 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Guider Predicts Future Better: Difference Guided Generative Adversarial Networks
Paper and Code
Jan 07, 2019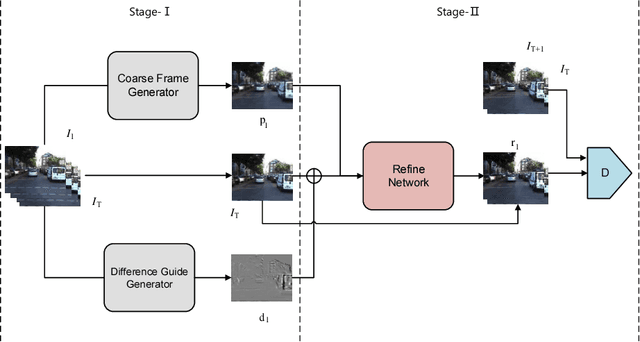
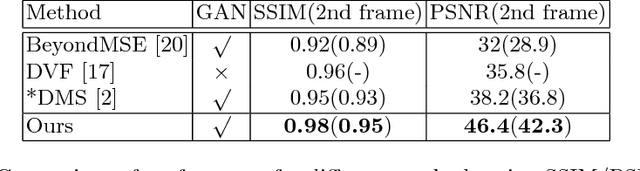
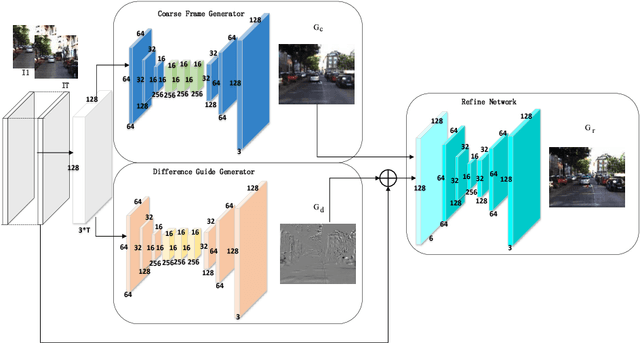
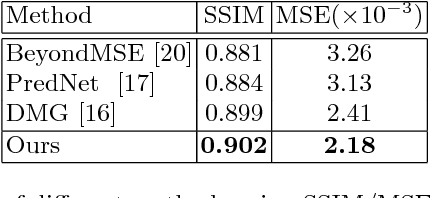
Predicting the future is a fantasy but practicality work. It is the key component to intelligent agents, such as self-driving vehicles, medical monitoring devices and robotics. In this work, we consider generating unseen future frames from previous obeservations, which is notoriously hard due to the uncertainty in frame dynamics. While recent works based on generative adversarial networks (GANs) made remarkable progress, there is still an obstacle for making accurate and realistic predictions. In this paper, we propose a novel GAN based on inter-frame difference to circumvent the difficulties. More specifically, our model is a multi-stage generative network, which is named the Difference Guided Generative Adversarial Netwok (DGGAN). The DGGAN learns to explicitly enforce future-frame predictions that is guided by synthetic inter-frame difference. Given a sequence of frames, DGGAN first uses dual paths to generate meta information. One path, called Coarse Frame Generator, predicts the coarse details about future frames, and the other path, called Difference Guide Generator, generates the difference image which include complementary fine details. Then our coarse details will then be refined via guidance of difference image under the support of GANs. With this model and novel architecture, we achieve state-of-the-art performance for future video prediction on UCF-101, KITTI.