 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-Factory: Your Automated Factory for Issue Resolution Training Data and Evaluation Benchmarks
Jun 12, 2025Constructing large-scale datasets for the GitHub issue resolution task is crucial for both training and evaluating the software engineering capabilities of Large Language Models (LLMs). However, the traditional process for creating such benchmarks is notoriously challenging and labor-intensive, particularly in the stages of setting up evaluation environments, grading test outcomes, and validating task instances. In this paper, we propose SWE-Factory, an automated pipeline designed to address these challenges. To tackle these issues, our pipeline integrates three core automated components. First, we introduce SWE-Builder, a multi-agent system that automates evaluation environment construction, which employs four specialized agents that work in a collaborative, iterative loop and leverages an environment memory pool to enhance efficiency. Second, we introduce a standardized, exit-code-based grading method that eliminates the need for manually writing custom parsers. Finally, we automate the fail2pass validation process using these reliable exit code signals. Experiments on 671 issues across four programming languages show that our pipeline can effectively construct valid task instances; for example, with GPT-4.1-mini, our SWE-Builder constructs 269 valid instances at $0.045 per instance, while with Gemini-2.5-flash, it achieves comparable performance at the lowest cost of $0.024 per instance. We also demonstrate that our exit-code-based grading achieves 100% accuracy compared to manual inspection, and our automated fail2pass validation reaches a precision of 0.92 and a recall of 1.00. We hope our automated pipeline will accelerate the collection of large-scale, high-quality GitHub issue resolution datasets for both training and evaluation. Our code and datasets are released at https://github.com/DeepSoftwareAnalytics/swe-factory.
Process Reward Modeling with Entropy-Driven Uncertainty
Mar 28, 2025



This paper presents the Entropy-Driven Unified Process Reward Model (EDU-PRM), a novel framework that approximates state-of-the-art performance in process supervision while drastically reducing training costs. EDU-PRM introduces an entropy-guided dynamic step partitioning mechanism, using logit distribution entropy to pinpoint high-uncertainty regions during token generation dynamically. This self-assessment capability enables precise step-level feedback without manual fine-grained annotation, addressing a critical challenge in process supervision. Experiments on the Qwen2.5-72B model with only 7,500 EDU-PRM-generated training queries demonstrate accuracy closely approximating the full Qwen2.5-72B-PRM (71.1% vs. 71.6%), achieving a 98% reduction in query cost compared to prior methods. This work establishes EDU-PRM as an efficient approach for scalable process reward model training.
Cross-Domain Feature Augmentation for Domain Generalization
May 14, 2024



Domain generalization aims to develop models that are robust to distribution shifts. Existing methods focus on learning invariance across domains to enhance model robustness, and data augmentation has been widely used to learn invariant predictors, with most methods performing augmentation in the input space. However, augmentation in the input space has limited diversity whereas in the feature space is more versatile and has shown promising results. Nonetheless, feature semantics is seldom considered and existing feature augmentation methods suffer from a limited variety of augmented features. We decompose features into class-generic, class-specific, domain-generic, and domain-specific components. We propose a cross-domain feature augmentation method named XDomainMix that enables us to increase sample diversity while emphasizing the learning of invariant representations to achieve domain generalization. Experiments on widely used benchmark datasets demonstrate that our proposed method is able to achieve state-of-the-art performance. Quantitative analysis indicates that our feature augmentation approach facilitates the learning of effective models that are invariant across different domains.
Towards Robust Out-of-Distribution Generalization Bounds via Sharpness
Mar 11, 2024Generalizing to out-of-distribution (OOD) data or unseen domain, termed OOD generalization, still lacks appropriate theoretical guarantees. Canonical OOD bounds focus on different distance measurements between source and target domains but fail to consider the optimization property of the learned model. As empirically shown in recent work, the sharpness of learned minima influences OOD generalization. To bridge this gap between optimization and OOD generalization, we study the effect of sharpness on how a model tolerates data change in domain shift which is usually captured by "robustness" in generalization. In this paper, we give a rigorous connection between sharpness and robustness, which gives better OOD guarantees for robust algorithms. It also provides a theoretical backing for "flat minima leads to better OOD generalization". Overall, we propose a sharpness-based OOD generalization bound by taking robustness into consideration, resulting in a tighter bound than non-robust guarantees. Our findings are supported by the experiments on a ridge regression model, as well as the experiments on deep learning classification tasks.
Image-to-Video Generation via 3D Facial Dynamics
May 31, 2021
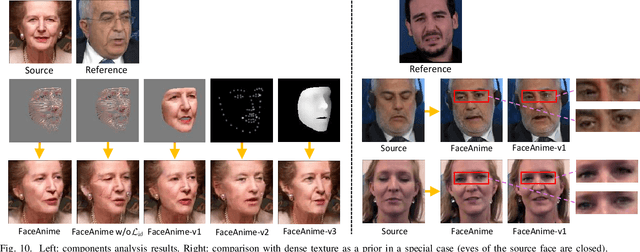
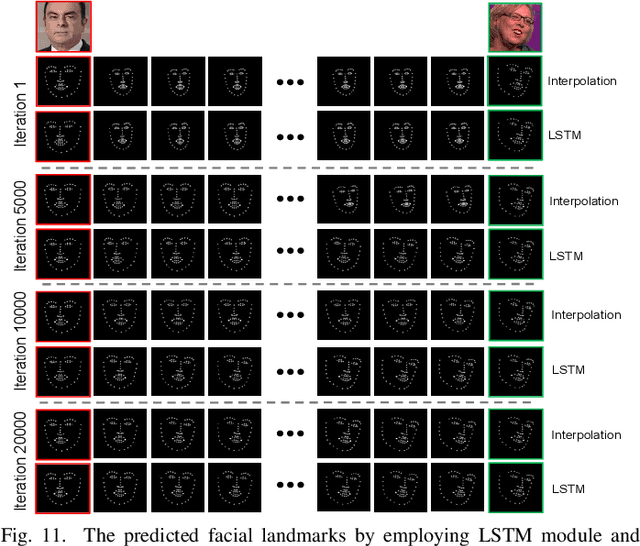
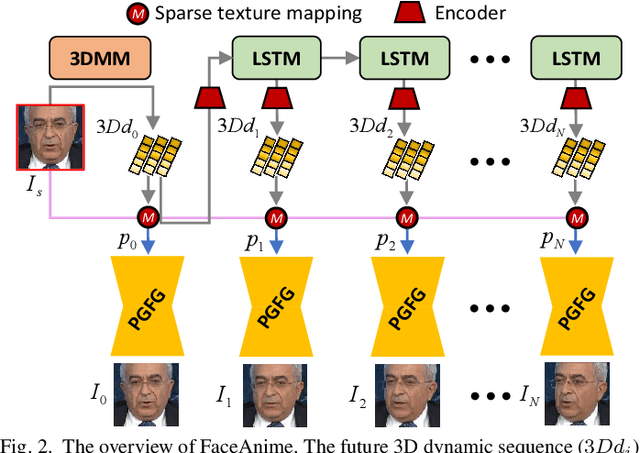
We present a versatile model, FaceAnime, for various video generation tasks from still images. Video generation from a single face image is an interesting problem and usually tackled by utilizing Generative Adversarial Networks (GANs) to integrate information from the input face image and a sequence of sparse facial landmarks. However, the generated face images usually suffer from quality loss, image distortion, identity change, and expression mismatching due to the weak representation capacity of the facial landmarks. In this paper, we propose to "imagine" a face video from a single face image according to the reconstructed 3D face dynamics, aiming to generate a realistic and identity-preserving face video, with precisely predicted pose and facial expression. The 3D dynamics reveal changes of the facial expression and motion, and can serve as a strong prior knowledge for guiding highly realistic face video generation. In particular, we explore face video prediction and exploit a well-designed 3D dynamic prediction network to predict a 3D dynamic sequence for a single face image. The 3D dynamics are then further rendered by the sparse texture mapping algorithm to recover structural details and sparse textures for generating face frames. Our model is versatile for various AR/VR and entertainment applications, such as face video retargeting and face video prediction. Superior experimental results have well demonstrated its effectiveness in generating high-fidelity, identity-preserving, and visually pleasant face video clips from a single source face image.
PANet: Few-Shot Image Semantic Segmentation with Prototype Alignment
Aug 18, 2019



Despite the great progress made by deep CNNs in image semantic segmentation, they typically require a large number of densely-annotated images for training and are difficult to generalize to unseen object categories. Few-shot segmentation has thus been developed to learn to perform segmentation from only a few annotated examples. In this paper, we tackle the challenging few-shot segmentation problem from a metric learning perspective and present PANet, a novel prototype alignment network to better utilize the information of the support set. Our PANet learns class-specific prototype representations from a few support images within an embedding space and then performs segmentation over the query images through matching each pixel to the learned prototypes. With non-parametric metric learning, PANet offers high-quality prototypes that are representative for each semantic class and meanwhile discriminative for different classes. Moreover, PANet introduces a prototype alignment regularization between support and query. With this, PANet fully exploits knowledge from the support and provides better generalization on few-shot segmentation. Significantly, our model achieves the mIoU score of 48.1% and 55.7% on PASCAL-5i for 1-shot and 5-shot settings respectively, surpassing the state-of-the-art method by 1.8% and 8.6%.
Panoptic Edge Detection
Jun 03, 2019



Pursuing more complete and coherent scene understanding towards realistic vision applications drives edge detection from category-agnostic to category-aware semantic level. However, finer delineation of instance-level boundaries still remains unexcavated. In this work, we address a new finer-grained task, termed panoptic edge detection (PED), which aims at predicting semantic-level boundaries for stuff categories and instance-level boundaries for instance categories, in order to provide more comprehensive and unified scene understanding from the perspective of edges.We then propose a versatile framework, Panoptic Edge Network (PEN), which aggregates different tasks of object detection, semantic and instance edge detection into a single holistic network with multiple branches. Based on the same feature representation, the semantic edge branch produces semantic-level boundaries for all categories and the object detection branch generates instance proposals. Conditioned on the prior information from these two branches, the instance edge branch aims at instantiating edge predictions for instance categories. Besides, we also devise a Panoptic Dual F-measure (F2) metric for the new PED task to uniformly measure edge prediction quality for both stuff and instances. By joint end-to-end training, the proposed PEN framework outperforms all competitive baselines on Cityscapes and ADE20K datasets.
Hierarchical Meta Learning
Apr 19, 2019

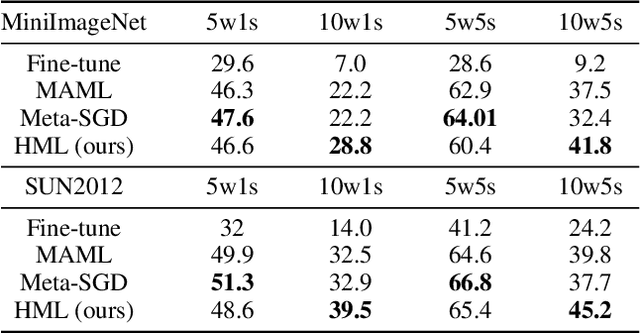
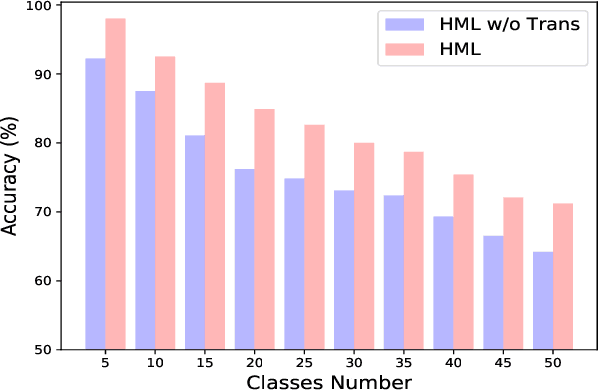
Meta learning is a promising solution to few-shot learning problems. However, existing meta learning methods are restricted to the scenarios where training and application tasks share the same out-put structure. To obtain a meta model applicable to the tasks with new structures, it is required to collect new training data and repeat the time-consuming meta training procedure. This makes them inefficient or even inapplicable in learning to solve heterogeneous few-shot learning tasks. We thus develop a novel and principled HierarchicalMeta Learning (HML) method. Different from existing methods that only focus on optimizing the adaptability of a meta model to similar tasks, HML also explicitly optimizes its generalizability across heterogeneous tasks. To this end, HML first factorizes a set of similar training tasks into heterogeneous ones and trains the meta model over them at two levels to maximize adaptation and generalization performance respectively. The resultant model can then directly generalize to new tasks. Extensive experiments on few-shot classification and regression problems clearly demonstrate the superiority of HML over fine-tuning and state-of-the-art meta learning approaches in terms of generalization across heterogeneous tasks.
Better Guider Predicts Future Better: Difference Guided Generative Adversarial Networks
Jan 07, 2019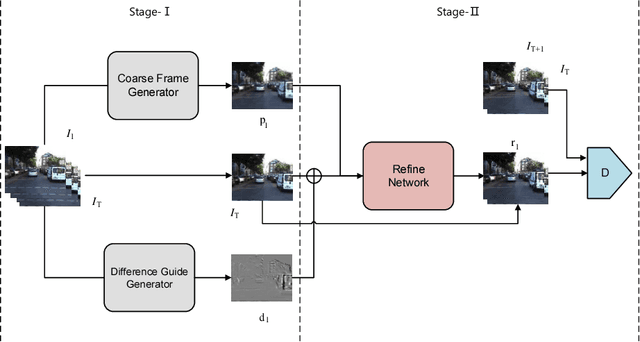
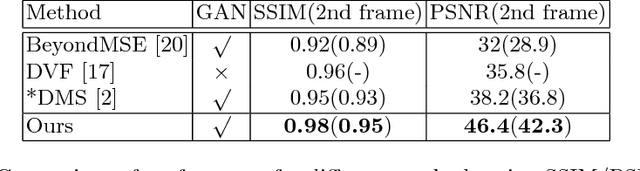
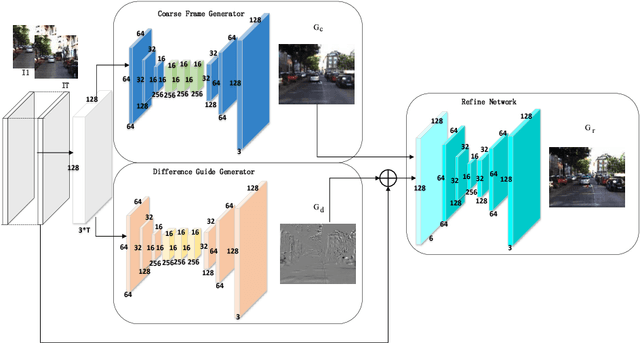
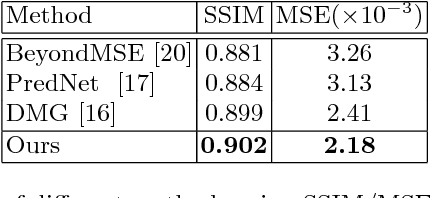
Predicting the future is a fantasy but practicality work. It is the key component to intelligent agents, such as self-driving vehicles, medical monitoring devices and robotics. In this work, we consider generating unseen future frames from previous obeservations, which is notoriously hard due to the uncertainty in frame dynamics. While recent works based on generative adversarial networks (GANs) made remarkable progress, there is still an obstacle for making accurate and realistic predictions. In this paper, we propose a novel GAN based on inter-frame difference to circumvent the difficulties. More specifically, our model is a multi-stage generative network, which is named the Difference Guided Generative Adversarial Netwok (DGGAN). The DGGAN learns to explicitly enforce future-frame predictions that is guided by synthetic inter-frame difference. Given a sequence of frames, DGGAN first uses dual paths to generate meta information. One path, called Coarse Frame Generator, predicts the coarse details about future frames, and the other path, called Difference Guide Generator, generates the difference image which include complementary fine details. Then our coarse details will then be refined via guidance of difference image under the support of GANs. With this model and novel architecture, we achieve state-of-the-art performance for future video prediction on UCF-101, KITTI.
Spatial-Temporal Synergic Residual Learning for Video Person Re-Identification
Jul 16, 2018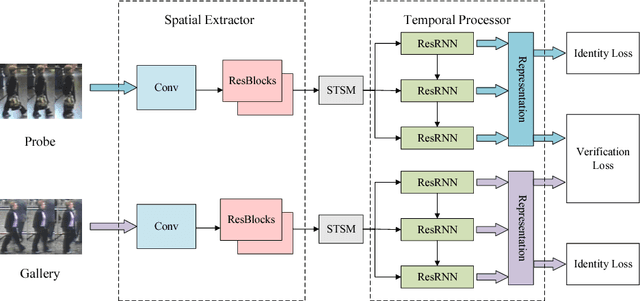



We tackle the problem of person re-identification in video setting in this paper, which has been viewed as a crucial task in many applications. Meanwhile, it is very challenging since the task requires learning effective representations from video sequences with heterogeneous spatial-temporal information. We present a novel method - Spatial-Temporal Synergic Residual Network (STSRN) for this problem. STSRN contains a spatial residual extractor, a temporal residual processor and a spatial-temporal smooth module. The smoother can alleviate sample noises along the spatial-temporal dimensions thus enable STSRN extracts more robust spatial-temporal features of consecutive frames. Extensive experiments are conducted on several challenging datasets including iLIDS-VID, PRID2011 and MARS. The results demonstrate that the proposed method achieves consistently superior performance over most of state-of-the-art methods.