 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrototype-Guided Cross-Modal Knowledge Enhancement for Adaptive Survival Prediction
Mar 13, 2025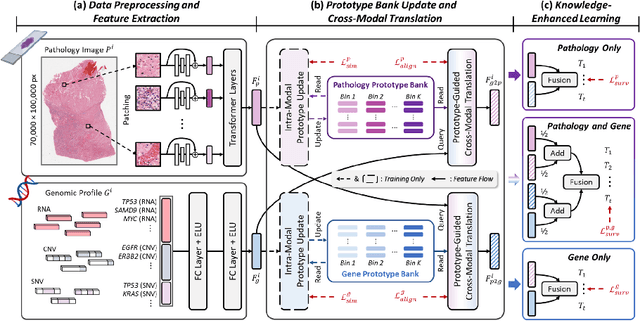
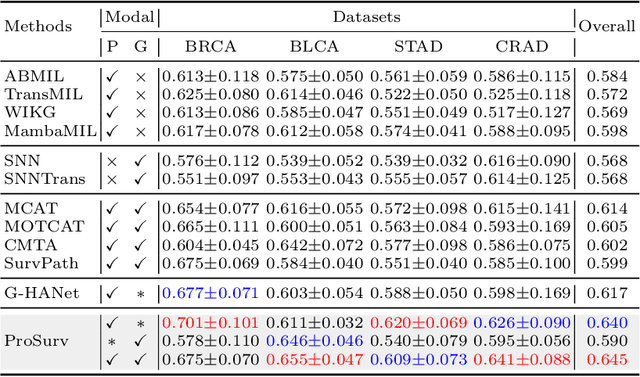
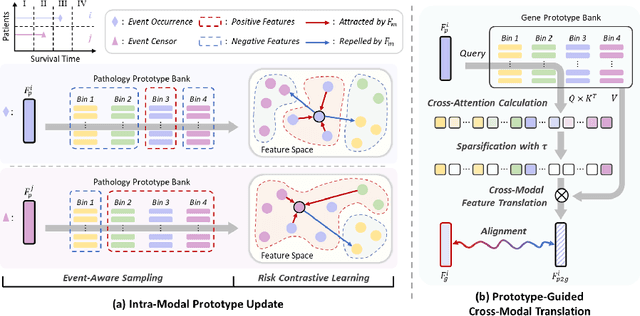
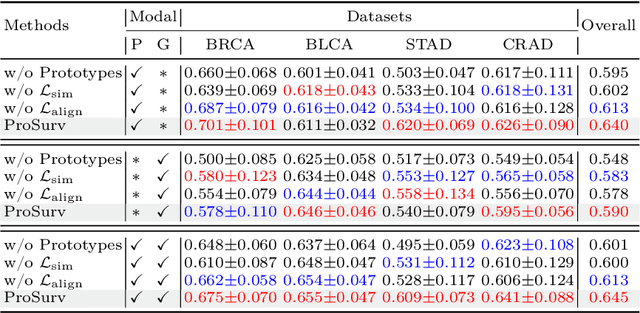
Histo-genomic multimodal survival prediction has garnered growing attention for its remarkable model performance and potential contributions to precision medicine. However, a significant challenge in clinical practice arises when only unimodal data is available, limiting the usability of these advanced multimodal methods. To address this issue, this study proposes a prototype-guided cross-modal knowledge enhancement (ProSurv) framework, which eliminates the dependency on paired data and enables robust learning and adaptive survival prediction. Specifically, we first introduce an intra-modal updating mechanism to construct modality-specific prototype banks that encapsulate the statistics of the whole training set and preserve the modality-specific risk-relevant features/prototypes across intervals. Subsequently, the proposed cross-modal translation module utilizes the learned prototypes to enhance knowledge representation for multimodal inputs and generate features for missing modalities, ensuring robust and adaptive survival prediction across diverse scenarios. Extensive experiments on four public datasets demonstrate the superiority of ProSurv over state-of-the-art methods using either unimodal or multimodal input, and the ablation study underscores its feasibility for broad applicability. Overall, this study addresses a critical practical challenge in computational pathology, offering substantial significance and potential impact in the field.
Rethinking Cancer Gene Identification through Graph Anomaly Analysis
Dec 23, 2024



Graph neural networks (GNNs) have shown promise in integrating protein-protein interaction (PPI) networks for identifying cancer genes in recent studies. However, due to the insufficient modeling of the biological information in PPI networks, more faithfully depiction of complex protein interaction patterns for cancer genes within the graph structure remains largely unexplored. This study takes a pioneering step toward bridging biological anomalies in protein interactions caused by cancer genes to statistical graph anomaly. We find a unique graph anomaly exhibited by cancer genes, namely weight heterogeneity, which manifests as significantly higher variance in edge weights of cancer gene nodes within the graph. Additionally, from the spectral perspective, we demonstrate that the weight heterogeneity could lead to the "flattening out" of spectral energy, with a concentration towards the extremes of the spectrum. Building on these insights, we propose the HIerarchical-Perspective Graph Neural Network (HIPGNN) that not only determines spectral energy distribution variations on the spectral perspective, but also perceives detailed protein interaction context on the spatial perspective. Extensive experiments are conducted on two reprocessed datasets STRINGdb and CPDB, and the experimental results demonstrate the superiority of HIPGNN.
Histo-Genomic Knowledge Distillation For Cancer Prognosis From Histopathology Whole Slide Images
Mar 18, 2024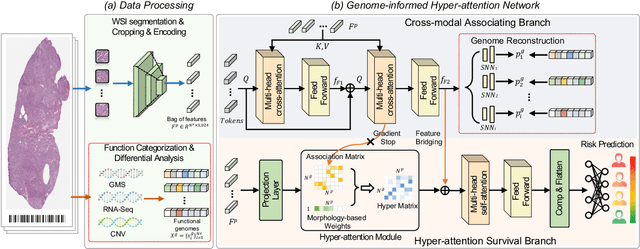
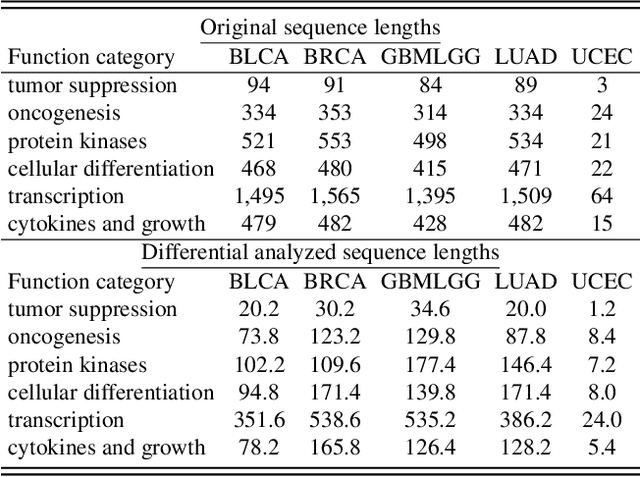
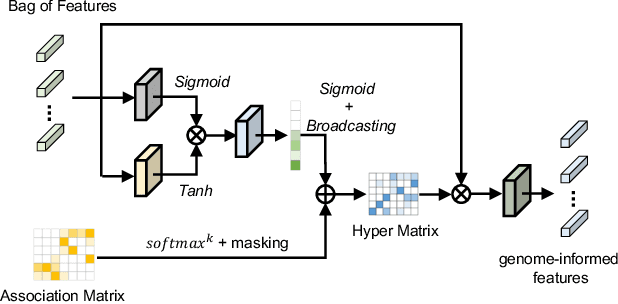
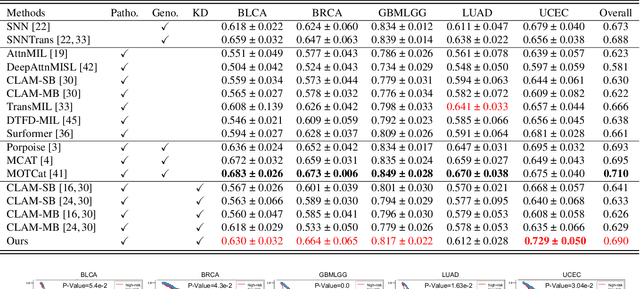
Histo-genomic multi-modal methods have recently emerged as a powerful paradigm, demonstrating significant potential for improving cancer prognosis. However, genome sequencing, unlike histopathology imaging, is still not widely accessible in underdeveloped regions, limiting the application of these multi-modal approaches in clinical settings. To address this, we propose a novel Genome-informed Hyper-Attention Network, termed G-HANet, which is capable of effectively distilling the histo-genomic knowledge during training to elevate uni-modal whole slide image (WSI)-based inference for the first time. Compared with traditional knowledge distillation methods (i.e., teacher-student architecture) in other tasks, our end-to-end model is superior in terms of training efficiency and learning cross-modal interactions. Specifically, the network comprises the cross-modal associating branch (CAB) and hyper-attention survival branch (HSB). Through the genomic data reconstruction from WSIs, CAB effectively distills the associations between functional genotypes and morphological phenotypes and offers insights into the gene expression profiles in the feature space. Subsequently, HSB leverages the distilled histo-genomic associations as well as the generated morphology-based weights to achieve the hyper-attention modeling of the patients from both histopathology and genomic perspectives to improve cancer prognosis. Extensive experiments are conducted on five TCGA benchmarking datasets and the results demonstrate that G-HANet significantly outperforms the state-of-the-art WSI-based methods and achieves competitive performance with genome-based and multi-modal methods. G-HANet is expected to be explored as a useful tool by the research community to address the current bottleneck of insufficient histo-genomic data pairing in the context of cancer prognosis and precision oncology.
Control of Continuous Quantum Systems with Many Degrees of Freedom based on Convergent Reinforcement Learning
Dec 21, 2022



With the development of experimental quantum technology, quantum control has attracted increasing attention due to the realization of controllable artificial quantum systems. However, because quantum-mechanical systems are often too difficult to analytically deal with, heuristic strategies and numerical algorithms which search for proper control protocols are adopted, and, deep learning, especially deep reinforcement learning (RL), is a promising generic candidate solution for the control problems. Although there have been a few successful applications of deep RL to quantum control problems, most of the existing RL algorithms suffer from instabilities and unsatisfactory reproducibility, and require a large amount of fine-tuning and a large computational budget, both of which limit their applicability. To resolve the issue of instabilities, in this dissertation, we investigate the non-convergence issue of Q-learning. Then, we investigate the weakness of existing convergent approaches that have been proposed, and we develop a new convergent Q-learning algorithm, which we call the convergent deep Q network (C-DQN) algorithm, as an alternative to the conventional deep Q network (DQN) algorithm. We prove the convergence of C-DQN and apply it to the Atari 2600 benchmark. We show that when DQN fail, C-DQN still learns successfully. Then, we apply the algorithm to the measurement-feedback cooling problems of a quantum quartic oscillator and a trapped quantum rigid body. We establish the physical models and analyse their properties, and we show that although both C-DQN and DQN can learn to cool the systems, C-DQN tends to behave more stably, and when DQN suffers from instabilities, C-DQN can achieve a better performance. As the performance of DQN can have a large variance and lack consistency, C-DQN can be a better choice for researches on complicated control problems.
Quantum Control based on Deep Reinforcement Learning
Dec 14, 2022In this thesis, we consider two simple but typical control problems and apply deep reinforcement learning to them, i.e., to cool and control a particle which is subject to continuous position measurement in a one-dimensional quadratic potential or in a quartic potential. We compare the performance of reinforcement learning control and conventional control strategies on the two problems, and show that the reinforcement learning achieves a performance comparable to the optimal control for the quadratic case, and outperforms conventional control strategies for the quartic case for which the optimal control strategy is unknown. To our knowledge, this is the first time deep reinforcement learning is applied to quantum control problems in continuous real space. Our research demonstrates that deep reinforcement learning can be used to control a stochastic quantum system in real space effectively as a measurement-feedback closed-loop controller, and our research also shows the ability of AI to discover new control strategies and properties of the quantum systems that are not well understood, and we can gain insights into these problems by learning from the AI, which opens up a new regime for scientific research.
Multiplex-detection Based Multiple Instance Learning Network for Whole Slide Image Classification
Aug 06, 2022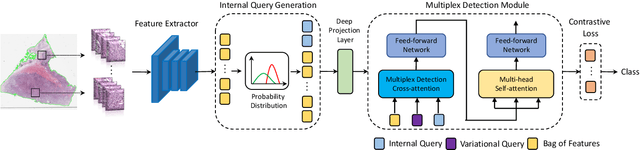
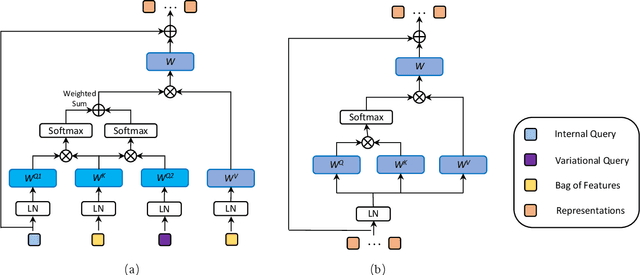
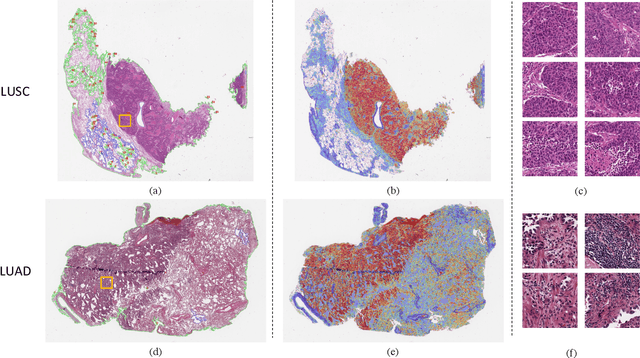
Multiple instance learning (MIL) is a powerful approach to classify whole slide images (WSIs) for diagnostic pathology. A fundamental challenge of MIL on WSI classification is to discover the \textit{critical instances} that trigger the bag label. However, previous methods are primarily designed under the independent and identical distribution hypothesis (\textit{i.i.d}), ignoring either the correlations between instances or heterogeneity of tumours. In this paper, we propose a novel multiplex-detection-based multiple instance learning (MDMIL) to tackle the issues above. Specifically, MDMIL is constructed by the internal query generation module (IQGM) and the multiplex detection module (MDM) and assisted by the memory-based contrastive loss during training. Firstly, IQGM gives the probability of instances and generates the internal query (IQ) for the subsequent MDM by aggregating highly reliable features after the distribution analysis. Secondly, the multiplex-detection cross-attention (MDCA) and multi-head self-attention (MHSA) in MDM cooperate to generate the final representations for the WSI. In this process, the IQ and trainable variational query (VQ) successfully build up the connections between instances and significantly improve the model's robustness toward heterogeneous tumours. At last, to further enforce constraints in the feature space and stabilize the training process, we adopt a memory-based contrastive loss, which is practicable for WSI classification even with a single sample as input in each iteration. We conduct experiments on three computational pathology datasets, e.g., CAMELYON16, TCGA-NSCLC, and TCGA-RCC datasets. The superior accuracy and AUC demonstrate the superiority of our proposed MDMIL over other state-of-the-art methods.
Feature Erasing and Diffusion Network for Occluded Person Re-Identification
Dec 16, 2021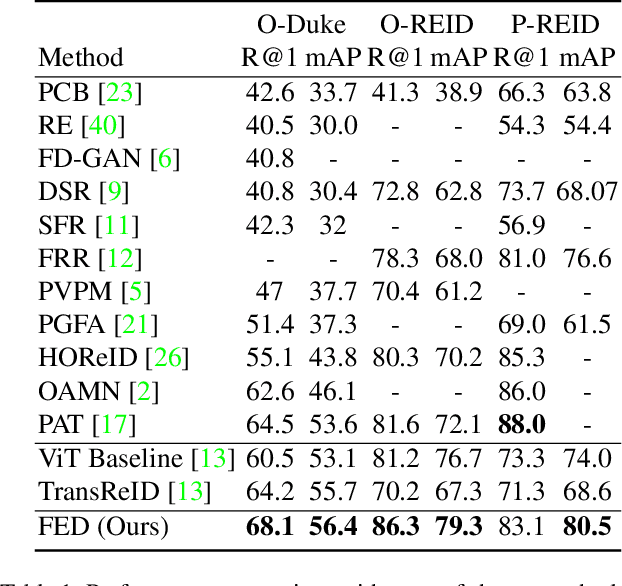
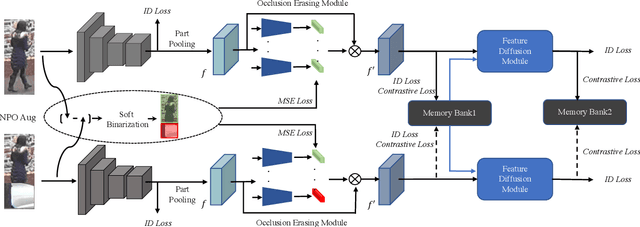
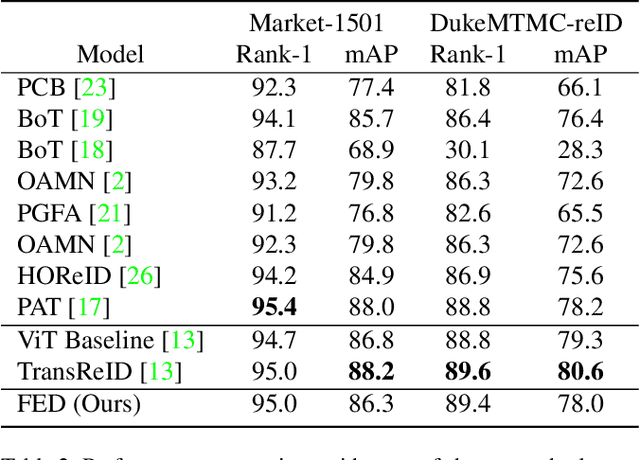
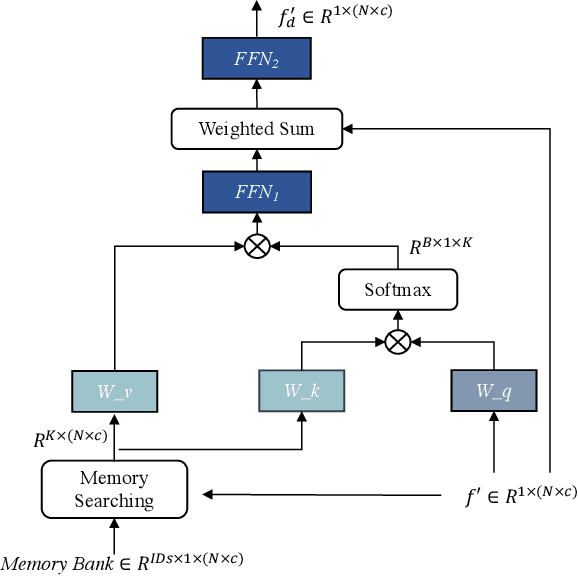
Occluded person re-identification (ReID) aims at matching occluded person images to holistic ones across different camera views. Target Pedestrians (TP) are usually disturbed by Non-Pedestrian Occlusions (NPO) and NonTarget Pedestrians (NTP). Previous methods mainly focus on increasing model's robustness against NPO while ignoring feature contamination from NTP. In this paper, we propose a novel Feature Erasing and Diffusion Network (FED) to simultaneously handle NPO and NTP. Specifically, NPO features are eliminated by our proposed Occlusion Erasing Module (OEM), aided by the NPO augmentation strategy which simulates NPO on holistic pedestrian images and generates precise occlusion masks. Subsequently, we Subsequently, we diffuse the pedestrian representations with other memorized features to synthesize NTP characteristics in the feature space which is achieved by a novel Feature Diffusion Module (FDM) through a learnable cross attention mechanism. With the guidance of the occlusion scores from OEM, the feature diffusion process is mainly conducted on visible body parts, which guarantees the quality of the synthesized NTP characteristics. By jointly optimizing OEM and FDM in our proposed FED network, we can greatly improve the model's perception ability towards TP and alleviate the influence of NPO and NTP. Furthermore, the proposed FDM only works as an auxiliary module for training and will be discarded in the inference phase, thus introducing little inference computational overhead. Experiments on occluded and holistic person ReID benchmarks demonstrate the superiority of FED over state-of-the-arts, where FED achieves 86.3% Rank-1 accuracy on Occluded-REID, surpassing others by at least 4.7%.
Image-to-Video Generation via 3D Facial Dynamics
May 31, 2021
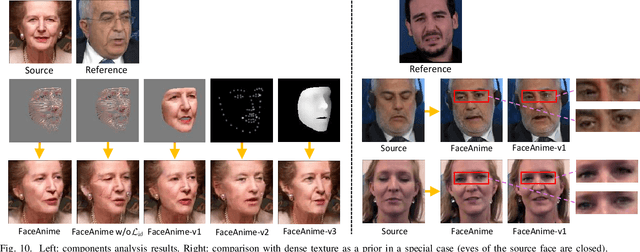
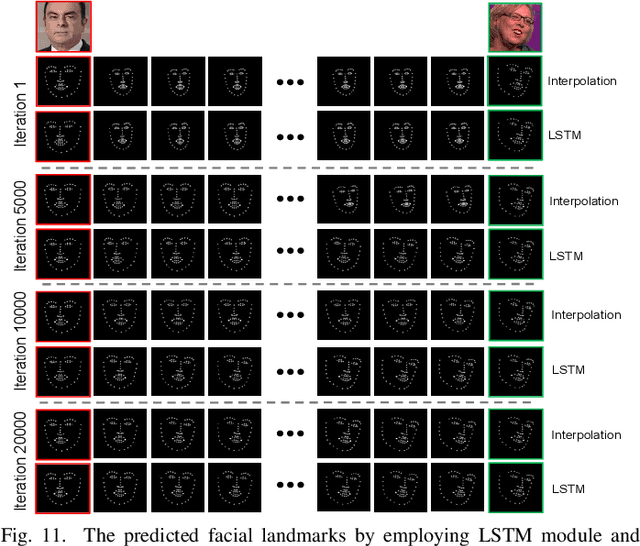
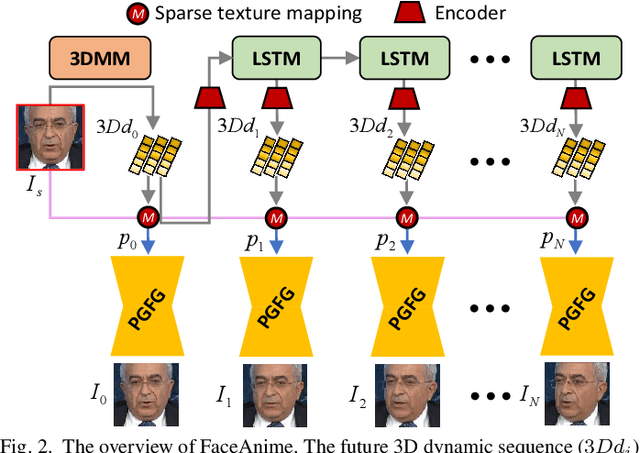
We present a versatile model, FaceAnime, for various video generation tasks from still images. Video generation from a single face image is an interesting problem and usually tackled by utilizing Generative Adversarial Networks (GANs) to integrate information from the input face image and a sequence of sparse facial landmarks. However, the generated face images usually suffer from quality loss, image distortion, identity change, and expression mismatching due to the weak representation capacity of the facial landmarks. In this paper, we propose to "imagine" a face video from a single face image according to the reconstructed 3D face dynamics, aiming to generate a realistic and identity-preserving face video, with precisely predicted pose and facial expression. The 3D dynamics reveal changes of the facial expression and motion, and can serve as a strong prior knowledge for guiding highly realistic face video generation. In particular, we explore face video prediction and exploit a well-designed 3D dynamic prediction network to predict a 3D dynamic sequence for a single face image. The 3D dynamics are then further rendered by the sparse texture mapping algorithm to recover structural details and sparse textures for generating face frames. Our model is versatile for various AR/VR and entertainment applications, such as face video retargeting and face video prediction. Superior experimental results have well demonstrated its effectiveness in generating high-fidelity, identity-preserving, and visually pleasant face video clips from a single source face image.
Robust Person Re-Identification through Contextual Mutual Boosting
Sep 16, 2020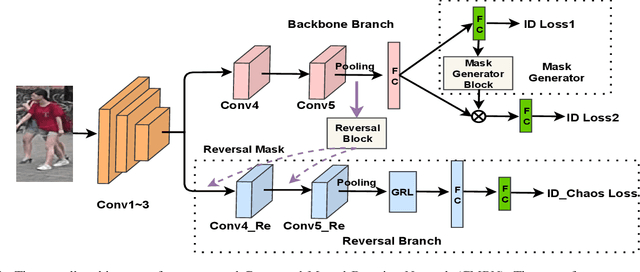
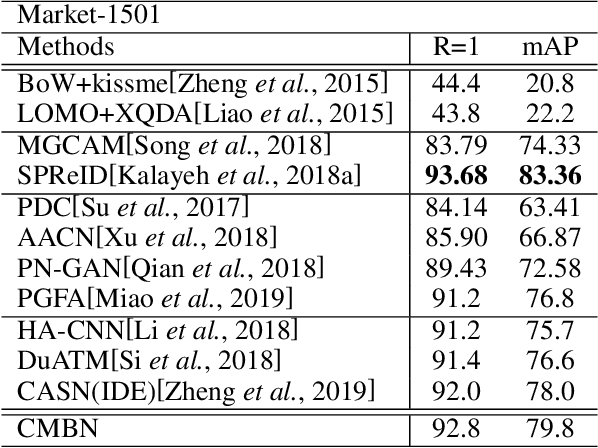
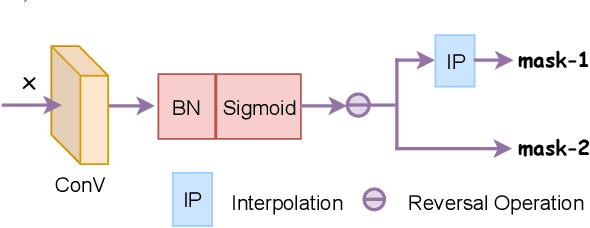
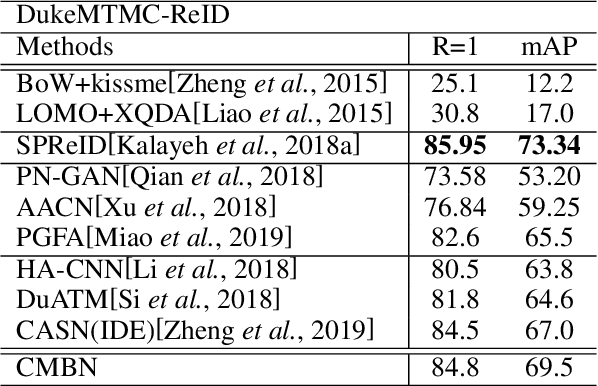
Person Re-Identification (Re-ID) has witnessed great advance, driven by the development of deep learning. However, modern person Re-ID is still challenged by background clutter, occlusion and large posture variation which are common in practice. Previous methods tackle these challenges by localizing pedestrians through external cues (e.g., pose estimation, human parsing) or attention mechanism, suffering from high computation cost and increased model complexity. In this paper, we propose the Contextual Mutual Boosting Network (CMBN). It localizes pedestrians and recalibrates features by effectively exploiting contextual information and statistical inference. Firstly, we construct two branches with a shared convolutional frontend to learn the foreground and background features respectively. By enabling interaction between these two branches, they boost the accuracy of the spatial localization mutually. Secondly, starting from a statistical perspective, we propose the Mask Generator that exploits the activation distribution of the transformation matrix for generating the static channel mask to the representations. The mask recalibrates the features to amplify the valuable characteristics and diminish the noise. Finally, we propose the Contextual-Detachment Strategy to optimize the two branches jointly and independently, which further enhances the localization precision. Experiments on the benchmarks demonstrate the superiority of the architecture compared the state-of-the-art.
Deep Gamblers: Learning to Abstain with Portfolio Theory
Jun 29, 2019


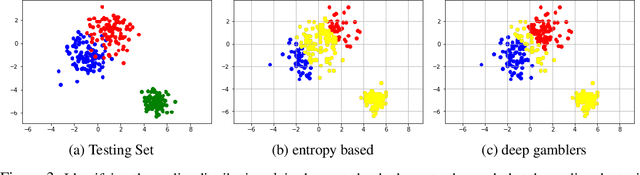
We deal with the \textit{selective classification} problem (supervised-learning problem with a rejection option), where we want to achieve the best performance at a certain level of coverage of the data. We transform the original $m$-class classification problem to $(m+1)$-class where the $(m+1)$-th class represents the model abstaining from making a prediction due to uncertainty. Inspired by portfolio theory, we propose a loss function for the selective classification problem based on the doubling rate of gambling. We show that minimizing this loss function has a natural interpretation as maximizing the return of a \textit{horse race}, where a player aims to balance between betting on an outcome (making a prediction) when confident and reserving one's winnings (abstaining) when not confident. This loss function allows us to train neural networks and characterize the uncertainty of prediction in an end-to-end fashion. In comparison with previous methods, our method requires almost no modification to the model inference algorithm or neural architecture. Experimentally, we show that our method can identify both uncertain and outlier data points, and achieves strong results on SVHN and CIFAR10 at various coverages of the data.