 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Light Image Enhancement by Learning Contrastive Representations in Spatial and Frequency Domains
Mar 23, 2023



Images taken under low-light conditions tend to suffer from poor visibility, which can decrease image quality and even reduce the performance of the downstream tasks. It is hard for a CNN-based method to learn generalized features that can recover normal images from the ones under various unknow low-light conditions. In this paper, we propose to incorporate the contrastive learning into an illumination correction network to learn abstract representations to distinguish various low-light conditions in the representation space, with the purpose of enhancing the generalizability of the network. Considering that light conditions can change the frequency components of the images, the representations are learned and compared in both spatial and frequency domains to make full advantage of the contrastive learning. The proposed method is evaluated on LOL and LOL-V2 datasets, the results show that the proposed method achieves better qualitative and quantitative results compared with other state-of-the-arts.
Image-to-Video Generation via 3D Facial Dynamics
May 31, 2021
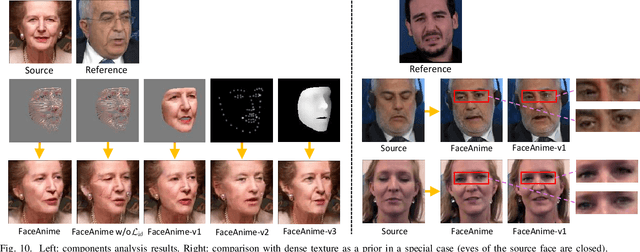
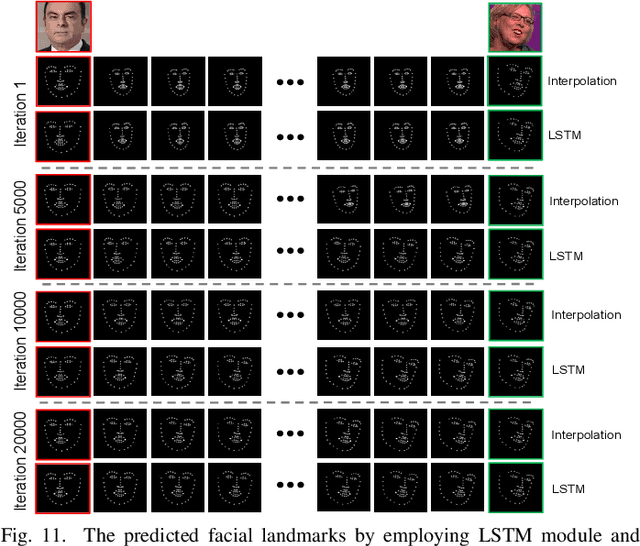
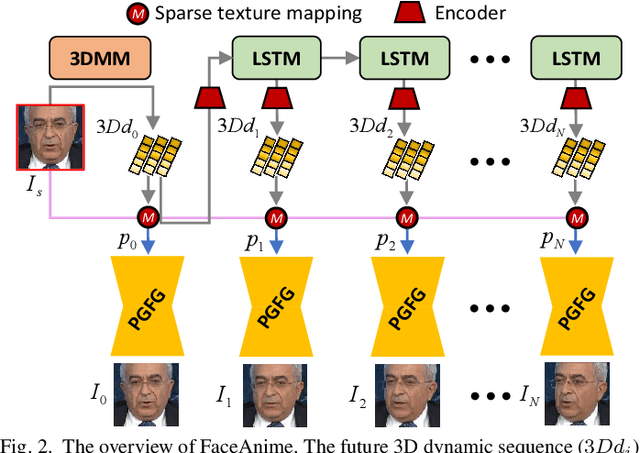
We present a versatile model, FaceAnime, for various video generation tasks from still images. Video generation from a single face image is an interesting problem and usually tackled by utilizing Generative Adversarial Networks (GANs) to integrate information from the input face image and a sequence of sparse facial landmarks. However, the generated face images usually suffer from quality loss, image distortion, identity change, and expression mismatching due to the weak representation capacity of the facial landmarks. In this paper, we propose to "imagine" a face video from a single face image according to the reconstructed 3D face dynamics, aiming to generate a realistic and identity-preserving face video, with precisely predicted pose and facial expression. The 3D dynamics reveal changes of the facial expression and motion, and can serve as a strong prior knowledge for guiding highly realistic face video generation. In particular, we explore face video prediction and exploit a well-designed 3D dynamic prediction network to predict a 3D dynamic sequence for a single face image. The 3D dynamics are then further rendered by the sparse texture mapping algorithm to recover structural details and sparse textures for generating face frames. Our model is versatile for various AR/VR and entertainment applications, such as face video retargeting and face video prediction. Superior experimental results have well demonstrated its effectiveness in generating high-fidelity, identity-preserving, and visually pleasant face video clips from a single source face image.
Joint Face Image Restoration and Frontalization for Recognition
May 12, 2021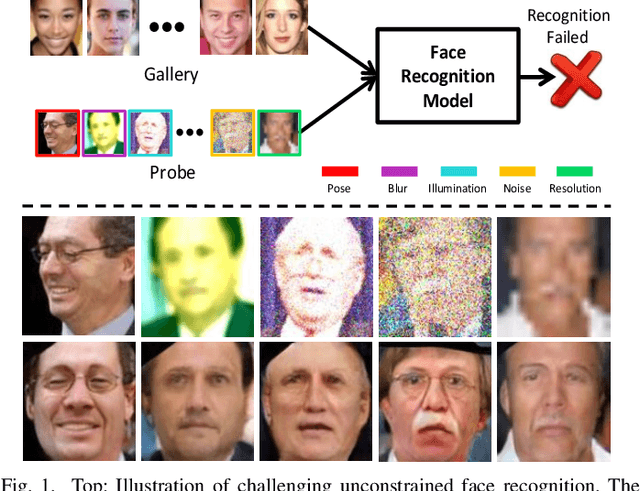
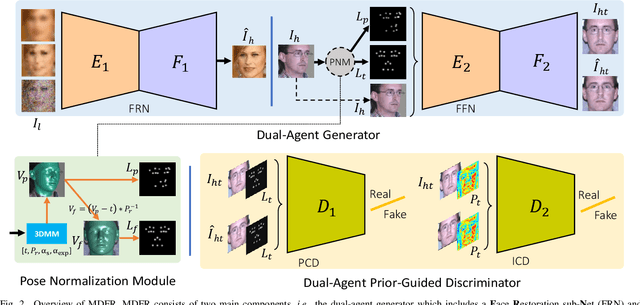
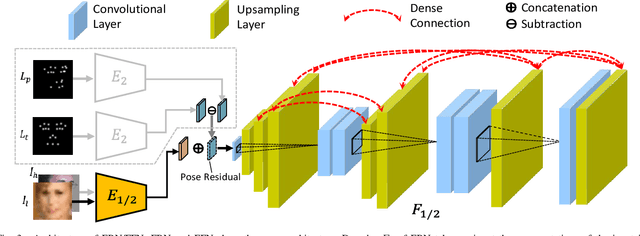
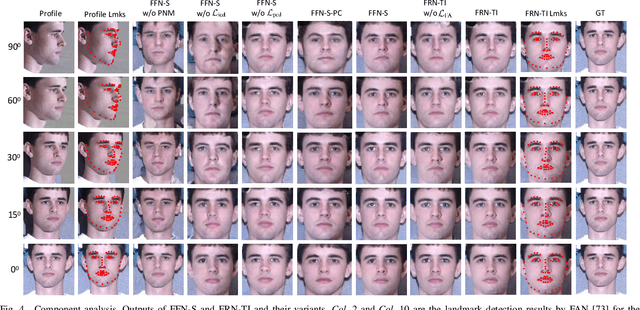
In real-world scenarios, many factors may harm face recognition performance, e.g., large pose, bad illumination,low resolution, blur and noise. To address these challenges, previous efforts usually first restore the low-quality faces to high-quality ones and then perform face recognition. However, most of these methods are stage-wise, which is sub-optimal and deviates from the reality. In this paper, we address all these challenges jointly for unconstrained face recognition. We propose an Multi-Degradation Face Restoration (MDFR) model to restore frontalized high-quality faces from the given low-quality ones under arbitrary facial poses, with three distinct novelties. First, MDFR is a well-designed encoder-decoder architecture which extracts feature representation from an input face image with arbitrary low-quality factors and restores it to a high-quality counterpart. Second, MDFR introduces a pose residual learning strategy along with a 3D-based Pose Normalization Module (PNM), which can perceive the pose gap between the input initial pose and its real-frontal pose to guide the face frontalization. Finally, MDFR can generate frontalized high-quality face images by a single unified network, showing a strong capability of preserving face identity. Qualitative and quantitative experiments on both controlled and in-the-wild benchmarks demonstrate the superiority of MDFR over state-of-the-art methods on both face frontalization and face restoration.
Single Image Super-Resolution via Residual Neuron Attention Networks
May 21, 2020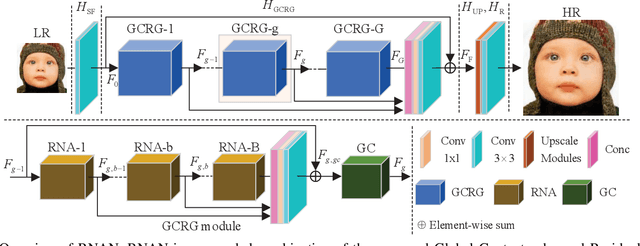
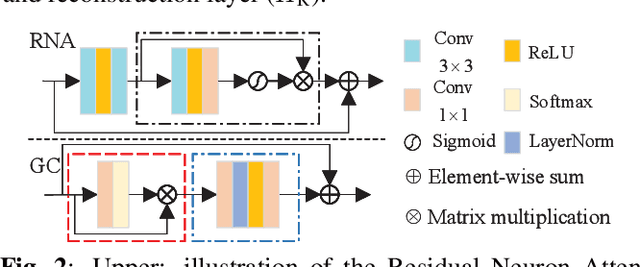
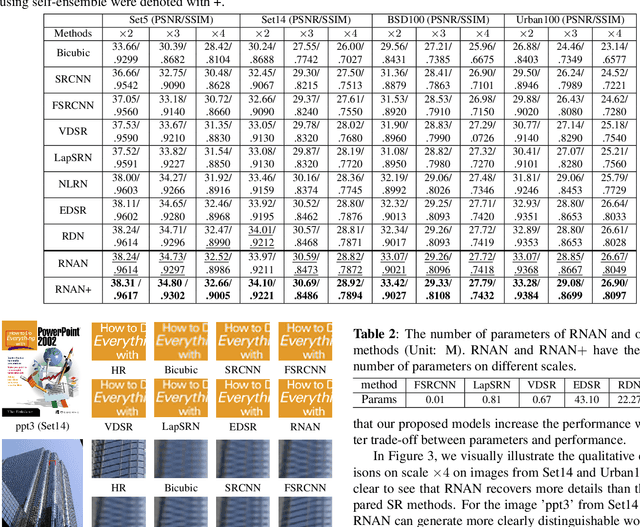
Deep Convolutional Neural Networks (DCNNs) have achieved impressive performance in Single Image Super-Resolution (SISR). To further improve the performance, existing CNN-based methods generally focus on designing deeper architecture of the network. However, we argue blindly increasing network's depth is not the most sensible way. In this paper, we propose a novel end-to-end Residual Neuron Attention Networks (RNAN) for more efficient and effective SISR. Structurally, our RNAN is a sequential integration of the well-designed Global Context-enhanced Residual Groups (GCRGs), which extracts super-resolved features from coarse to fine. Our GCRG is designed with two novelties. Firstly, the Residual Neuron Attention (RNA) mechanism is proposed in each block of GCRG to reveal the relevance of neurons for better feature representation. Furthermore, the Global Context (GC) block is embedded into RNAN at the end of each GCRG for effectively modeling the global contextual information. Experiments results demonstrate that our RNAN achieves the comparable results with state-of-the-art methods in terms of both quantitative metrics and visual quality, however, with simplified network architecture.
What's the relationship between CNNs and communication systems?
Mar 03, 2020The interpretability of Convolutional Neural Networks (CNNs) is an important topic in the field of computer vision. In recent years, works in this field generally adopt a mature model to reveal the internal mechanism of CNNs, helping to understand CNNs thoroughly. In this paper, we argue the working mechanism of CNNs can be revealed through a totally different interpretation, by comparing the communication systems and CNNs. This paper successfully obtained the corresponding relationship between the modules of the two, and verified the rationality of the corresponding relationship with experiments. Finally, through the analysis of some cutting-edge research on neural networks, we find the inherent relation between these two tasks can be of help in explaining these researches reasonably, as well as helping us discover the correct research direction of neural networks.
Defending from adversarial examples with a two-stream architecture
Dec 30, 2019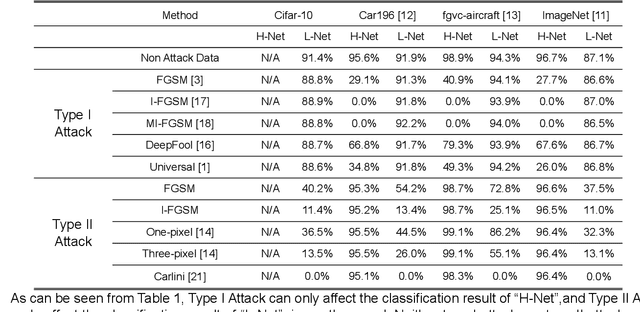
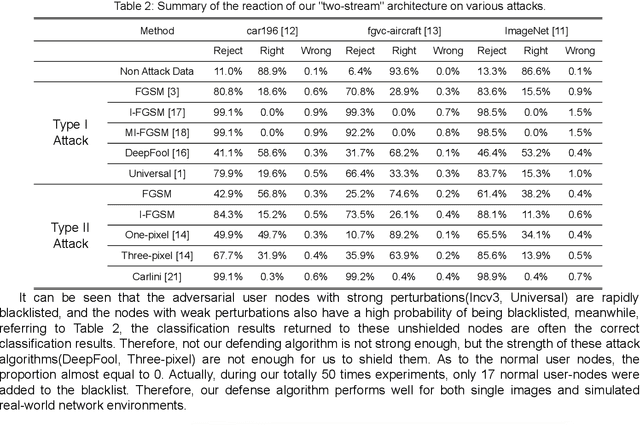
In recent years, deep learning has shown impressive performance on many tasks. However, recent researches showed that deep learning systems are vulnerable to small, specially crafted perturbations that are imperceptible to humans. Images with such perturbations are the so called adversarial examples, which have proven to be an indisputable threat to the DNN based applications. The lack of better understanding of the DNNs has prevented the development of efficient defenses against adversarial examples. In this paper, we propose a two-stream architecture to protect CNN from attacking by adversarial examples. Our model draws on the idea of "two-stream" which commonly used in the security field, and successfully defends different kinds of attack methods by the differences of "high-resolution" and "low-resolution" networks in feature extraction. We provide a reasonable interpretation on why our two-stream architecture is difficult to defeat, and show experimentally that our method is hard to defeat with state-of-the-art attacks. We demonstrate that our two-stream architecture is robust to adversarial examples built by currently known attacking algorithms.
Cross-Resolution Face Recognition via Prior-Aided Face Hallucination and Residual Knowledge Distillation
May 26, 2019


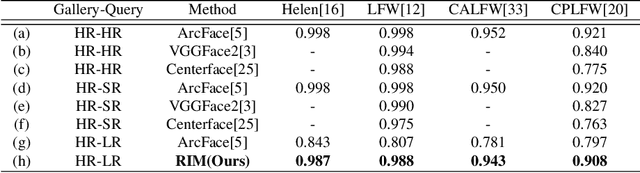
Recent deep learning based face recognition methods have achieved great performance, but it still remains challenging to recognize very low-resolution query face like 28x28 pixels when CCTV camera is far from the captured subject. Such face with very low-resolution is totally out of detail information of the face identity compared to normal resolution in a gallery and hard to find corresponding faces therein. To this end, we propose a Resolution Invariant Model (RIM) for addressing such cross-resolution face recognition problems, with three distinct novelties. First, RIM is a novel and unified deep architecture, containing a Face Hallucination sub-Net (FHN) and a Heterogeneous Recognition sub-Net (HRN), which are jointly learned end to end. Second, FHN is a well-designed tri-path Generative Adversarial Network (GAN) which simultaneously perceives facial structure and geometry prior information, i.e. landmark heatmaps and parsing maps, incorporated with an unsupervised cross-domain adversarial training strategy to super-resolve very low-resolution query image to its 8x larger ones without requiring them to be well aligned. Third, HRN is a generic Convolutional Neural Network (CNN) for heterogeneous face recognition with our proposed residual knowledge distillation strategy for learning discriminative yet generalized feature representation. Quantitative and qualitative experiments on several benchmarks demonstrate the superiority of the proposed model over the state-of-the-arts. Codes and models will be released upon acceptance.
Learning Robust 3D Face Reconstruction and Discriminative Identity Representation
May 16, 2019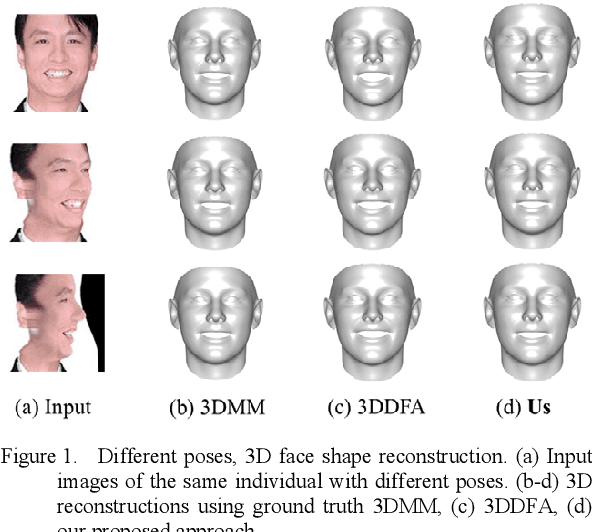
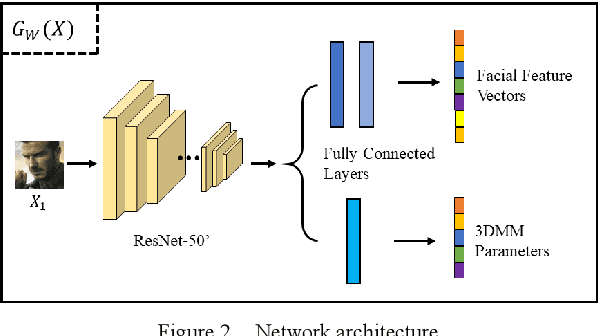
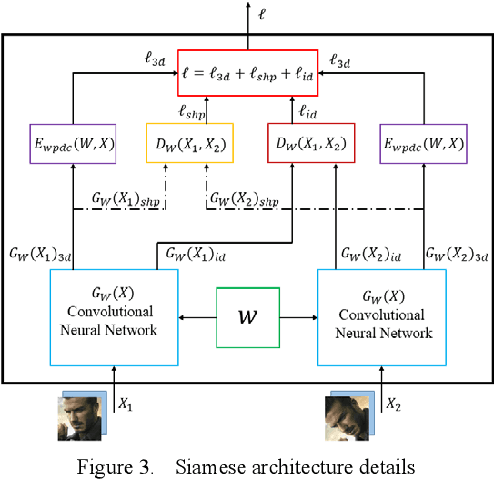
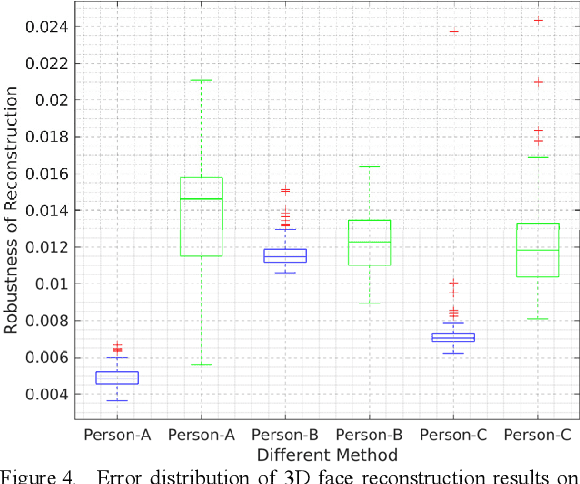
3D face reconstruction from a single 2D image is a very important topic in computer vision. However, the current reconstruction methods are usually non-sensitive to face identities and over-sensitive to facial poses, which may result in similar 3D geometries for faces of different identities, or obtain different shapes for the same identity with different poses. When such methods are applied practically, their 3D estimates are either changeable for different photos of the same subject or over-regularized and generic to distinguish face identities. In this paper, we propose a robust solution to solve this problem by carefully designing a novel Siamese Convolutional Neural Network (SCNN). Specifically, regarding the 3D Morphable face Model (3DMM) parameters of the same individual as the same class, we employ the contrastive loss to enlarge the inter-class distance and meanwhile reduce the intra-class distance for the output 3DMM parameters. We also propose an identity loss to preserve the identity information for the same individual in the feature space. Training with these two losses, our SCNN could learn representations that are more discriminative for face identity and generalizable for pose variants. Experiments on the challenging database 300W-LP and AFLW2000-3D have shown the effectiveness of our method by comparing with state-of-the-arts.
Multi-Prototype Networks for Unconstrained Set-based Face Recognition
Mar 23, 2019
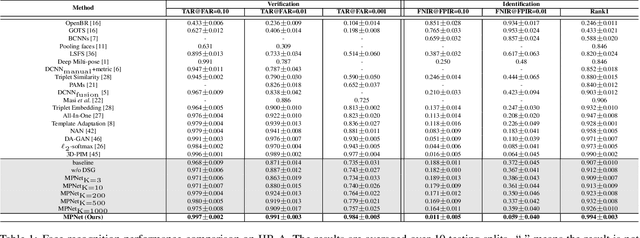
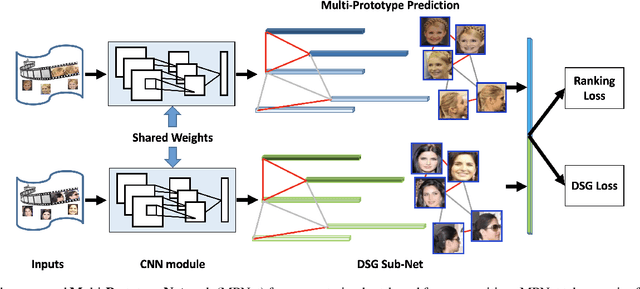
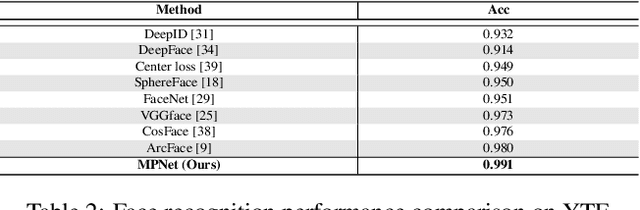
In this paper, we study the challenging unconstrained set-based face recognition problem where each subject face is instantiated by a set of media (images and videos) instead of a single image. Naively aggregating information from all the media within a set would suffer from the large intra-set variance caused by heterogeneous factors (e.g., varying media modalities, poses and illuminations) and fail to learn discriminative face representations. A novel Multi-Prototype Network (MPNet) model is thus proposed to learn multiple prototype face representations adaptively from the media sets. Each learned prototype is representative for the subject face under certain condition in terms of pose, illumination and media modality. Instead of handcrafting the set partition for prototype learning, MPNet introduces a Dense SubGraph (DSG) learning sub-net that implicitly untangles inconsistent media and learns a number of representative prototypes. Qualitative and quantitative experiments clearly demonstrate superiority of the proposed model over state-of-the-arts.
Joint 3D Face Reconstruction and Dense Face Alignment from A Single Image with 2D-Assisted Self-Supervised Learning
Mar 22, 2019
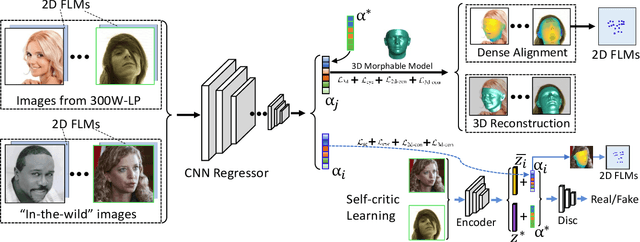

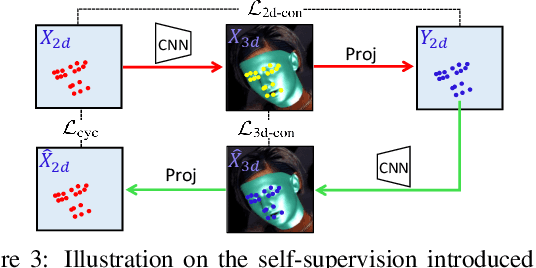
3D face reconstruction from a single 2D image is a challenging problem with broad applications. Recent methods typically aim to learn a CNN-based 3D face model that regresses coefficients of 3D Morphable Model (3DMM) from 2D images to render 3D face reconstruction or dense face alignment. However, the shortage of training data with 3D annotations considerably limits performance of those methods. To alleviate this issue, we propose a novel 2D-assisted self-supervised learning (2DASL) method that can effectively use "in-the-wild" 2D face images with noisy landmark information to substantially improve 3D face model learning. Specifically, taking the sparse 2D facial landmarks as additional information, 2DSAL introduces four novel self-supervision schemes that view the 2D landmark and 3D landmark prediction as a self-mapping process, including the 2D and 3D landmark self-prediction consistency, cycle-consistency over the 2D landmark prediction and self-critic over the predicted 3DMM coefficients based on landmark predictions. Using these four self-supervision schemes, the 2DASL method significantly relieves demands on the the conventional paired 2D-to-3D annotations and gives much higher-quality 3D face models without requiring any additional 3D annotations. Experiments on multiple challenging datasets show that our method outperforms state-of-the-arts for both 3D face reconstruction and dense face alignment by a large margin.