 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Filtered Knowledge Graphs from Sparse Autoencoder Features
Apr 28, 2026Sparse autoencoders (SAEs) extract millions of interpretable features from a language model, but flat feature inventories aren't very useful on their own. Domain concepts get mixed with generic and weakly grounded features, while related ideas are scattered across many units, and there's no way to understand relationships between features. We address this by first constructing a strict domain-specific concept universe from a large SAE inventory using contrastive activations and a multi-stage filtering process. Next, we build two aligned graph views on the filtered set: a co-occurrence graph for corpus-level conceptual structure, organized at multiple levels of granularity, and a transcoder-based mechanism graph that links source-layer and target-layer features through sparse latent pathways. Automated edge labeling then turns these graph views into readable knowledge graphs rather than unlabeled layouts. In a case study on a biology textbook, these graphs recover coherent chapter and subchapter-level structure, reveal concepts that bridge neighboring topics, and transform messy sentence-level activity containing thousands of features into compact, readable views that illustrate the model's local activity. Taken together, this reframes a flat SAE inventory as an internal knowledge graph that converts feature-level interpretability into a global map of model knowledge and enables audits of reasoning faithfulness.
SpectraQuery: A Hybrid Retrieval-Augmented Conversational Assistant for Battery Science
Jan 14, 2026Scientific reasoning increasingly requires linking structured experimental data with the unstructured literature that explains it, yet most large language model (LLM) assistants cannot reason jointly across these modalities. We introduce SpectraQuery, a hybrid natural-language query framework that integrates a relational Raman spectroscopy database with a vector-indexed scientific literature corpus using a Structured and Unstructured Query Language (SUQL)-inspired design. By combining semantic parsing with retrieval-augmented generation, SpectraQuery translates open-ended questions into coordinated SQL and literature retrieval operations, producing cited answers that unify numerical evidence with mechanistic explanation. Across SQL correctness, answer groundedness, retrieval effectiveness, and expert evaluation, SpectraQuery demonstrates strong performance: approximately 80 percent of generated SQL queries are fully correct, synthesized answers reach 93-97 percent groundedness with 10-15 retrieved passages, and battery scientists rate responses highly across accuracy, relevance, grounding, and clarity (4.1-4.6/5). These results show that hybrid retrieval architectures can meaningfully support scientific workflows by bridging data and discourse for high-volume experimental datasets.
Factor Fitting, Rank Allocation, and Partitioning in Multilevel Low Rank Matrices
Oct 30, 2023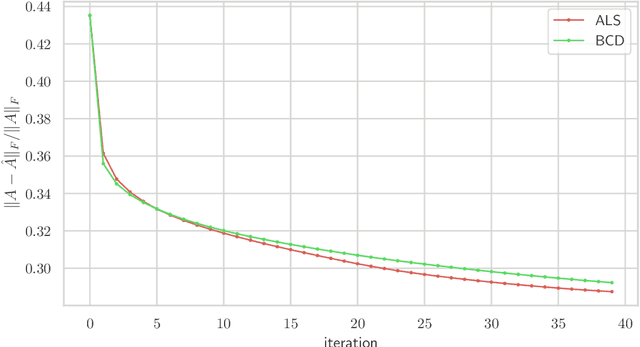
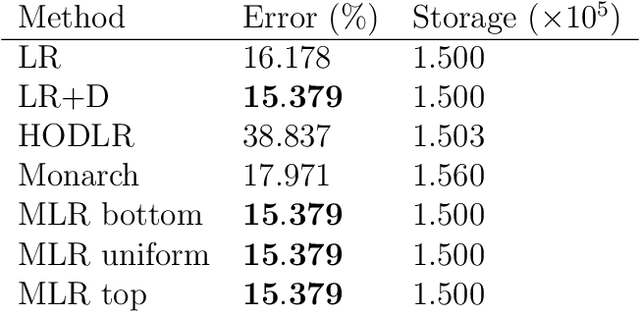
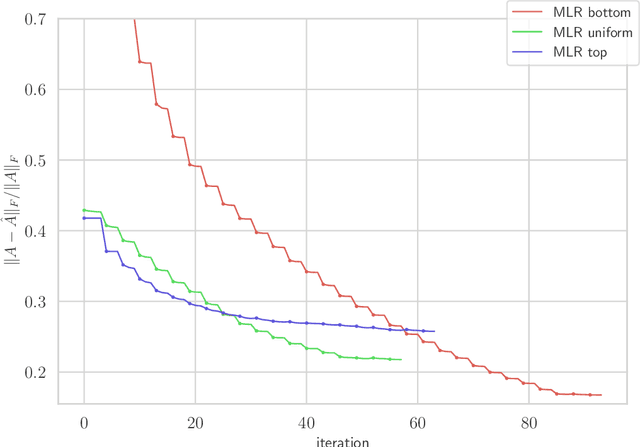
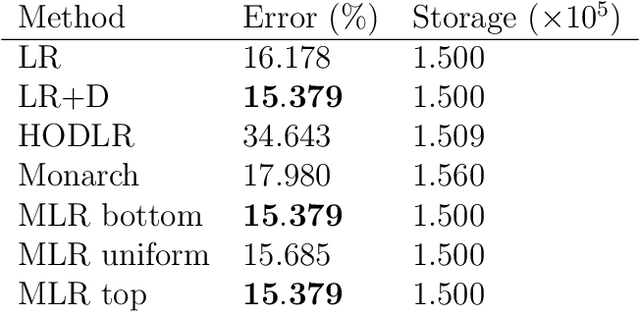
We consider multilevel low rank (MLR) matrices, defined as a row and column permutation of a sum of matrices, each one a block diagonal refinement of the previous one, with all blocks low rank given in factored form. MLR matrices extend low rank matrices but share many of their properties, such as the total storage required and complexity of matrix-vector multiplication. We address three problems that arise in fitting a given matrix by an MLR matrix in the Frobenius norm. The first problem is factor fitting, where we adjust the factors of the MLR matrix. The second is rank allocation, where we choose the ranks of the blocks in each level, subject to the total rank having a given value, which preserves the total storage needed for the MLR matrix. The final problem is to choose the hierarchical partition of rows and columns, along with the ranks and factors. This paper is accompanied by an open source package that implements the proposed methods.
Resilient VAE: Unsupervised Anomaly Detection at the SLAC Linac Coherent Light Source
Sep 05, 2023



Significant advances in utilizing deep learning for anomaly detection have been made in recent years. However, these methods largely assume the existence of a normal training set (i.e., uncontaminated by anomalies) or even a completely labeled training set. In many complex engineering systems, such as particle accelerators, labels are sparse and expensive; in order to perform anomaly detection in these cases, we must drop these assumptions and utilize a completely unsupervised method. This paper introduces the Resilient Variational Autoencoder (ResVAE), a deep generative model specifically designed for anomaly detection. ResVAE exhibits resilience to anomalies present in the training data and provides feature-level anomaly attribution. During the training process, ResVAE learns the anomaly probability for each sample as well as each individual feature, utilizing these probabilities to effectively disregard anomalous examples in the training data. We apply our proposed method to detect anomalies in the accelerator status at the SLAC Linac Coherent Light Source (LCLS). By utilizing shot-to-shot data from the beam position monitoring system, we demonstrate the exceptional capability of ResVAE in identifying various types of anomalies that are visible in the accelerator.
Learning Reduced-Order Models for Cardiovascular Simulations with Graph Neural Networks
Mar 13, 2023



Reduced-order models based on physics are a popular choice in cardiovascular modeling due to their efficiency, but they may experience reduced accuracy when working with anatomies that contain numerous junctions or pathological conditions. We develop one-dimensional reduced-order models that simulate blood flow dynamics using a graph neural network trained on three-dimensional hemodynamic simulation data. Given the initial condition of the system, the network iteratively predicts the pressure and flow rate at the vessel centerline nodes. Our numerical results demonstrate the accuracy and generalizability of our method in physiological geometries comprising a variety of anatomies and boundary conditions. Our findings demonstrate that our approach can achieve errors below 2% and 3% for pressure and flow rate, respectively, provided there is adequate training data. As a result, our method exhibits superior performance compared to physics-based one-dimensional models, while maintaining high efficiency at inference time.
Physics-based parameterized neural ordinary differential equations: prediction of laser ignition in a rocket combustor
Feb 16, 2023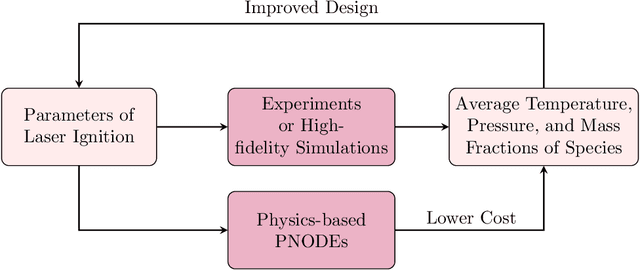



In this work, we present a novel physics-based data-driven framework for reduced-order modeling of laser ignition in a model rocket combustor based on parameterized neural ordinary differential equations (PNODE). Deep neural networks are embedded as functions of high-dimensional parameters of laser ignition to predict various terms in a 0D flow model including the heat source function, pre-exponential factors, and activation energy. Using the governing equations of a 0D flow model, our PNODE needs only a limited number of training samples and predicts trajectories of various quantities such as temperature, pressure, and mass fractions of species while satisfying physical constraints. We validate our physics-based PNODE on solution snapshots of high-fidelity Computational Fluid Dynamics (CFD) simulations of laser-induced ignition in a prototype rocket combustor. We compare the performance of our physics-based PNODE with that of kernel ridge regression and fully connected neural networks. Our results show that our physics-based PNODE provides solutions with lower mean absolute errors of average temperature over time, thus improving the prediction of successful laser ignition with high-dimensional parameters.
Coincident Learning for Unsupervised Anomaly Detection
Jan 26, 2023



Anomaly detection is an important task for complex systems (e.g., industrial facilities, manufacturing, large-scale science experiments), where failures in a sub-system can lead to low yield, faulty products, or even damage to components. While complex systems often have a wealth of data, labeled anomalies are typically rare (or even nonexistent) and expensive to acquire. In this paper, we introduce a new method, called CoAD, for training anomaly detection models on unlabeled data, based on the expectation that anomalous behavior in one sub-system will produce coincident anomalies in downstream sub-systems and products. Given data split into two streams $s$ and $q$ (i.e., subsystem diagnostics and final product quality), we define an unsupervised metric, $\hat{F}_\beta$, out of analogy to the supervised classification $F_\beta$ statistic, which quantifies the performance of the independent anomaly detection algorithms on s and q based on their coincidence rate. We demonstrate our method in four cases: a synthetic time-series data set, a synthetic imaging data set generated from MNIST, a metal milling data set, and a data set taken from a particle accelerator.
Probabilistic partition of unity networks for high-dimensional regression problems
Oct 06, 2022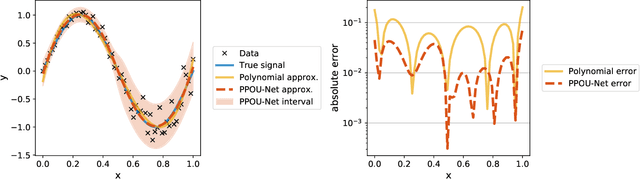
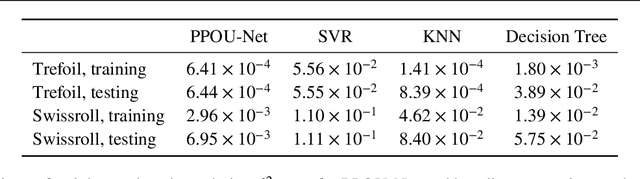
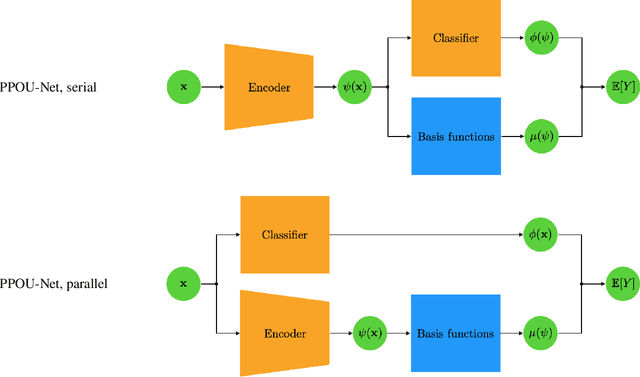
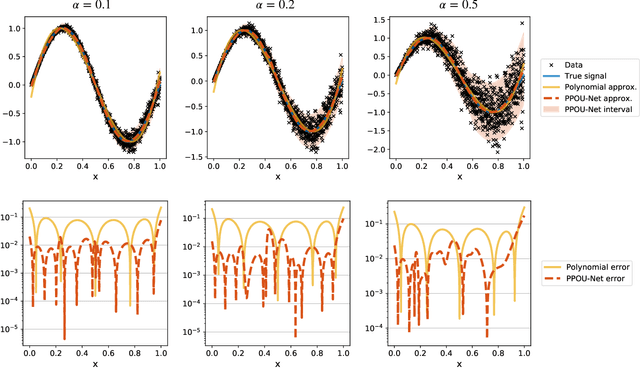
We explore the probabilistic partition of unity network (PPOU-Net) model in the context of high-dimensional regression problems. With the PPOU-Nets, the target function for any given input is approximated by a mixture of experts model, where each cluster is associated with a fixed-degree polynomial. The weights of the clusters are determined by a DNN that defines a partition of unity. The weighted average of the polynomials approximates the target function and produces uncertainty quantification naturally. Our training strategy leverages automatic differentiation and the expectation maximization (EM) algorithm. During the training, we (i) apply gradient descent to update the DNN coefficients; (ii) update the polynomial coefficients using weighted least-squares solves; and (iii) compute the variance of each cluster according to a closed-form formula derived from the EM algorithm. The PPOU-Nets consistently outperform the baseline fully-connected neural networks of comparable sizes in numerical experiments of various data dimensions. We also explore the proposed model in applications of quantum computing, where the PPOU-Nets act as surrogate models for cost landscapes associated with variational quantum circuits.
A Simple and Effective Method To Eliminate the Self Language Bias in Multilingual Representations
Sep 10, 2021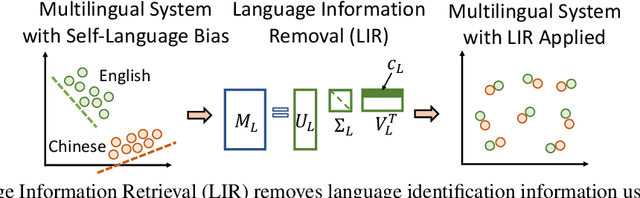
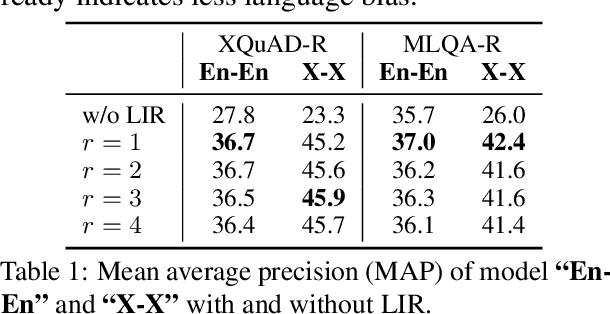
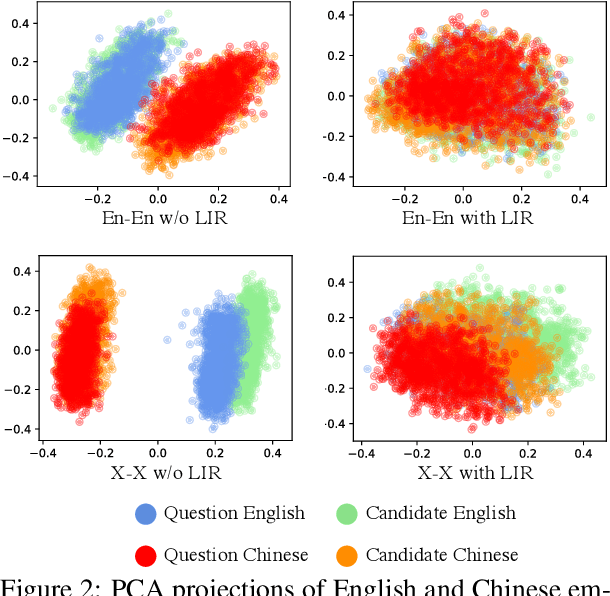

Language agnostic and semantic-language information isolation is an emerging research direction for multilingual representations models. We explore this problem from a novel angle of geometric algebra and semantic space. A simple but highly effective method "Language Information Removal (LIR)" factors out language identity information from semantic related components in multilingual representations pre-trained on multi-monolingual data. A post-training and model-agnostic method, LIR only uses simple linear operations, e.g. matrix factorization and orthogonal projection. LIR reveals that for weak-alignment multilingual systems, the principal components of semantic spaces primarily encodes language identity information. We first evaluate the LIR on a cross-lingual question answer retrieval task (LAReQA), which requires the strong alignment for the multilingual embedding space. Experiment shows that LIR is highly effectively on this task, yielding almost 100% relative improvement in MAP for weak-alignment models. We then evaluate the LIR on Amazon Reviews and XEVAL dataset, with the observation that removing language information is able to improve the cross-lingual transfer performance.
Universal Sentence Representation Learning with Conditional Masked Language Model
Dec 29, 2020


This paper presents a novel training method, Conditional Masked Language Modeling (CMLM), to effectively learn sentence representations on large scale unlabeled corpora. CMLM integrates sentence representation learning into MLM training by conditioning on the encoded vectors of adjacent sentences. Our English CMLM model achieves state-of-the-art performance on SentEval, even outperforming models learned using (semi-)supervised signals. As a fully unsupervised learning method, CMLM can be conveniently extended to a broad range of languages and domains. We find that a multilingual CMLM model co-trained with bitext retrieval~(BR) and natural language inference~(NLI) tasks outperforms the previous state-of-the-art multilingual models by a large margin. We explore the same language bias of the learned representations, and propose a principle component based approach to remove the language identifying information from the representation while still retaining sentence semantics.