 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTGformer: Efficient Spatiotemporal Graph Transformer for Traffic Forecasting
Oct 01, 2024



Traffic forecasting is a cornerstone of smart city management, enabling efficient resource allocation and transportation planning. Deep learning, with its ability to capture complex nonlinear patterns in spatiotemporal (ST) data, has emerged as a powerful tool for traffic forecasting. While graph neural networks (GCNs) and transformer-based models have shown promise, their computational demands often hinder their application to real-world road networks, particularly those with large-scale spatiotemporal interactions. To address these challenges, we propose a novel spatiotemporal graph transformer (STGformer) architecture. STGformer effectively balances the strengths of GCNs and Transformers, enabling efficient modeling of both global and local traffic patterns while maintaining a manageable computational footprint. Unlike traditional approaches that require multiple attention layers, STG attention block captures high-order spatiotemporal interactions in a single layer, significantly reducing computational cost. In particular, STGformer achieves a 100x speedup and a 99.8\% reduction in GPU memory usage compared to STAEformer during batch inference on a California road graph with 8,600 sensors. We evaluate STGformer on the LargeST benchmark and demonstrate its superiority over state-of-the-art Transformer-based methods such as PDFormer and STAEformer, which underline STGformer's potential to revolutionize traffic forecasting by overcoming the computational and memory limitations of existing approaches, making it a promising foundation for future spatiotemporal modeling tasks.
Robust Traffic Forecasting against Spatial Shift over Years
Oct 01, 2024



Recent advancements in Spatiotemporal Graph Neural Networks (ST-GNNs) and Transformers have demonstrated promising potential for traffic forecasting by effectively capturing both temporal and spatial correlations. The generalization ability of spatiotemporal models has received considerable attention in recent scholarly discourse. However, no substantive datasets specifically addressing traffic out-of-distribution (OOD) scenarios have been proposed. Existing ST-OOD methods are either constrained to testing on extant data or necessitate manual modifications to the dataset. Consequently, the generalization capacity of current spatiotemporal models in OOD scenarios remains largely underexplored. In this paper, we investigate state-of-the-art models using newly proposed traffic OOD benchmarks and, surprisingly, find that these models experience a significant decline in performance. Through meticulous analysis, we attribute this decline to the models' inability to adapt to previously unobserved spatial relationships. To address this challenge, we propose a novel Mixture of Experts (MoE) framework, which learns a set of graph generators (i.e., graphons) during training and adaptively combines them to generate new graphs based on novel environmental conditions to handle spatial distribution shifts during testing. We further extend this concept to the Transformer architecture, achieving substantial improvements. Our method is both parsimonious and efficacious, and can be seamlessly integrated into any spatiotemporal model, outperforming current state-of-the-art approaches in addressing spatial dynamics.
Easy Begun is Half Done: Spatial-Temporal Graph Modeling with ST-Curriculum Dropout
Nov 28, 2022



Spatial-temporal (ST) graph modeling, such as traffic speed forecasting and taxi demand prediction, is an important task in deep learning area. However, for the nodes in graph, their ST patterns can vary greatly in difficulties for modeling, owning to the heterogeneous nature of ST data. We argue that unveiling the nodes to the model in a meaningful order, from easy to complex, can provide performance improvements over traditional training procedure. The idea has its root in Curriculum Learning which suggests in the early stage of training models can be sensitive to noise and difficult samples. In this paper, we propose ST-Curriculum Dropout, a novel and easy-to-implement strategy for spatial-temporal graph modeling. Specifically, we evaluate the learning difficulty of each node in high-level feature space and drop those difficult ones out to ensure the model only needs to handle fundamental ST relations at the beginning, before gradually moving to hard ones. Our strategy can be applied to any canonical deep learning architecture without extra trainable parameters, and extensive experiments on a wide range of datasets are conducted to illustrate that, by controlling the difficulty level of ST relations as the training progresses, the model is able to capture better representation of the data and thus yields better generalization.
Multiplex-detection Based Multiple Instance Learning Network for Whole Slide Image Classification
Aug 06, 2022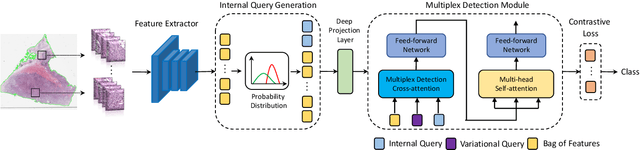
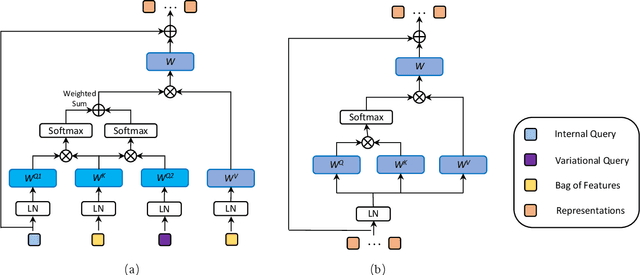
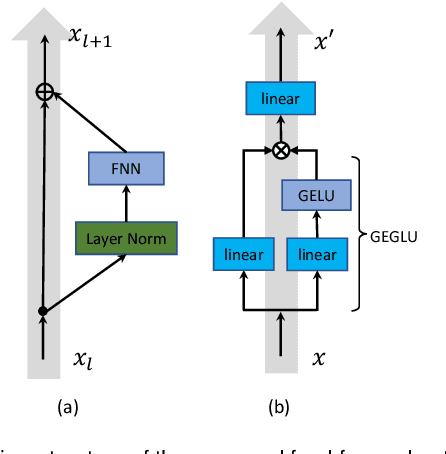
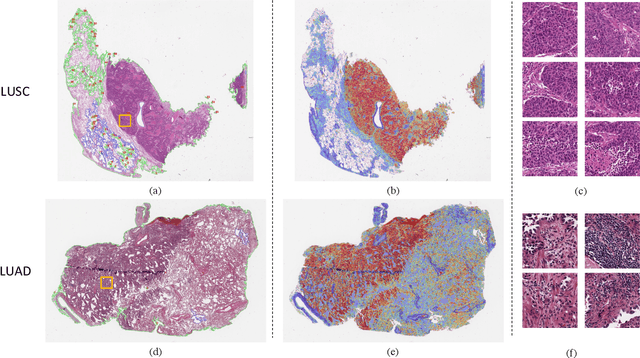
Multiple instance learning (MIL) is a powerful approach to classify whole slide images (WSIs) for diagnostic pathology. A fundamental challenge of MIL on WSI classification is to discover the \textit{critical instances} that trigger the bag label. However, previous methods are primarily designed under the independent and identical distribution hypothesis (\textit{i.i.d}), ignoring either the correlations between instances or heterogeneity of tumours. In this paper, we propose a novel multiplex-detection-based multiple instance learning (MDMIL) to tackle the issues above. Specifically, MDMIL is constructed by the internal query generation module (IQGM) and the multiplex detection module (MDM) and assisted by the memory-based contrastive loss during training. Firstly, IQGM gives the probability of instances and generates the internal query (IQ) for the subsequent MDM by aggregating highly reliable features after the distribution analysis. Secondly, the multiplex-detection cross-attention (MDCA) and multi-head self-attention (MHSA) in MDM cooperate to generate the final representations for the WSI. In this process, the IQ and trainable variational query (VQ) successfully build up the connections between instances and significantly improve the model's robustness toward heterogeneous tumours. At last, to further enforce constraints in the feature space and stabilize the training process, we adopt a memory-based contrastive loss, which is practicable for WSI classification even with a single sample as input in each iteration. We conduct experiments on three computational pathology datasets, e.g., CAMELYON16, TCGA-NSCLC, and TCGA-RCC datasets. The superior accuracy and AUC demonstrate the superiority of our proposed MDMIL over other state-of-the-art methods.