 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProSoftArena: Benchmarking Hierarchical Capabilities of Multimodal Agents in Professional Software Environments
Dec 30, 2025Multimodal agents are making rapid progress on general computer-use tasks, yet existing benchmarks remain largely confined to browsers and basic desktop applications, falling short in professional software workflows that dominate real-world scientific and industrial practice. To close this gap, we introduce ProSoftArena, a benchmark and platform specifically for evaluating multimodal agents in professional software environments. We establish the first capability hierarchy tailored to agent use of professional software and construct a benchmark of 436 realistic work and research tasks spanning 6 disciplines and 13 core professional applications. To ensure reliable and reproducible assessment, we build an executable real-computer environment with an execution-based evaluation framework and uniquely incorporate a human-in-the-loop evaluation paradigm. Extensive experiments show that even the best-performing agent attains only a 24.4\% success rate on L2 tasks and completely fails on L3 multi-software workflow. In-depth analysis further provides valuable insights for addressing current agent limitations and more effective design principles, paving the way to build more capable agents in professional software settings. This project is available at: https://prosoftarena.github.io.
Hierarchical Contextual Manifold Alignment for Structuring Latent Representations in Large Language Models
Feb 06, 2025The organization of latent token representations plays a crucial role in determining the stability, generalization, and contextual consistency of language models, yet conventional approaches to embedding refinement often rely on parameter modifications that introduce additional computational overhead. A hierarchical alignment method was introduced to restructure token embeddings without altering core model weights, ensuring that representational distributions maintained coherence across different linguistic contexts. Experimental evaluations demonstrated improvements in rare token retrieval, adversarial robustness, and long-range dependency tracking, highlighting the advantages of hierarchical structuring in mitigating inconsistencies in latent space organization. The comparative analysis against conventional fine-tuning and embedding perturbation methods revealed that hierarchical restructuring maintained computational efficiency while achieving measurable gains in representation quality. Structural refinements introduced through the alignment process resulted in improved contextual stability across varied linguistic tasks, reducing inconsistencies in token proximity relationships and enhancing interpretability in language generation. A detailed computational assessment confirmed that the realignment process introduced minimal inference overhead, ensuring that representational improvements did not compromise model efficiency. The findings reinforced the broader significance of structured representation learning, illustrating that hierarchical embedding modifications could serve as an effective strategy for refining latent space distributions while preserving pre-learned semantic associations.
Hiformer: Heterogeneous Feature Interactions Learning with Transformers for Recommender Systems
Nov 10, 2023



Learning feature interaction is the critical backbone to building recommender systems. In web-scale applications, learning feature interaction is extremely challenging due to the sparse and large input feature space; meanwhile, manually crafting effective feature interactions is infeasible because of the exponential solution space. We propose to leverage a Transformer-based architecture with attention layers to automatically capture feature interactions. Transformer architectures have witnessed great success in many domains, such as natural language processing and computer vision. However, there has not been much adoption of Transformer architecture for feature interaction modeling in industry. We aim at closing the gap. We identify two key challenges for applying the vanilla Transformer architecture to web-scale recommender systems: (1) Transformer architecture fails to capture the heterogeneous feature interactions in the self-attention layer; (2) The serving latency of Transformer architecture might be too high to be deployed in web-scale recommender systems. We first propose a heterogeneous self-attention layer, which is a simple yet effective modification to the self-attention layer in Transformer, to take into account the heterogeneity of feature interactions. We then introduce \textsc{Hiformer} (\textbf{H}eterogeneous \textbf{I}nteraction Trans\textbf{former}) to further improve the model expressiveness. With low-rank approximation and model pruning, \hiformer enjoys fast inference for online deployment. Extensive offline experiment results corroborates the effectiveness and efficiency of the \textsc{Hiformer} model. We have successfully deployed the \textsc{Hiformer} model to a real world large scale App ranking model at Google Play, with significant improvement in key engagement metrics (up to +2.66\%).
HyperFormer: Learning Expressive Sparse Feature Representations via Hypergraph Transformer
May 27, 2023Learning expressive representations for high-dimensional yet sparse features has been a longstanding problem in information retrieval. Though recent deep learning methods can partially solve the problem, they often fail to handle the numerous sparse features, particularly those tail feature values with infrequent occurrences in the training data. Worse still, existing methods cannot explicitly leverage the correlations among different instances to help further improve the representation learning on sparse features since such relational prior knowledge is not provided. To address these challenges, in this paper, we tackle the problem of representation learning on feature-sparse data from a graph learning perspective. Specifically, we propose to model the sparse features of different instances using hypergraphs where each node represents a data instance and each hyperedge denotes a distinct feature value. By passing messages on the constructed hypergraphs based on our Hypergraph Transformer (HyperFormer), the learned feature representations capture not only the correlations among different instances but also the correlations among features. Our experiments demonstrate that the proposed approach can effectively improve feature representation learning on sparse features.
Unified Embedding: Battle-Tested Feature Representations for Web-Scale ML Systems
May 20, 2023Learning high-quality feature embeddings efficiently and effectively is critical for the performance of web-scale machine learning systems. A typical model ingests hundreds of features with vocabularies on the order of millions to billions of tokens. The standard approach is to represent each feature value as a d-dimensional embedding, introducing hundreds of billions of parameters for extremely high-cardinality features. This bottleneck has led to substantial progress in alternative embedding algorithms. Many of these methods, however, make the assumption that each feature uses an independent embedding table. This work introduces a simple yet highly effective framework, Feature Multiplexing, where one single representation space is used across many different categorical features. Our theoretical and empirical analysis reveals that multiplexed embeddings can be decomposed into components from each constituent feature, allowing models to distinguish between features. We show that multiplexed representations lead to Pareto-optimal parameter-accuracy tradeoffs for three public benchmark datasets. Further, we propose a highly practical approach called Unified Embedding with three major benefits: simplified feature configuration, strong adaptation to dynamic data distributions, and compatibility with modern hardware. Unified embedding gives significant improvements in offline and online metrics compared to highly competitive baselines across five web-scale search, ads, and recommender systems, where it serves billions of users across the world in industry-leading products.
Empowering Long-tail Item Recommendation through Cross Decoupling Network (CDN)
Oct 25, 2022Recommenders provide personalized content recommendations to users. They often suffer from highly skewed long-tail item distributions, with a small fraction of the items receiving most of the user feedback. This hurts model quality especially for the slices without much supervision. Existing work in both academia and industry mainly focuses on re-balancing strategies (e.g., up-sampling and up-weighting), leveraging content features, and transfer learning. However, there still lacks of a deeper understanding of how the long-tail distribution influences the recommendation performance. In this work, we theoretically demonstrate that the prediction of user preference is biased under the long-tail distributions. This bias comes from the discrepancy of both the prior and conditional probabilities between training data and test data. Most existing methods mainly attempt to reduce the bias from the prior perspective, which ignores the discrepancy in the conditional probability. This leads to a severe forgetting issue and results in suboptimal performance. To address the problem, we design a novel Cross Decoupling Network (CDN) to reduce the differences in both prior and conditional probabilities. Specifically, CDN (i) decouples the learning process of memorization and generalization on the item side through a mixture-of-expert structure; (ii) decouples the user samples from different distributions through a regularized bilateral branch network. Finally, a novel adapter is introduced to aggregate the decoupled vectors, and softly shift the training attention to tail items. Extensive experimental results show that CDN significantly outperforms state-of-the-art approaches on popular benchmark datasets, leading to an improvement in HR@50 (hit ratio) of 8.7\% for overall recommendation and 12.4\% for tail items.
Surgical Gesture Recognition Based on Bidirectional Multi-Layer Independently RNN with Explainable Spatial Feature Extraction
May 02, 2021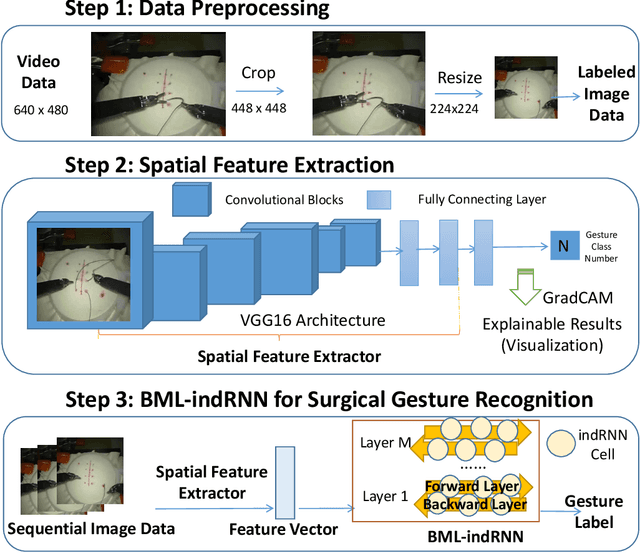

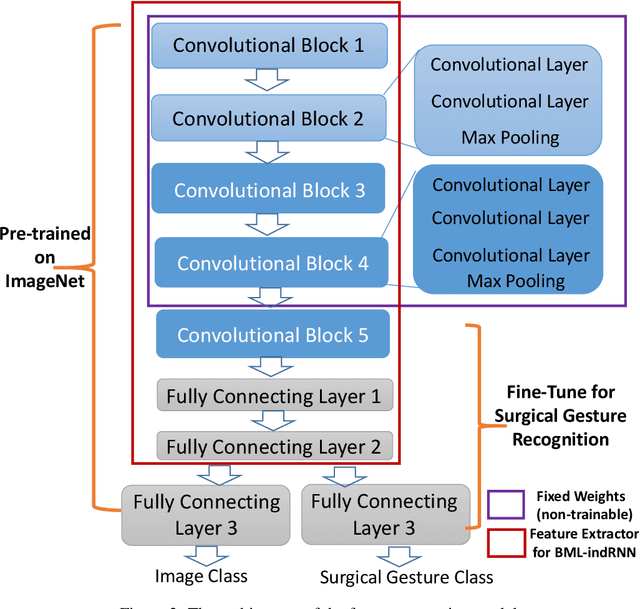

Minimally invasive surgery mainly consists of a series of sub-tasks, which can be decomposed into basic gestures or contexts. As a prerequisite of autonomic operation, surgical gesture recognition can assist motion planning and decision-making, and build up context-aware knowledge to improve the surgical robot control quality. In this work, we aim to develop an effective surgical gesture recognition approach with an explainable feature extraction process. A Bidirectional Multi-Layer independently RNN (BML-indRNN) model is proposed in this paper, while spatial feature extraction is implemented via fine-tuning of a Deep Convolutional Neural Network(DCNN) model constructed based on the VGG architecture. To eliminate the black-box effects of DCNN, Gradient-weighted Class Activation Mapping (Grad-CAM) is employed. It can provide explainable results by showing the regions of the surgical images that have a strong relationship with the surgical gesture classification results. The proposed method was evaluated based on the suturing task with data obtained from the public available JIGSAWS database. Comparative studies were conducted to verify the proposed framework. Results indicated that the testing accuracy for the suturing task based on our proposed method is 87.13%, which outperforms most of the state-of-the-art algorithms.
Real-time Surgical Environment Enhancement for Robot-Assisted Minimally Invasive Surgery Based on Super-Resolution
Nov 08, 2020

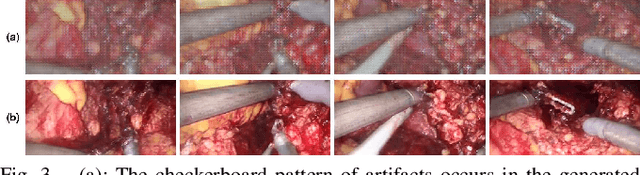

In Robot-Assisted Minimally Invasive Surgery (RAMIS), a camera assistant is normally required to control the position and zooming ratio of the laparoscope, following the surgeon's instructions. However, moving the laparoscope frequently may lead to unstable and suboptimal views, while the adjustment of zooming ratio may interrupt the workflow of the surgical operation. To this end, we propose a multi-scale Generative Adversarial Network (GAN)-based video super-resolution method to construct a framework for automatic zooming ratio adjustment. It can provide automatic real-time zooming for high-quality visualization of the Region Of Interest (ROI) during the surgical operation. In the pipeline of the framework, the Kernel Correlation Filter (KCF) tracker is used for tracking the tips of the surgical tools, while the Semi-Global Block Matching (SGBM) based depth estimation and Recurrent Neural Network (RNN)-based context-awareness are developed to determine the upscaling ratio for zooming. The framework is validated with the JIGSAW dataset and Hamlyn Centre Laparoscopic/Endoscopic Video Datasets, with results demonstrating its practicability.
DCN-M: Improved Deep & Cross Network for Feature Cross Learning in Web-scale Learning to Rank Systems
Aug 19, 2020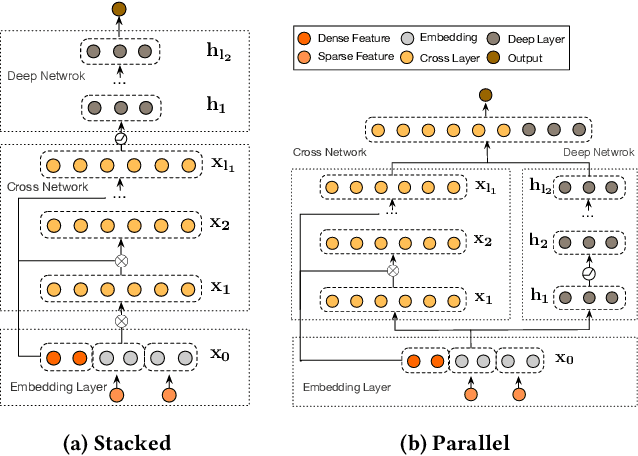
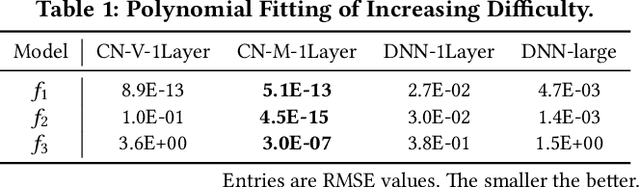
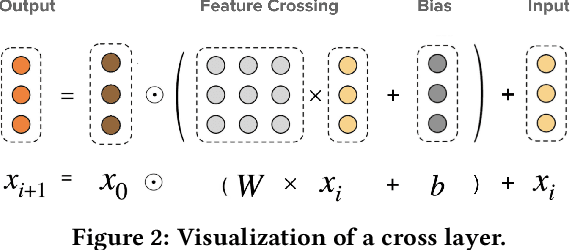

Learning effective feature crosses is the key behind building recommender systems. However, the sparse and large feature space requires exhaustive search to identify effective crosses. Deep & Cross Network (DCN) was proposed to automatically and efficiently learn bounded-degree predictive feature interactions. Unfortunately, in models that serve web-scale traffic with billions of training examples, DCN showed limited expressiveness in its cross network at learning more predictive feature interactions. Despite significant research progress made, many deep learning models in production still rely on traditional feed-forward neural networks to learn feature crosses inefficiently. In light of the pros/cons of DCN and existing feature interaction learning approaches, we propose an improved framework DCN-M to make DCN more practical in large-scale industrial settings. In a comprehensive experimental study with extensive hyper-parameter search and model tuning, we observed that DCN-M approaches outperform all the state-of-the-art algorithms on popular benchmark datasets. The improved DCN-M is more expressive yet remains cost efficient at feature interaction learning, especially when coupled with a mixture of low-rank architecture. DCN-M is simple, can be easily adopted as building blocks, and has delivered significant offline accuracy and online business metrics gains across many web-scale learning to rank systems.
Block Basis Factorization for Scalable Kernel Matrix Evaluation
Sep 12, 2018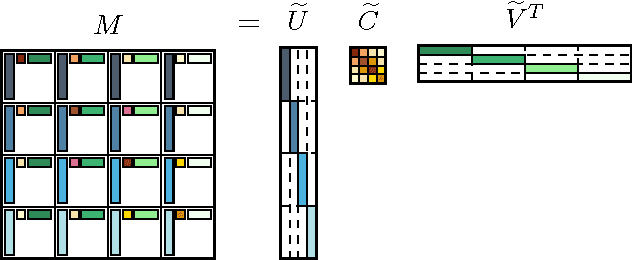

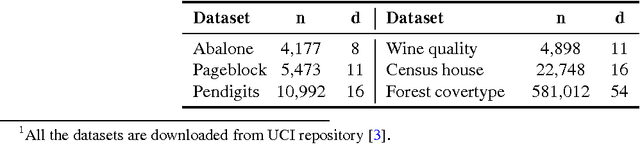
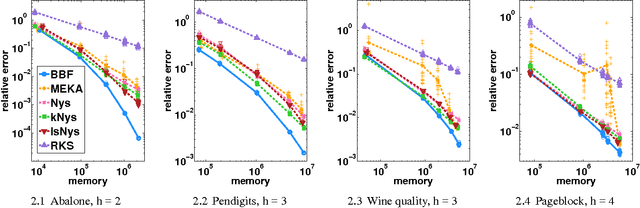
Kernel methods are widespread in machine learning; however, they are limited by the quadratic complexity of the construction, application, and storage of kernel matrices. Low-rank matrix approximation algorithms are widely used to address this problem and reduce the arithmetic and storage cost. However, we observed that for some datasets with wide intra-class variability, the optimal kernel parameter for smaller classes yields a matrix that is less well approximated by low-rank methods. In this paper, we propose an efficient structured low-rank approximation method---the Block Basis Factorization (BBF)---and its fast construction algorithm to approximate radial basis function (RBF) kernel matrices. Our approach has linear memory cost and floating point operations. BBF works for a wide range of kernel bandwidth parameters and extends the domain of applicability of low-rank approximation methods significantly. Our empirical results demonstrate the stability and superiority over the state-of-art kernel approximation algorithms.