 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultivariate Time Series Data Imputation via Distributionally Robust Regularization
Jan 31, 2026Multivariate time series (MTS) imputation is often compromised by mismatch between observed and true data distributions -- a bias exacerbated by non-stationarity and systematic missingness. Standard methods that minimize reconstruction error or encourage distributional alignment risk overfitting these biased observations. We propose the Distributionally Robust Regularized Imputer Objective (DRIO), which jointly minimizes reconstruction error and the divergence between the imputer and a worst-case distribution within a Wasserstein ambiguity set. We derive a tractable dual formulation that reduces infinite-dimensional optimization over measures to adversarial search over sample trajectories, and propose an adversarial learning algorithm compatible with flexible deep learning backbones. Comprehensive experiments on diverse real-world datasets show DRIO consistently improves imputation under both missing-completely-at-random and missing-not-at-random settings, reaching Pareto-optimal trade-offs between reconstruction accuracy and distributional alignment.
Movable Antenna Empowered Covert Dual-Functional Radar-Communication
Jan 21, 2026Movable antenna (MA) has emerged as a promising technology to flexibly reconfigure wireless channels by adjusting antenna placement. In this paper, we study a secured dual-functional radar-communication (DFRC) system aided by movable antennas. To enhance the communication security, we aim to maximize the achievable sum rate by jointly optimizing the transmitter beamforming vectors, receiving filter, and antenna placement, subject to radar signal-to-noise ratio (SINR) and transmission covertness constraints. We consider multiple Willies operating in both non-colluding and colluding modes. For noncolluding Willies, we first employ a Lagrangian dual transformation procedure to reformulate the challenging optimization problem into a more tractable form. Subsequently, we develop an efficient block coordinate descent (BCD) algorithm that integrates semidefinite relaxation (SDR), projected gradient descent (PGD), Dinkelbach transformation, and successive convex approximation (SCA) techniques to tackle the resulting problem. For colluding Willies, we first derive the minimum detection error probability (DEP) by characterizing the optimal detection statistic, which is proven to follow the generalized Erlang distribution. Then, we develop a minimum mean square error (MMSE)-based algorithm to address the colluding detection problem. We further provide a comprehensive complexity analysis on the unified design framework. Simulation results demonstrate that the proposed method can significantly improve the covert sum rate, and achieve a superior balance between communication and radar performance compared with existing benchmark schemes.
How Different from the Past? Spatio-Temporal Time Series Forecasting with Self-Supervised Deviation Learning
Oct 06, 2025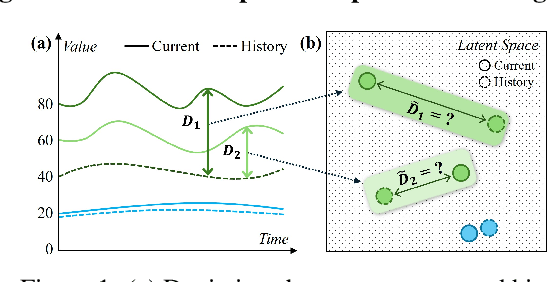
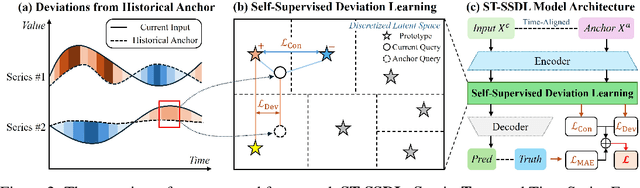
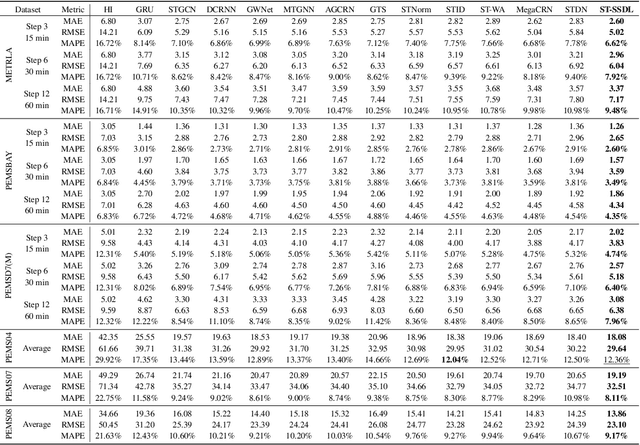
Spatio-temporal forecasting is essential for real-world applications such as traffic management and urban computing. Although recent methods have shown improved accuracy, they often fail to account for dynamic deviations between current inputs and historical patterns. These deviations contain critical signals that can significantly affect model performance. To fill this gap, we propose ST-SSDL, a Spatio-Temporal time series forecasting framework that incorporates a Self-Supervised Deviation Learning scheme to capture and utilize such deviations. ST-SSDL anchors each input to its historical average and discretizes the latent space using learnable prototypes that represent typical spatio-temporal patterns. Two auxiliary objectives are proposed to refine this structure: a contrastive loss that enhances inter-prototype discriminability and a deviation loss that regularizes the distance consistency between input representations and corresponding prototypes to quantify deviation. Optimized jointly with the forecasting objective, these components guide the model to organize its hidden space and improve generalization across diverse input conditions. Experiments on six benchmark datasets show that ST-SSDL consistently outperforms state-of-the-art baselines across multiple metrics. Visualizations further demonstrate its ability to adaptively respond to varying levels of deviation in complex spatio-temporal scenarios. Our code and datasets are available at https://github.com/Jimmy-7664/ST-SSDL.
Crosstalk-Resilient Beamforming for Movable Antenna Enabled Integrated Sensing and Communication
Sep 03, 2025



This paper investigates a movable antenna (MA) enabled integrated sensing and communication (ISAC) system under the influence of antenna crosstalk. First, it generalizes the antenna crosstalk model from the conventional fixed-position antenna (FPA) system to the MA scenario. Then, a Cramer-Rao bound (CRB) minimization problem driven by joint beamforming and antenna position design is presented. Specifically, to address this highly non-convex flexible beamforming problem, we deploy a deep reinforcement learning (DRL) approach to train a flexible beamforming agent. To ensure stability during training, a Twin Delayed Deep Deterministic Policy Gradient (TD3) algorithm is adopted to balance exploration with reward maximization for efficient and reliable learning. Numerical results demonstrate that the proposed crosstalk-resilient (CR) algorithm enhances the overall ISAC performance compared to other benchmark schemes.
Robust Transceiver Design for RIS Enhanced Dual-Functional Radar-Communication with Movable Antenna
Jun 09, 2025Movable antennas (MAs) have demonstrated significant potential in enhancing the performance of dual-functional radar-communication (DFRC) systems. In this paper, we explore an MA-aided DFRC system that utilizes a reconfigurable intelligent surface (RIS) to enhance signal coverage for communications in dead zones. To enhance the radar sensing performance in practical DFRC environments, we propose a unified robust transceiver design framework aimed at maximizing the minimum radar signal-to-interference-plus-noise ratio (SINR) in a cluttered environment. Our approach jointly optimizes transmit beamforming, receive filtering, antenna placement, and RIS reflecting coefficients under imperfect channel state information (CSI) for both sensing and communication channels. To deal with the channel uncertainty-constrained issue, we leverage the convex hull method to transform the primal problem into a more tractable form. We then introduce a two-layer block coordinate descent (BCD) algorithm, incorporating fractional programming (FP), successive convex approximation (SCA), S-Lemma, and penalty techniques to reformulate it into a series of semidefinite program (SDP) subproblems that can be efficiently solved. We provide a comprehensive analysis of the convergence and computational complexity for the proposed design framework. Simulation results demonstrate the robustness of the proposed method, and show that the MA-based design framework can significantly enhance the radar SINR performance while achieving an effective balance between the radar and communication performance.
Deep spatio-temporal point processes: Advances and new directions
Apr 08, 2025



Spatio-temporal point processes (STPPs) model discrete events distributed in time and space, with important applications in areas such as criminology, seismology, epidemiology, and social networks. Traditional models often rely on parametric kernels, limiting their ability to capture heterogeneous, nonstationary dynamics. Recent innovations integrate deep neural architectures -- either by modeling the conditional intensity function directly or by learning flexible, data-driven influence kernels, substantially broadening their expressive power. This article reviews the development of the deep influence kernel approach, which enjoys statistical explainability, since the influence kernel remains in the model to capture the spatiotemporal propagation of event influence and its impact on future events, while also possessing strong expressive power, thereby benefiting from both worlds. We explain the main components in developing deep kernel point processes, leveraging tools such as functional basis decomposition and graph neural networks to encode complex spatial or network structures, as well as estimation using both likelihood-based and likelihood-free methods, and address computational scalability for large-scale data. We also discuss the theoretical foundation of kernel identifiability. Simulated and real-data examples highlight applications to crime analysis, earthquake aftershock prediction, and sepsis prediction modeling, and we conclude by discussing promising directions for the field.
Joint Transceiver Design for RIS Enhanced Dual-Functional Radar-Communication with Movable Antenna
Feb 13, 2025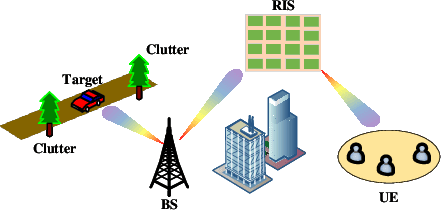
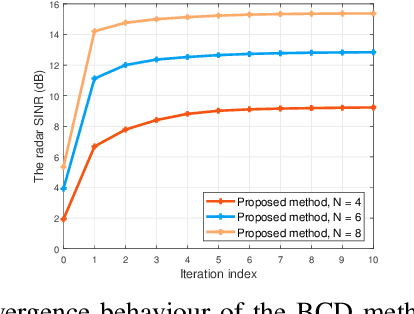
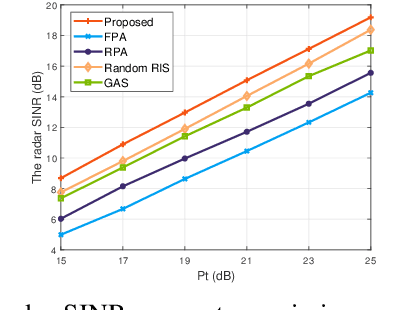
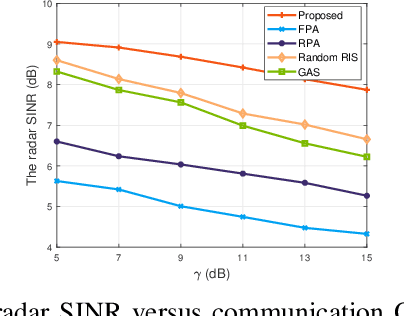
Movable antennas (MAs) have shown significant potential in enhancing the performance of dual-functional radar-communication (DFRC) systems. In this paper, we investigate the MA-based transceiver design for DFRC systems, where a reconfigurable intelligent surface (RIS) is employed to enhance the communication quality in dead zones. To enhance the radar sensing performance, we formulate an optimization problem to maximize the radar signal-to-interference-plus-noise ratio (SINR) by jointly optimizing the beamforming vectors, receiving filter, antenna positions, and RIS reflecting coefficients. To tackle this challenging problem, we develop a fractional programming-based optimization framework, incorporating block coordinate descent (BCD), successive convex approximation (SCA), and penalty techniques. Simulation results demonstrate that the proposed method can significantly improve the radar SINR and achieve a satisfactory balance between the radar and communication performance compared with existing benchmark schemes.
Early Prediction of Natural Gas Pipeline Leaks Using the MKTCN Model
Nov 09, 2024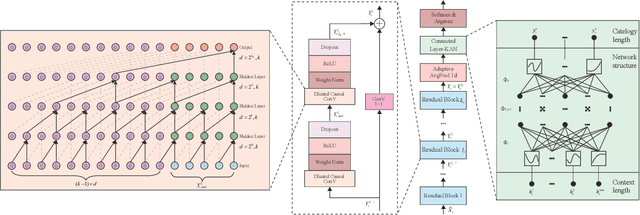
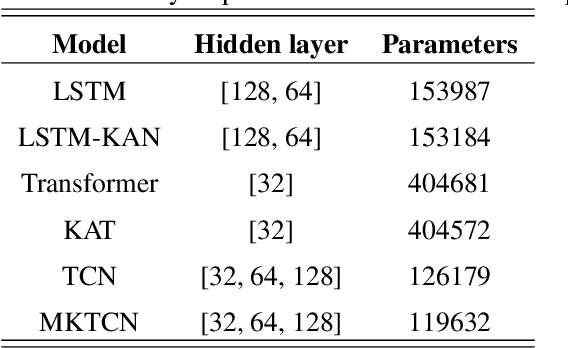
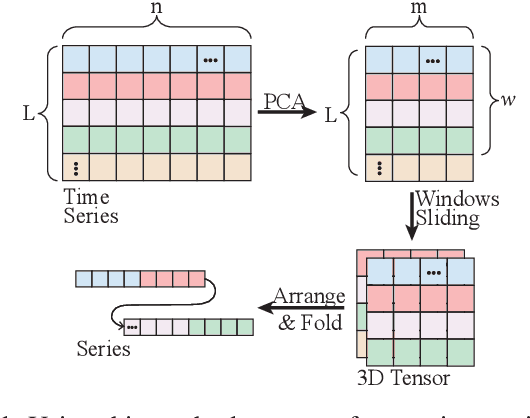
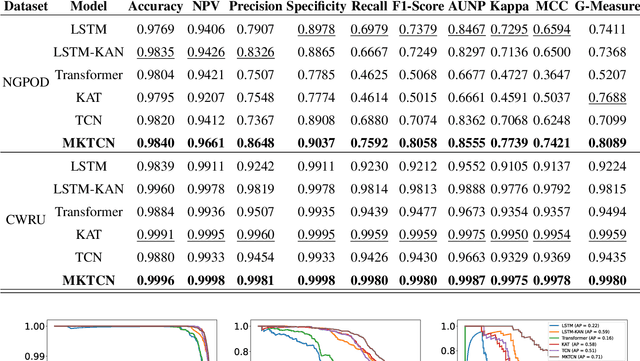
Natural gas pipeline leaks pose severe risks, leading to substantial economic losses and potential hazards to human safety. In this study, we develop an accurate model for the early prediction of pipeline leaks. To the best of our knowledge, unlike previous anomaly detection, this is the first application to use internal pipeline data for early prediction of leaks. The modeling process addresses two main challenges: long-term dependencies and sample imbalance. First, we introduce a dilated convolution-based prediction model to capture long-term dependencies, as dilated convolution expands the model's receptive field without added computational cost. Second, to mitigate sample imbalance, we propose the MKTCN model, which incorporates the Kolmogorov-Arnold Network as the fully connected layer in a dilated convolution model, enhancing network generalization. Finally, we validate the MKTCN model through extensive experiments on two real-world datasets. Results demonstrate that MKTCN outperforms in generalization and classification, particularly under severe data imbalance, and effectively predicts leaks up to 5000 seconds in advance. Overall, the MKTCN model represents a significant advancement in early pipeline leak prediction, providing robust generalization and improved modeling of the long-term dependencies inherent in multi-dimensional time-series data.
STGformer: Efficient Spatiotemporal Graph Transformer for Traffic Forecasting
Oct 01, 2024



Traffic forecasting is a cornerstone of smart city management, enabling efficient resource allocation and transportation planning. Deep learning, with its ability to capture complex nonlinear patterns in spatiotemporal (ST) data, has emerged as a powerful tool for traffic forecasting. While graph neural networks (GCNs) and transformer-based models have shown promise, their computational demands often hinder their application to real-world road networks, particularly those with large-scale spatiotemporal interactions. To address these challenges, we propose a novel spatiotemporal graph transformer (STGformer) architecture. STGformer effectively balances the strengths of GCNs and Transformers, enabling efficient modeling of both global and local traffic patterns while maintaining a manageable computational footprint. Unlike traditional approaches that require multiple attention layers, STG attention block captures high-order spatiotemporal interactions in a single layer, significantly reducing computational cost. In particular, STGformer achieves a 100x speedup and a 99.8\% reduction in GPU memory usage compared to STAEformer during batch inference on a California road graph with 8,600 sensors. We evaluate STGformer on the LargeST benchmark and demonstrate its superiority over state-of-the-art Transformer-based methods such as PDFormer and STAEformer, which underline STGformer's potential to revolutionize traffic forecasting by overcoming the computational and memory limitations of existing approaches, making it a promising foundation for future spatiotemporal modeling tasks.
Robust Traffic Forecasting against Spatial Shift over Years
Oct 01, 2024



Recent advancements in Spatiotemporal Graph Neural Networks (ST-GNNs) and Transformers have demonstrated promising potential for traffic forecasting by effectively capturing both temporal and spatial correlations. The generalization ability of spatiotemporal models has received considerable attention in recent scholarly discourse. However, no substantive datasets specifically addressing traffic out-of-distribution (OOD) scenarios have been proposed. Existing ST-OOD methods are either constrained to testing on extant data or necessitate manual modifications to the dataset. Consequently, the generalization capacity of current spatiotemporal models in OOD scenarios remains largely underexplored. In this paper, we investigate state-of-the-art models using newly proposed traffic OOD benchmarks and, surprisingly, find that these models experience a significant decline in performance. Through meticulous analysis, we attribute this decline to the models' inability to adapt to previously unobserved spatial relationships. To address this challenge, we propose a novel Mixture of Experts (MoE) framework, which learns a set of graph generators (i.e., graphons) during training and adaptively combines them to generate new graphs based on novel environmental conditions to handle spatial distribution shifts during testing. We further extend this concept to the Transformer architecture, achieving substantial improvements. Our method is both parsimonious and efficacious, and can be seamlessly integrated into any spatiotemporal model, outperforming current state-of-the-art approaches in addressing spatial dynamics.