 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpowering Long-tail Item Recommendation through Cross Decoupling Network (CDN)
Oct 25, 2022Recommenders provide personalized content recommendations to users. They often suffer from highly skewed long-tail item distributions, with a small fraction of the items receiving most of the user feedback. This hurts model quality especially for the slices without much supervision. Existing work in both academia and industry mainly focuses on re-balancing strategies (e.g., up-sampling and up-weighting), leveraging content features, and transfer learning. However, there still lacks of a deeper understanding of how the long-tail distribution influences the recommendation performance. In this work, we theoretically demonstrate that the prediction of user preference is biased under the long-tail distributions. This bias comes from the discrepancy of both the prior and conditional probabilities between training data and test data. Most existing methods mainly attempt to reduce the bias from the prior perspective, which ignores the discrepancy in the conditional probability. This leads to a severe forgetting issue and results in suboptimal performance. To address the problem, we design a novel Cross Decoupling Network (CDN) to reduce the differences in both prior and conditional probabilities. Specifically, CDN (i) decouples the learning process of memorization and generalization on the item side through a mixture-of-expert structure; (ii) decouples the user samples from different distributions through a regularized bilateral branch network. Finally, a novel adapter is introduced to aggregate the decoupled vectors, and softly shift the training attention to tail items. Extensive experimental results show that CDN significantly outperforms state-of-the-art approaches on popular benchmark datasets, leading to an improvement in HR@50 (hit ratio) of 8.7\% for overall recommendation and 12.4\% for tail items.
Improving Multi-Task Generalization via Regularizing Spurious Correlation
May 19, 2022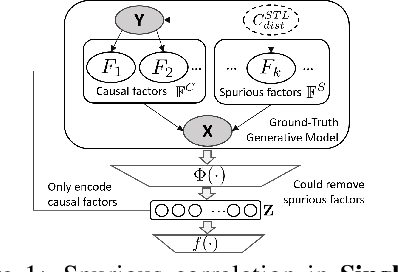
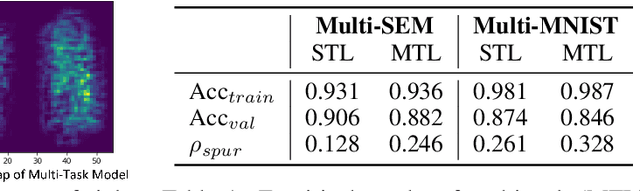
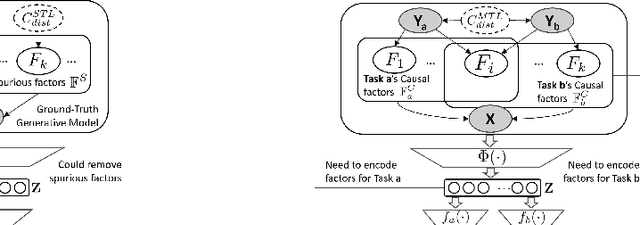
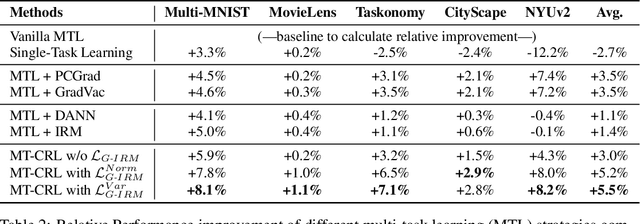
Multi-Task Learning (MTL) is a powerful learning paradigm to improve generalization performance via knowledge sharing. However, existing studies find that MTL could sometimes hurt generalization, especially when two tasks are less correlated. One possible reason that hurts generalization is spurious correlation, i.e., some knowledge is spurious and not causally related to task labels, but the model could mistakenly utilize them and thus fail when such correlation changes. In MTL setup, there exist several unique challenges of spurious correlation. First, the risk of having non-causal knowledge is higher, as the shared MTL model needs to encode all knowledge from different tasks, and causal knowledge for one task could be potentially spurious to the other. Second, the confounder between task labels brings in a different type of spurious correlation to MTL. We theoretically prove that MTL is more prone to taking non-causal knowledge from other tasks than single-task learning, and thus generalize worse. To solve this problem, we propose Multi-Task Causal Representation Learning framework, aiming to represent multi-task knowledge via disentangled neural modules, and learn which module is causally related to each task via MTL-specific invariant regularization. Experiments show that it could enhance MTL model's performance by 5.5% on average over Multi-MNIST, MovieLens, Taskonomy, CityScape, and NYUv2, via alleviating spurious correlation problem.
Deep Hash Embedding for Large-Vocab Categorical Feature Representations
Oct 21, 2020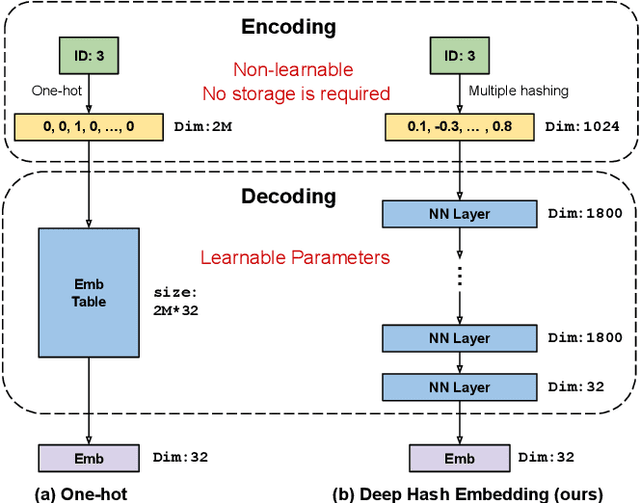

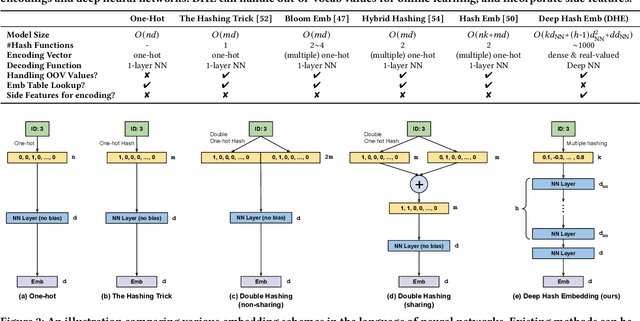
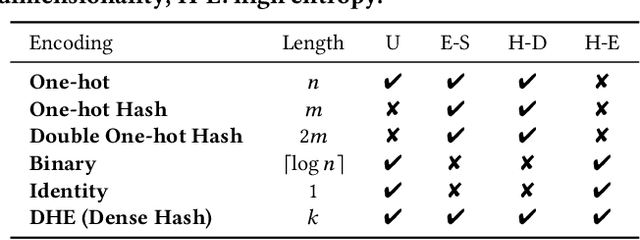
Embedding learning for large-vocabulary categorical features (e.g. user/item IDs, and words) is crucial for deep learning, and especially neural models for recommendation systems and natural language understanding tasks. Typically, the model creates a huge embedding table that each row represents a dedicated embedding vector for every feature value. In practice, to handle new (i.e., out-of-vocab) feature values and reduce the storage cost, the hashing trick is often adopted, that randomly maps feature values to a smaller number of hashing buckets. Essentially, thess embedding methods can be viewed as 1-layer wide neural networks with one-hot encodings. In this paper, we propose an alternative embedding framework Deep Hash Embedding (DHE), with non-one-hot encodings and a deep neural network (embedding network) to compute embeddings on the fly without having to store them. DHE first encodes the feature value to a dense vector with multiple hashing functions and then applies a DNN to generate the embedding. DHE is collision-free as the dense hashing encodings are unique identifiers for both in-vocab and out-of-vocab feature values. The encoding module is deterministic, non-learnable, and free of storage, while the embedding network is updated during the training time to memorize embedding information. Empirical results show that DHE outperforms state-of-the-art hashing-based embedding learning algorithms, and achieves comparable AUC against the standard one-hot encoding, with significantly smaller model sizes. Our work sheds light on design of DNN-based alternative embedding schemes for categorical features without using embedding table lookup.
Self-supervised Learning for Deep Models in Recommendations
Jul 25, 2020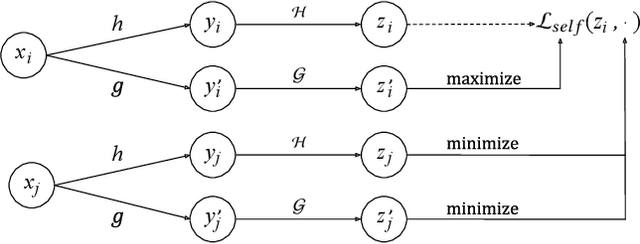
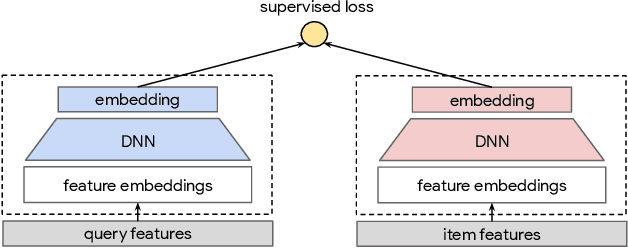
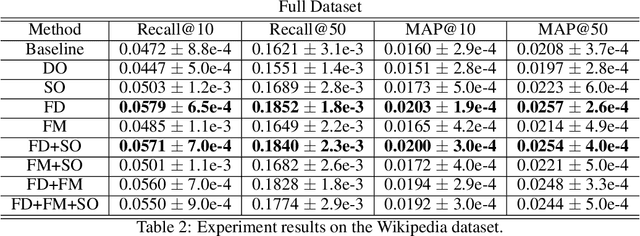
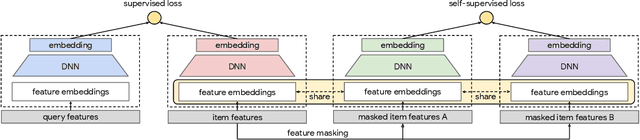
Large scale neural recommender models play a critical role in modern search and recommendation systems. To model large-vocab sparse categorical features, typical recommender models learn a joint embedding space for both queries and items. With millions to billions of items to choose from, the quality of learned embedding representations is crucial to provide high quality recommendations to users with various interests. Inspired by the recent success in self-supervised representation learning research in both computer vision and natural language understanding, we propose a multi-task self-supervised learning (SSL) framework for sparse neural models in recommendations. Furthermore, we propose two highly generalizable self-supervised learning tasks: (i) Feature Masking (FM) and (ii) Feature Dropout (FD) within the proposed SSL framework. We evaluate our framework using two large-scale datasets with ~500M and 1B training examples respectively. Our results demonstrate that the proposed framework outperforms baseline models and state-of-the-art spread-out regularization techniques in the context of retrieval. The SSL framework shows larger improvement with less supervision compared to the counterparts.