 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning manifold diffusion semigroups from graph transition matrices
May 25, 2026We consider graph diffusion processes constructed from finite i.i.d. samples drawn from an unknown manifold embedded in ambient Euclidean space, where the graph affinity is defined by an ambient Gaussian kernel matrix. We show that the manifold heat semigroup $Q_t = e^{tΔ}$ can be approximated directly by iterating the graph transition matrix $P$, under only low regularity assumptions on the test function $f$, including the case $f \in L^\infty$. We bound $\| P^n f - Q_t f \|$ in $\infty$-norm, with the operator application to $f$ properly defined, and we recover the classical graph-Laplacian pointwise rate $O(N^{-2/(d+6)})$ up to logarithmic factors, for diffusion times $t $ up to $O(1)$ and longer. The rate holds for in-sample error as well as out-of-sample generalization, where the estimator of $Q_t f$ at a new point is defined via kernel convolution. To handle non-uniform sampling densities on the manifold, we introduce a right-normalization of the graph transition matrix; under the assumption that the sampling density $p$ is $C^3$ and bounded away from zero, the same convergence rates hold. We numerically demonstrate the performance of the proposed estimator on simulated data.
Generative models for decision-making under distributional shift
Apr 06, 2026Many data-driven decision problems are formulated using a nominal distribution estimated from historical data, while performance is ultimately determined by a deployment distribution that may be shifted, context-dependent, partially observed, or stress-induced. This tutorial presents modern generative models, particularly flow- and score-based methods, as mathematical tools for constructing decision-relevant distributions. From an operations research perspective, their primary value lies not in unconstrained sample synthesis but in representing and transforming distributions through transport maps, velocity fields, score fields, and guided stochastic dynamics. We present a unified framework based on pushforward maps, continuity, Fokker-Planck equations, Wasserstein geometry, and optimization in probability space. Within this framework, generative models can be used to learn nominal uncertainty, construct stressed or least-favorable distributions for robustness, and produce conditional or posterior distributions under side information and partial observation. We also highlight representative theoretical guarantees, including forward-reverse convergence for iterative flow models, first-order minimax analysis in transport-map space, and error-transfer bounds for posterior sampling with generative priors. The tutorial provides a principled introduction to using generative models for scenario generation, robust decision-making, uncertainty quantification, and related problems under distributional shift.
Worst-case generation via minimax optimization in Wasserstein space
Dec 09, 2025Worst-case generation plays a critical role in evaluating robustness and stress-testing systems under distribution shifts, in applications ranging from machine learning models to power grids and medical prediction systems. We develop a generative modeling framework for worst-case generation for a pre-specified risk, based on min-max optimization over continuous probability distributions, namely the Wasserstein space. Unlike traditional discrete distributionally robust optimization approaches, which often suffer from scalability issues, limited generalization, and costly worst-case inference, our framework exploits the Brenier theorem to characterize the least favorable (worst-case) distribution as the pushforward of a transport map from a continuous reference measure, enabling a continuous and expressive notion of risk-induced generation beyond classical discrete DRO formulations. Based on the min-max formulation, we propose a Gradient Descent Ascent (GDA)-type scheme that updates the decision model and the transport map in a single loop, establishing global convergence guarantees under mild regularity assumptions and possibly without convexity-concavity. We also propose to parameterize the transport map using a neural network that can be trained simultaneously with the GDA iterations by matching the transported training samples, thereby achieving a simulation-free approach. The efficiency of the proposed method as a risk-induced worst-case generator is validated by numerical experiments on synthetic and image data.
Deep spatio-temporal point processes: Advances and new directions
Apr 08, 2025



Spatio-temporal point processes (STPPs) model discrete events distributed in time and space, with important applications in areas such as criminology, seismology, epidemiology, and social networks. Traditional models often rely on parametric kernels, limiting their ability to capture heterogeneous, nonstationary dynamics. Recent innovations integrate deep neural architectures -- either by modeling the conditional intensity function directly or by learning flexible, data-driven influence kernels, substantially broadening their expressive power. This article reviews the development of the deep influence kernel approach, which enjoys statistical explainability, since the influence kernel remains in the model to capture the spatiotemporal propagation of event influence and its impact on future events, while also possessing strong expressive power, thereby benefiting from both worlds. We explain the main components in developing deep kernel point processes, leveraging tools such as functional basis decomposition and graph neural networks to encode complex spatial or network structures, as well as estimation using both likelihood-based and likelihood-free methods, and address computational scalability for large-scale data. We also discuss the theoretical foundation of kernel identifiability. Simulated and real-data examples highlight applications to crime analysis, earthquake aftershock prediction, and sepsis prediction modeling, and we conclude by discussing promising directions for the field.
Flow-based generative models as iterative algorithms in probability space
Feb 19, 2025



Generative AI (GenAI) has revolutionized data-driven modeling by enabling the synthesis of high-dimensional data across various applications, including image generation, language modeling, biomedical signal processing, and anomaly detection. Flow-based generative models provide a powerful framework for capturing complex probability distributions, offering exact likelihood estimation, efficient sampling, and deterministic transformations between distributions. These models leverage invertible mappings governed by Ordinary Differential Equations (ODEs), enabling precise density estimation and likelihood evaluation. This tutorial presents an intuitive mathematical framework for flow-based generative models, formulating them as neural network-based representations of continuous probability densities. We explore key theoretical principles, including the Wasserstein metric, gradient flows, and density evolution governed by ODEs, to establish convergence guarantees and bridge empirical advancements with theoretical insights. By providing a rigorous yet accessible treatment, we aim to equip researchers and practitioners with the necessary tools to effectively apply flow-based generative models in signal processing and machine learning.
Point processes with event time uncertainty
Nov 05, 2024



Point processes are widely used statistical models for uncovering the temporal patterns in dependent event data. In many applications, the event time cannot be observed exactly, calling for the incorporation of time uncertainty into the modeling of point process data. In this work, we introduce a framework to model time-uncertain point processes possibly on a network. We start by deriving the formulation in the continuous-time setting under a few assumptions motivated by application scenarios. After imposing a time grid, we obtain a discrete-time model that facilitates inference and can be computed by first-order optimization methods such as Gradient Descent or Variation inequality (VI) using batch-based Stochastic Gradient Descent (SGD). The parameter recovery guarantee is proved for VI inference at an $O(1/k)$ convergence rate using $k$ SGD steps. Our framework handles non-stationary processes by modeling the inference kernel as a matrix (or tensor on a network) and it covers the stationary process, such as the classical Hawkes process, as a special case. We experimentally show that the proposed approach outperforms previous General Linear model (GLM) baselines on simulated and real data and reveals meaningful causal relations on a Sepsis-associated Derangements dataset.
Improved convergence rate of kNN graph Laplacians
Oct 30, 2024



In graph-based data analysis, $k$-nearest neighbor ($k$NN) graphs are widely used due to their adaptivity to local data densities. Allowing weighted edges in the graph, the kernelized graph affinity provides a more general type of $k$NN graph where the $k$NN distance is used to set the kernel bandwidth adaptively. In this work, we consider a general class of $k$NN graph where the graph affinity is $W_{ij} = \epsilon^{-d/2} \; k_0 ( \| x_i - x_j \|^2 / \epsilon \phi( \widehat{\rho}(x_i), \widehat{\rho}(x_j) )^2 ) $, with $\widehat{\rho}(x)$ being the (rescaled) $k$NN distance at the point $x$, $\phi$ a symmetric bi-variate function, and $k_0$ a non-negative function on $[0,\infty)$. Under the manifold data setting, where $N$ i.i.d. samples $x_i$ are drawn from a density $p$ on a $d$-dimensional unknown manifold embedded in a high dimensional Euclidean space, we prove the point-wise convergence of the $k$NN graph Laplacian to the limiting manifold operator (depending on $p$) at the rate of $O(N^{-2/(d+6)}\,)$, up to a log factor, when $k_0$ and $\phi$ have $C^3$ regularity and satisfy other technical conditions. This fast rate is obtained when $\epsilon \sim N^{-2/(d+6)}\,$ and $k \sim N^{6/(d+6)}\,$, both at the optimal order to balance the theoretical bias and variance errors. When $k_0$ and $\phi$ have lower regularities, including when $k_0$ is a compactly supported function as in the standard $k$NN graph, the convergence rate degenerates to $O(N^{-1/(d+4)}\,)$. Our improved convergence rate is based on a refined analysis of the $k$NN estimator, which can be of independent interest. We validate our theory by numerical experiments on simulated data.
Local Flow Matching Generative Models
Oct 03, 2024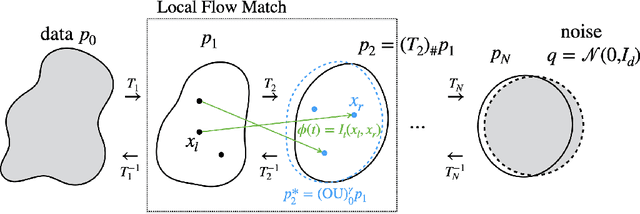

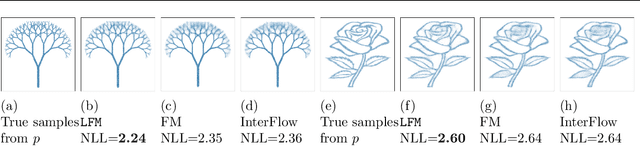

Flow Matching (FM) is a simulation-free method for learning a continuous and invertible flow to interpolate between two distributions, and in particular to generate data from noise in generative modeling. In this paper, we introduce Local Flow Matching (LFM), which learns a sequence of FM sub-models and each matches a diffusion process up to the time of the step size in the data-to-noise direction. In each step, the two distributions to be interpolated by the sub-model are closer to each other than data vs. noise, and this enables the use of smaller models with faster training. The stepwise structure of LFM is natural to be distilled and different distillation techniques can be adopted to speed up generation. Theoretically, we prove a generation guarantee of the proposed flow model in terms of the $\chi^2$-divergence between the generated and true data distributions. In experiments, we demonstrate the improved training efficiency and competitive generative performance of LFM compared to FM on the unconditional generation of tabular data and image datasets, and also on the conditional generation of robotic manipulation policies.
Posterior sampling via Langevin dynamics based on generative priors
Oct 02, 2024



Posterior sampling in high-dimensional spaces using generative models holds significant promise for various applications, including but not limited to inverse problems and guided generation tasks. Despite many recent developments, generating diverse posterior samples remains a challenge, as existing methods require restarting the entire generative process for each new sample, making the procedure computationally expensive. In this work, we propose efficient posterior sampling by simulating Langevin dynamics in the noise space of a pre-trained generative model. By exploiting the mapping between the noise and data spaces which can be provided by distilled flows or consistency models, our method enables seamless exploration of the posterior without the need to re-run the full sampling chain, drastically reducing computational overhead. Theoretically, we prove a guarantee for the proposed noise-space Langevin dynamics to approximate the posterior, assuming that the generative model sufficiently approximates the prior distribution. Our framework is experimentally validated on image restoration tasks involving noisy linear and nonlinear forward operators applied to LSUN-Bedroom (256 x 256) and ImageNet (64 x 64) datasets. The results demonstrate that our approach generates high-fidelity samples with enhanced semantic diversity even under a limited number of function evaluations, offering superior efficiency and performance compared to existing diffusion-based posterior sampling techniques.
Training Guarantees of Neural Network Classification Two-Sample Tests by Kernel Analysis
Jul 09, 2024



We construct and analyze a neural network two-sample test to determine whether two datasets came from the same distribution (null hypothesis) or not (alternative hypothesis). We perform time-analysis on a neural tangent kernel (NTK) two-sample test. In particular, we derive the theoretical minimum training time needed to ensure the NTK two-sample test detects a deviation-level between the datasets. Similarly, we derive the theoretical maximum training time before the NTK two-sample test detects a deviation-level. By approximating the neural network dynamics with the NTK dynamics, we extend this time-analysis to the realistic neural network two-sample test generated from time-varying training dynamics and finite training samples. A similar extension is done for the neural network two-sample test generated from time-varying training dynamics but trained on the population. To give statistical guarantees, we show that the statistical power associated with the neural network two-sample test goes to 1 as the neural network training samples and test evaluation samples go to infinity. Additionally, we prove that the training times needed to detect the same deviation-level in the null and alternative hypothesis scenarios are well-separated. Finally, we run some experiments showcasing a two-layer neural network two-sample test on a hard two-sample test problem and plot a heatmap of the statistical power of the two-sample test in relation to training time and network complexity.