 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWindowed Fourier Propagator: A Frequency-Local Neural Operator for Wave Equations in Inhomogeneous Media
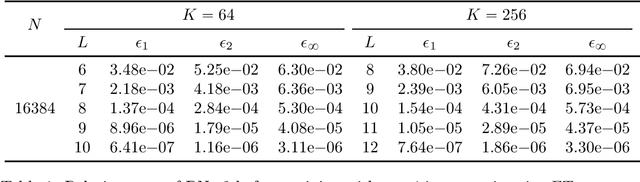
Mar 15, 2026Wave equations are fundamental to describing a vast array of physical phenomena, yet their simulation in inhomogeneous media poses a computational challenge due to the highly oscillatory nature of the solutions. To overcome the high costs of traditional solvers, we propose the Windowed Fourier Propagator (WFP), a novel neural operator that efficiently learns the solution operator. The WFP's design is rooted in the physical principle of frequency locality, where wave energy scatters primarily to adjacent frequencies. By learning a set of compact, localized propagators, each mapping an input frequency to a small window of outputs, our method avoids the complexity of dense interaction models and achieves computational efficiency. Another key feature is the explicit preservation of superposition, which enables remarkable generalization from simple training data (e.g., plane waves) to arbitrary, complex wave states. We demonstrate that the WFP provides an explainable, efficient and accurate framework for data-driven wave modeling in complex media.
ButterflyNet2D: Bridging Classical Methods and Neural Network Methods in Image Processing
Nov 29, 2022



Both classical Fourier transform-based methods and neural network methods are widely used in image processing tasks. The former has better interpretability, whereas the latter often achieves better performance in practice. This paper introduces ButterflyNet2D, a regular CNN with sparse cross-channel connections. A Fourier initialization strategy for ButterflyNet2D is proposed to approximate Fourier transforms. Numerical experiments validate the accuracy of ButterflyNet2D approximating both the Fourier and the inverse Fourier transforms. Moreover, through four image processing tasks and image datasets, we show that training ButterflyNet2D from Fourier initialization does achieve better performance than random initialized neural networks.
SpecNet2: Orthogonalization-free spectral embedding by neural networks
Jun 14, 2022
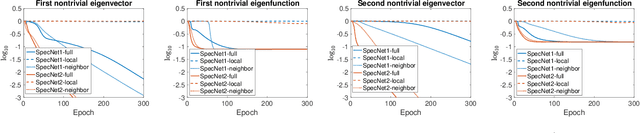

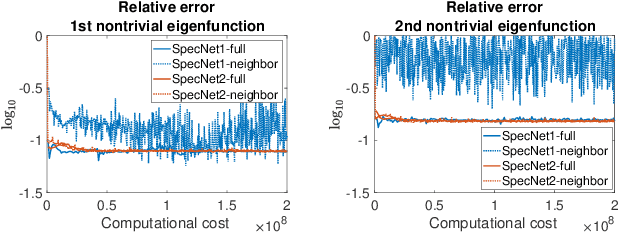
Spectral methods which represent data points by eigenvectors of kernel matrices or graph Laplacian matrices have been a primary tool in unsupervised data analysis. In many application scenarios, parametrizing the spectral embedding by a neural network that can be trained over batches of data samples gives a promising way to achieve automatic out-of-sample extension as well as computational scalability. Such an approach was taken in the original paper of SpectralNet (Shaham et al. 2018), which we call SpecNet1. The current paper introduces a new neural network approach, named SpecNet2, to compute spectral embedding which optimizes an equivalent objective of the eigen-problem and removes the orthogonalization layer in SpecNet1. SpecNet2 also allows separating the sampling of rows and columns of the graph affinity matrix by tracking the neighbors of each data point through the gradient formula. Theoretically, we show that any local minimizer of the new orthogonalization-free objective reveals the leading eigenvectors. Furthermore, global convergence for this new orthogonalization-free objective using a batch-based gradient descent method is proved. Numerical experiments demonstrate the improved performance and computational efficiency of SpecNet2 on simulated data and image datasets.
Butterfly-Net2: Simplified Butterfly-Net and Fourier Transform Initialization
Dec 09, 2019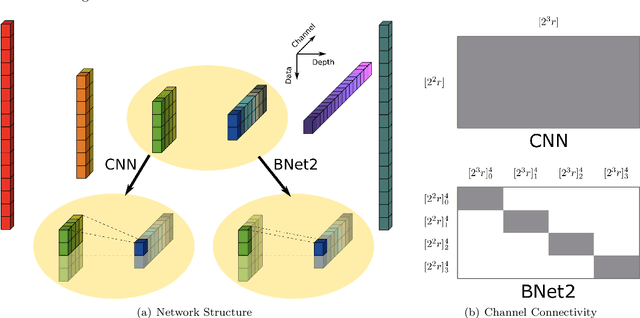

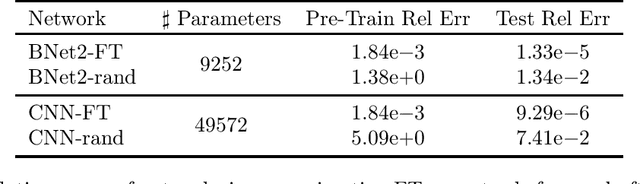
Structured CNN designed using the prior information of problems potentially improves efficiency over conventional CNNs in various tasks in solving PDEs and inverse problems in signal processing. This paper introduces BNet2, a simplified Butterfly-Net and inline with the conventional CNN. Moreover, a Fourier transform initialization is proposed for both BNet2 and CNN with guaranteed approximation power to represent the Fourier transform operator. Experimentally, BNet2 and the Fourier transform initialization strategy are tested on various tasks, including approximating Fourier transform operator, end-to-end solvers of linear and nonlinear PDEs in 1D, and denoising and deblurring of 1D signals. On all tasks, under the same initialization, BNet2 achieves similar accuracy as CNN but has fewer parameters. Fourier transform initialized BNet2 and CNN consistently improve the training and testing accuracy over the randomly initialized CNN.
Mask Embedding in conditional GAN for Guided Synthesis of High Resolution Images
Jul 03, 2019


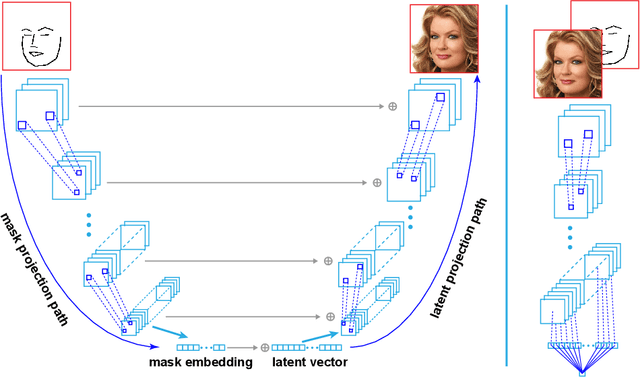
Recent advancements in conditional Generative Adversarial Networks (cGANs) have shown promises in label guided image synthesis. Semantic masks, such as sketches and label maps, are another intuitive and effective form of guidance in image synthesis. Directly incorporating the semantic masks as constraints dramatically reduces the variability and quality of the synthesized results. We observe this is caused by the incompatibility of features from different inputs (such as mask image and latent vector) of the generator. To use semantic masks as guidance whilst providing realistic synthesized results with fine details, we propose to use mask embedding mechanism to allow for a more efficient initial feature projection in the generator. We validate the effectiveness of our approach by training a mask guided face generator using CELEBA-HQ dataset. We can generate realistic and high resolution facial images up to the resolution of 512*512 with a mask guidance. Our code is publicly available.
Variational training of neural network approximations of solution maps for physical models
May 07, 2019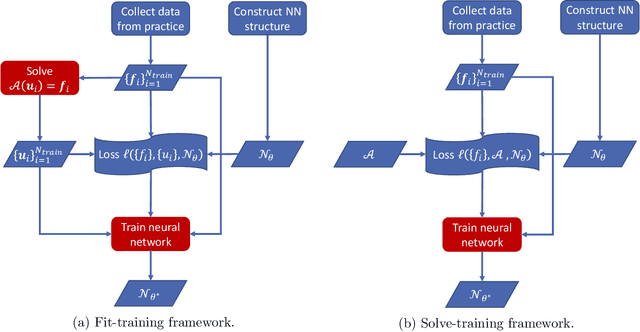


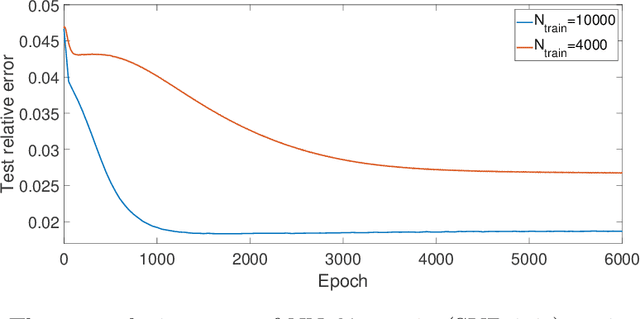
A novel solve-training framework is proposed to train neural network in representing low dimensional solution maps of physical models. Solve-training framework uses the neural network as the ansatz of the solution map and train the network variationally via loss functions from the underlying physical models. Solve-training framework avoids expensive data preparation in the traditional supervised training procedure, which prepares labels for input data, and still achieves effective representation of the solution map adapted to the input data distribution. The efficiency of solve-training framework is demonstrated through obtaining solutions maps for linear and nonlinear elliptic equations, and maps from potentials to ground states of linear and nonlinear Schr\"odinger equations.
A stochastic version of Stein Variational Gradient Descent for efficient sampling
Apr 11, 2019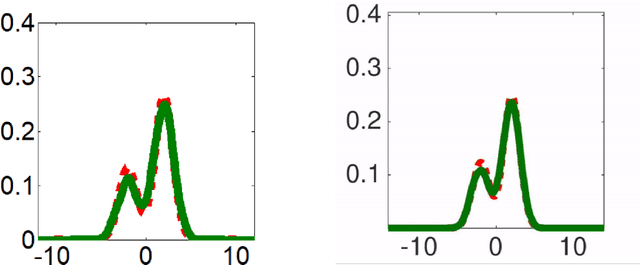

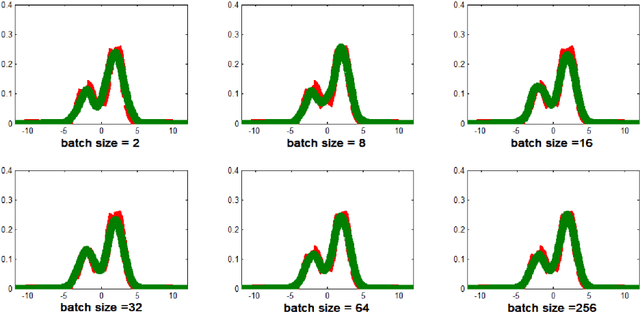

We propose in this work RBM-SVGD, a stochastic version of Stein Variational Gradient Descent (SVGD) method for efficiently sampling from a given probability measure and thus useful for Bayesian inference. The method is to apply the Random Batch Method (RBM) for interacting particle systems proposed by Jin et al to the interacting particle systems in SVGD. While keeping the behaviors of SVGD, it reduces the computational cost, especially when the interacting kernel has long range. Numerical examples verify the efficiency of this new version of SVGD.
Block Basis Factorization for Scalable Kernel Matrix Evaluation
Sep 12, 2018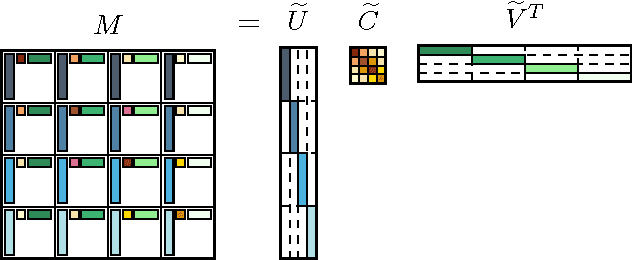

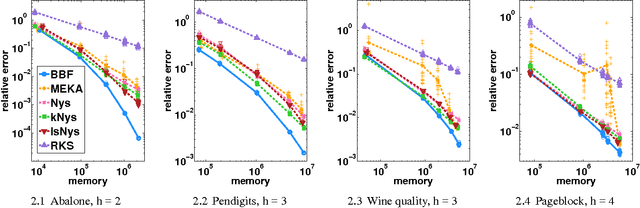
Kernel methods are widespread in machine learning; however, they are limited by the quadratic complexity of the construction, application, and storage of kernel matrices. Low-rank matrix approximation algorithms are widely used to address this problem and reduce the arithmetic and storage cost. However, we observed that for some datasets with wide intra-class variability, the optimal kernel parameter for smaller classes yields a matrix that is less well approximated by low-rank methods. In this paper, we propose an efficient structured low-rank approximation method---the Block Basis Factorization (BBF)---and its fast construction algorithm to approximate radial basis function (RBF) kernel matrices. Our approach has linear memory cost and floating point operations. BBF works for a wide range of kernel bandwidth parameters and extends the domain of applicability of low-rank approximation methods significantly. Our empirical results demonstrate the stability and superiority over the state-of-art kernel approximation algorithms.
Butterfly-Net: Optimal Function Representation Based on Convolutional Neural Networks
May 18, 2018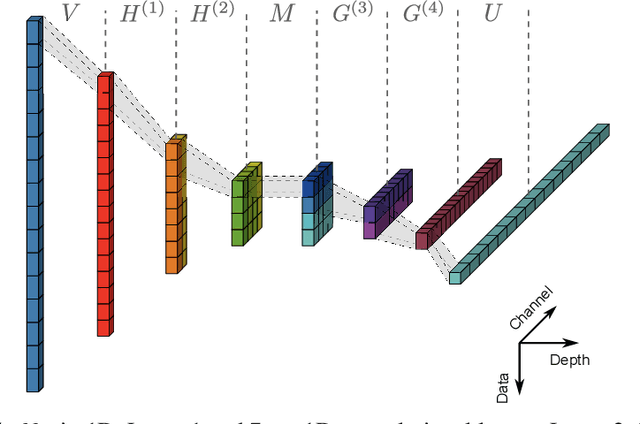

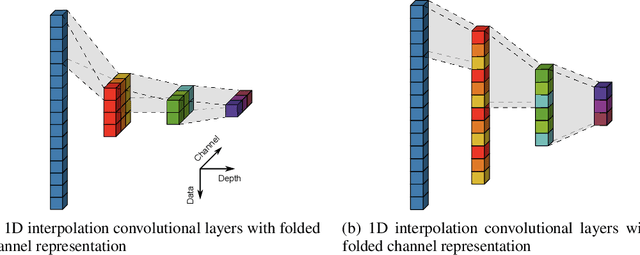

Deep networks, especially Convolutional Neural Networks (CNNs), have been successfully applied in various areas of machine learning as well as to challenging problems in other scientific and engineering fields. This paper introduces Butterfly-Net, a low-complexity CNN with structured hard-coded weights and sparse across-channel connections, which aims at an optimal hierarchical function representation of the input signal. Theoretical analysis of the approximation power of Butterfly-Net to the Fourier representation of input data shows that the error decays exponentially as the depth increases. Due to the ability of Butterfly-Net to approximate Fourier and local Fourier transforms, the result can be used for approximation upper bound for CNNs in a large class of problems. The analysis results are validated in numerical experiments on the approximation of a 1D Fourier kernel and of solving a 2D Poisson's equation.