 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating remote sensing data assimilation, deep learning and large language model for interactive wheat breeding yield prediction
Jan 08, 2025



Yield is one of the core goals of crop breeding. By predicting the potential yield of different breeding materials, breeders can screen these materials at various growth stages to select the best performing. Based on unmanned aerial vehicle remote sensing technology, high-throughput crop phenotyping data in breeding areas is collected to provide data support for the breeding decisions of breeders. However, the accuracy of current yield predictions still requires improvement, and the usability and user-friendliness of yield forecasting tools remain suboptimal. To address these challenges, this study introduces a hybrid method and tool for crop yield prediction, designed to allow breeders to interactively and accurately predict wheat yield by chatting with a large language model (LLM). First, the newly designed data assimilation algorithm is used to assimilate the leaf area index into the WOFOST model. Then, selected outputs from the assimilation process, along with remote sensing inversion results, are used to drive the time-series temporal fusion transformer model for wheat yield prediction. Finally, based on this hybrid method and leveraging an LLM with retrieval augmented generation technology, we developed an interactive yield prediction Web tool that is user-friendly and supports sustainable data updates. This tool integrates multi-source data to assist breeding decision-making. This study aims to accelerate the identification of high-yield materials in the breeding process, enhance breeding efficiency, and enable more scientific and smart breeding decisions.
Learning to Complement and to Defer to Multiple Users
Jul 09, 2024



With the development of Human-AI Collaboration in Classification (HAI-CC), integrating users and AI predictions becomes challenging due to the complex decision-making process. This process has three options: 1) AI autonomously classifies, 2) learning to complement, where AI collaborates with users, and 3) learning to defer, where AI defers to users. Despite their interconnected nature, these options have been studied in isolation rather than as components of a unified system. In this paper, we address this weakness with the novel HAI-CC methodology, called Learning to Complement and to Defer to Multiple Users (LECODU). LECODU not only combines learning to complement and learning to defer strategies, but it also incorporates an estimation of the optimal number of users to engage in the decision process. The training of LECODU maximises classification accuracy and minimises collaboration costs associated with user involvement. Comprehensive evaluations across real-world and synthesized datasets demonstrate LECODU's superior performance compared to state-of-the-art HAI-CC methods. Remarkably, even when relying on unreliable users with high rates of label noise, LECODU exhibits significant improvement over both human decision-makers alone and AI alone.
Image-to-Video Generation via 3D Facial Dynamics
May 31, 2021
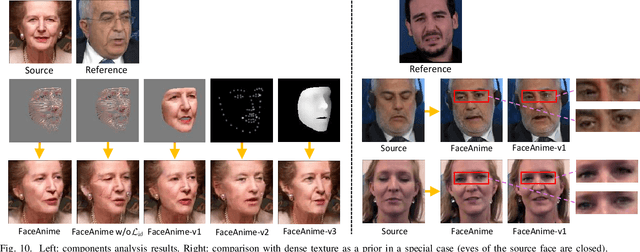
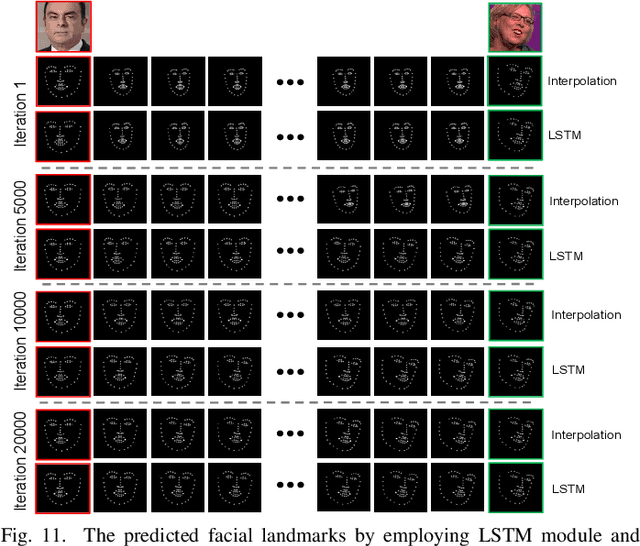
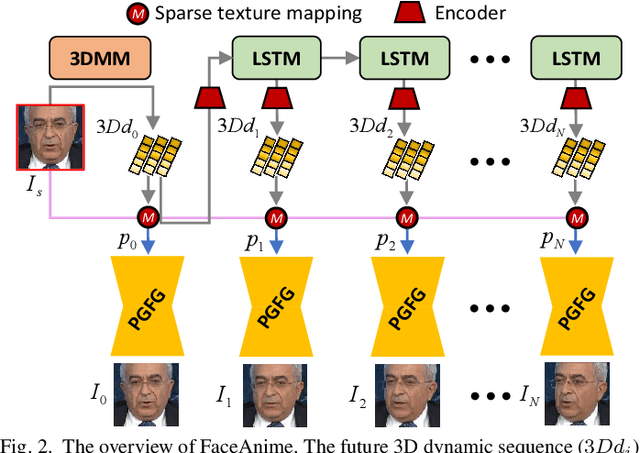
We present a versatile model, FaceAnime, for various video generation tasks from still images. Video generation from a single face image is an interesting problem and usually tackled by utilizing Generative Adversarial Networks (GANs) to integrate information from the input face image and a sequence of sparse facial landmarks. However, the generated face images usually suffer from quality loss, image distortion, identity change, and expression mismatching due to the weak representation capacity of the facial landmarks. In this paper, we propose to "imagine" a face video from a single face image according to the reconstructed 3D face dynamics, aiming to generate a realistic and identity-preserving face video, with precisely predicted pose and facial expression. The 3D dynamics reveal changes of the facial expression and motion, and can serve as a strong prior knowledge for guiding highly realistic face video generation. In particular, we explore face video prediction and exploit a well-designed 3D dynamic prediction network to predict a 3D dynamic sequence for a single face image. The 3D dynamics are then further rendered by the sparse texture mapping algorithm to recover structural details and sparse textures for generating face frames. Our model is versatile for various AR/VR and entertainment applications, such as face video retargeting and face video prediction. Superior experimental results have well demonstrated its effectiveness in generating high-fidelity, identity-preserving, and visually pleasant face video clips from a single source face image.
Joint Face Image Restoration and Frontalization for Recognition
May 12, 2021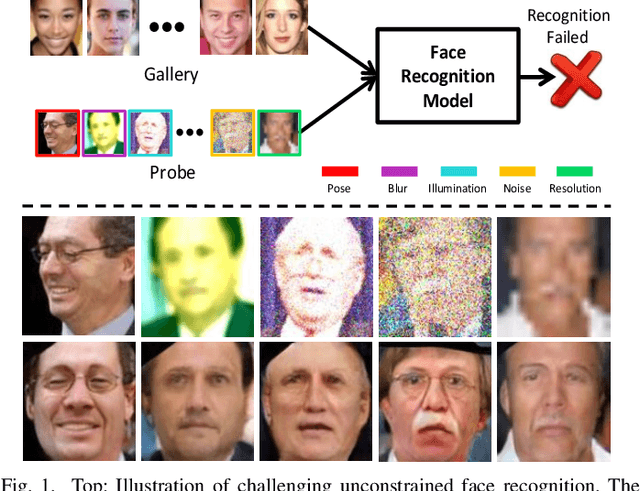
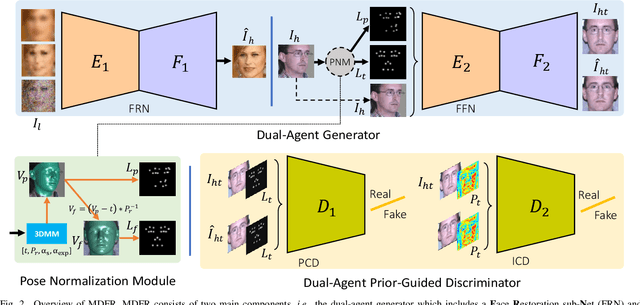
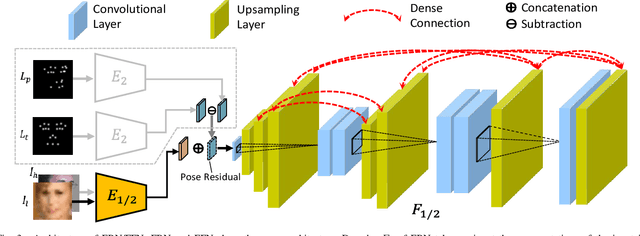
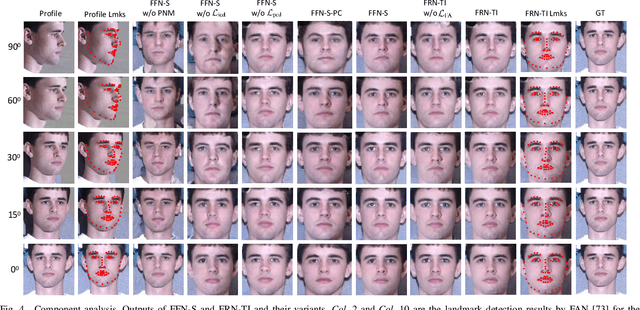
In real-world scenarios, many factors may harm face recognition performance, e.g., large pose, bad illumination,low resolution, blur and noise. To address these challenges, previous efforts usually first restore the low-quality faces to high-quality ones and then perform face recognition. However, most of these methods are stage-wise, which is sub-optimal and deviates from the reality. In this paper, we address all these challenges jointly for unconstrained face recognition. We propose an Multi-Degradation Face Restoration (MDFR) model to restore frontalized high-quality faces from the given low-quality ones under arbitrary facial poses, with three distinct novelties. First, MDFR is a well-designed encoder-decoder architecture which extracts feature representation from an input face image with arbitrary low-quality factors and restores it to a high-quality counterpart. Second, MDFR introduces a pose residual learning strategy along with a 3D-based Pose Normalization Module (PNM), which can perceive the pose gap between the input initial pose and its real-frontal pose to guide the face frontalization. Finally, MDFR can generate frontalized high-quality face images by a single unified network, showing a strong capability of preserving face identity. Qualitative and quantitative experiments on both controlled and in-the-wild benchmarks demonstrate the superiority of MDFR over state-of-the-art methods on both face frontalization and face restoration.
Single Image Super-Resolution via Residual Neuron Attention Networks
May 21, 2020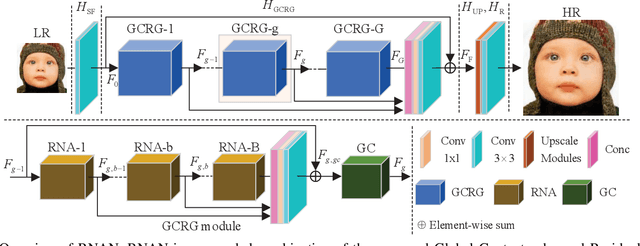
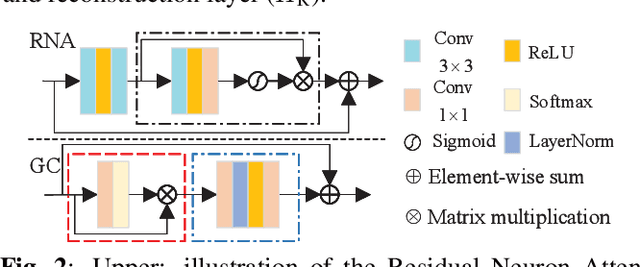
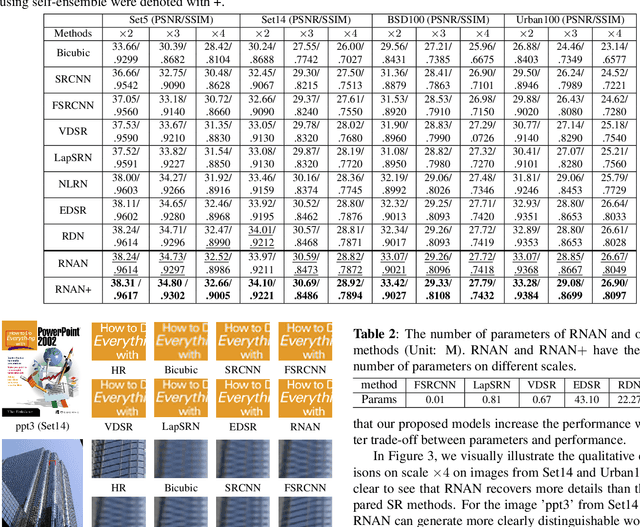
Deep Convolutional Neural Networks (DCNNs) have achieved impressive performance in Single Image Super-Resolution (SISR). To further improve the performance, existing CNN-based methods generally focus on designing deeper architecture of the network. However, we argue blindly increasing network's depth is not the most sensible way. In this paper, we propose a novel end-to-end Residual Neuron Attention Networks (RNAN) for more efficient and effective SISR. Structurally, our RNAN is a sequential integration of the well-designed Global Context-enhanced Residual Groups (GCRGs), which extracts super-resolved features from coarse to fine. Our GCRG is designed with two novelties. Firstly, the Residual Neuron Attention (RNA) mechanism is proposed in each block of GCRG to reveal the relevance of neurons for better feature representation. Furthermore, the Global Context (GC) block is embedded into RNAN at the end of each GCRG for effectively modeling the global contextual information. Experiments results demonstrate that our RNAN achieves the comparable results with state-of-the-art methods in terms of both quantitative metrics and visual quality, however, with simplified network architecture.