 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEAGAN: Efficient Two-stage Evolutionary Architecture Search for GANs
Nov 30, 2021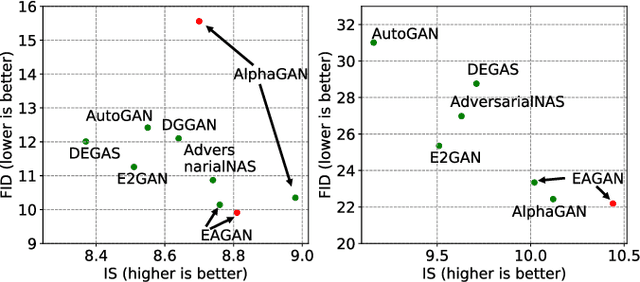
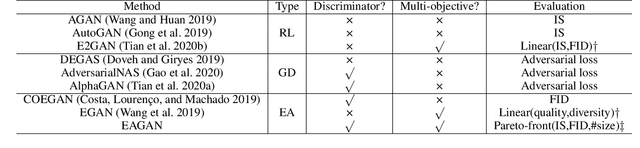
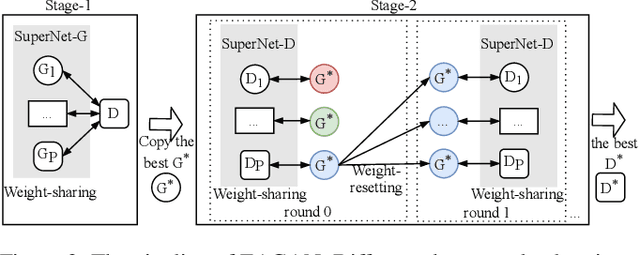
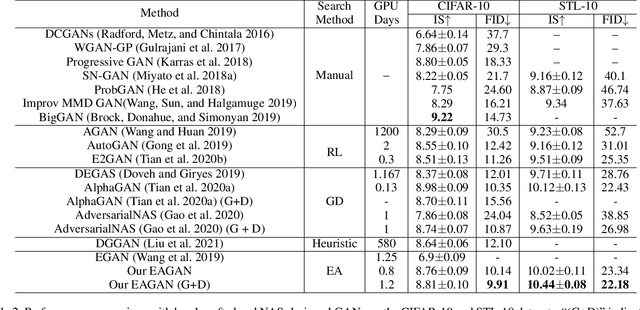
Generative Adversarial Networks (GANs) have been proven hugely successful in image generation tasks, but GAN training has the problem of instability. Many works have improved the stability of GAN training by manually modifying the GAN architecture, which requires human expertise and extensive trial-and-error. Thus, neural architecture search (NAS), which aims to automate the model design, has been applied to search GANs on the task of unconditional image generation. The early NAS-GAN works only search generators for reducing the difficulty. Some recent works have attempted to search both generator (G) and discriminator (D) to improve GAN performance, but they still suffer from the instability of GAN training during the search. To alleviate the instability issue, we propose an efficient two-stage evolutionary algorithm (EA) based NAS framework to discover GANs, dubbed \textbf{EAGAN}. Specifically, we decouple the search of G and D into two stages and propose the weight-resetting strategy to improve the stability of GAN training. Besides, we perform evolution operations to produce the Pareto-front architectures based on multiple objectives, resulting in a superior combination of G and D. By leveraging the weight-sharing strategy and low-fidelity evaluation, EAGAN can significantly shorten the search time. EAGAN achieves highly competitive results on the CIFAR-10 (IS=8.81$\pm$0.10, FID=9.91) and surpasses previous NAS-searched GANs on the STL-10 dataset (IS=10.44$\pm$0.087, FID=22.18).
Efficient Multi-objective Evolutionary 3D Neural Architecture Search for COVID-19 Detection with Chest CT Scans
Jan 26, 2021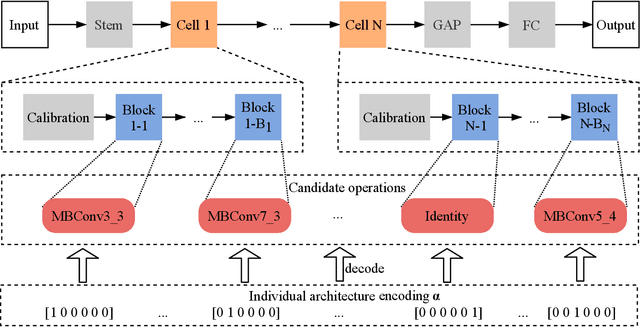
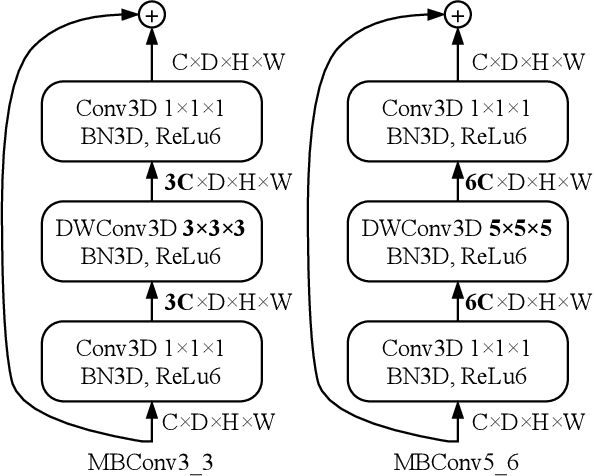

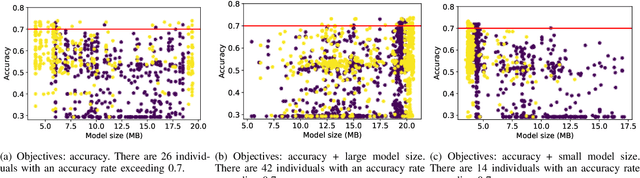
COVID-19 pandemic has spread globally for months. Due to its long incubation period and high testing cost, there is no clue showing its spread speed is slowing down, and hence a faster testing method is in dire need. This paper proposes an efficient Evolutionary Multi-objective neural ARchitecture Search (EMARS) framework, which can automatically search for 3D neural architectures based on a well-designed search space for COVID-19 chest CT scan classification. Within the framework, we use weight sharing strategy to significantly improve the search efficiency and finish the search process in 8 hours. We also propose a new objective, namely potential, which is of benefit to improve the search process's robustness. With the objectives of accuracy, potential, and model size, we find a lightweight model (3.39 MB), which outperforms three baseline human-designed models, i.e., ResNet3D101 (325.21 MB), DenseNet3D121 (43.06 MB), and MC3\_18 (43.84 MB). Besides, our well-designed search space enables the class activation mapping algorithm to be easily embedded into all searched models, which can provide the interpretability for medical diagnosis by visualizing the judgment based on the models to locate the lesion areas.
Better Guider Predicts Future Better: Difference Guided Generative Adversarial Networks
Jan 07, 2019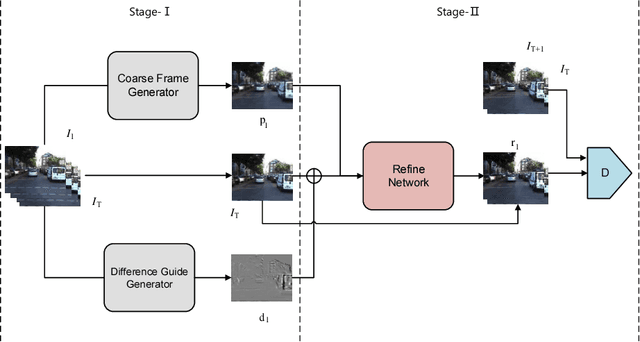
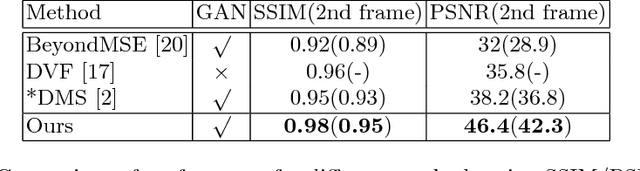
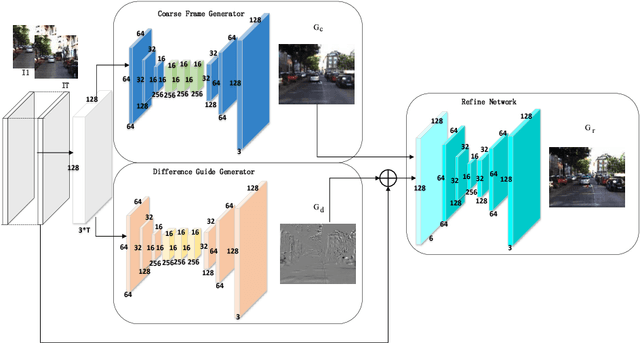
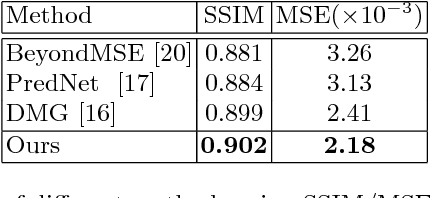
Predicting the future is a fantasy but practicality work. It is the key component to intelligent agents, such as self-driving vehicles, medical monitoring devices and robotics. In this work, we consider generating unseen future frames from previous obeservations, which is notoriously hard due to the uncertainty in frame dynamics. While recent works based on generative adversarial networks (GANs) made remarkable progress, there is still an obstacle for making accurate and realistic predictions. In this paper, we propose a novel GAN based on inter-frame difference to circumvent the difficulties. More specifically, our model is a multi-stage generative network, which is named the Difference Guided Generative Adversarial Netwok (DGGAN). The DGGAN learns to explicitly enforce future-frame predictions that is guided by synthetic inter-frame difference. Given a sequence of frames, DGGAN first uses dual paths to generate meta information. One path, called Coarse Frame Generator, predicts the coarse details about future frames, and the other path, called Difference Guide Generator, generates the difference image which include complementary fine details. Then our coarse details will then be refined via guidance of difference image under the support of GANs. With this model and novel architecture, we achieve state-of-the-art performance for future video prediction on UCF-101, KITTI.