making more accurate recommendations. In this work, we propose a new task called 'Complete the Look', which seeks to recommend visually compatible products based on scene images. We design an approach to extract training data for this task, and propose a novel way to learn the scene-product compatibility from fashion or interior design images. Our approach measures compatibility both globally and locally via CNNs and attention mechanisms. Extensive experiments show that our method achieves significant performance gains over alternative systems. Human evaluation and qualitative analysis are also conducted to further understand model behavior. We hope this work could lead to useful applications which link large corpora of real-world scenes with shoppable products.