 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSP-ReID: Hairstyle-Robust Cloth-Changing Person Re-Identification
Mar 02, 2026Cloth-Changing Person Re-Identification (CC-ReID) aims to match the same individual across cameras under varying clothing conditions. Existing approaches often remove apparel and focus on the head region to reduce clothing bias. However, treating the head holistically without distinguishing between face and hair leads to over-reliance on volatile hairstyle cues, causing performance degradation under hairstyle changes. To address this issue, we propose the Mitigating Hairstyle Distraction and Structural Preservation (MSP) framework. Specifically, MSP introduces Hairstyle-Oriented Augmentation (HSOA), which generates intra-identity hairstyle diversity to reduce hairstyle dependence and enhance attention to stable facial and body cues. To prevent the loss of structural information, we design Cloth-Preserved Random Erasing (CPRE), which performs ratio-controlled erasing within clothing regions to suppress texture bias while retaining body shape and context. Furthermore, we employ Region-based Parsing Attention (RPA) to incorporate parsing-guided priors that highlight face and limb regions while suppressing hair features. Extensive experiments on multiple CC-ReID benchmarks demonstrate that MSP achieves state-of-the-art performance, providing a robust and practical solution for long-term person re-identification.
Self-Supervised Modality-Aware Multiple Granularity Pre-Training for RGB-Infrared Person Re-Identification
Dec 12, 2021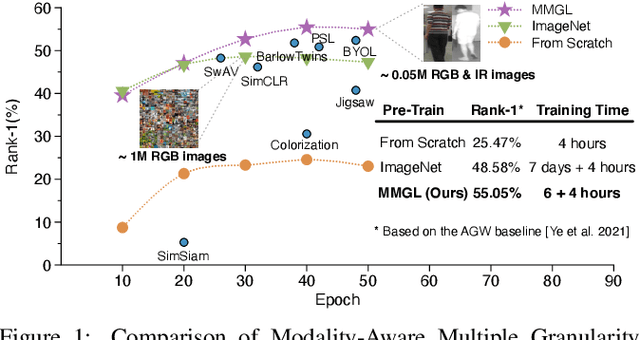
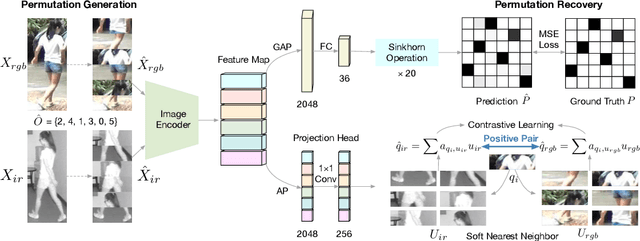
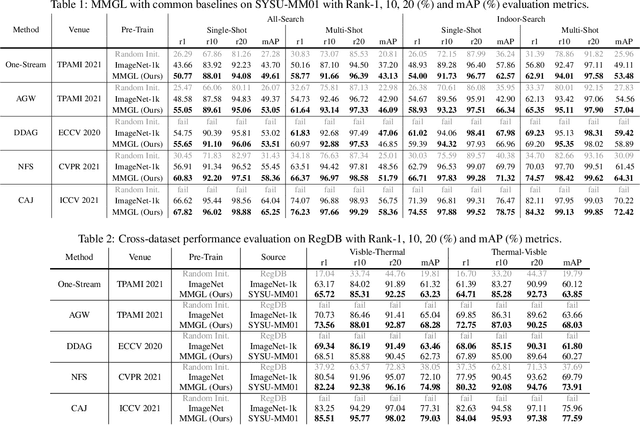
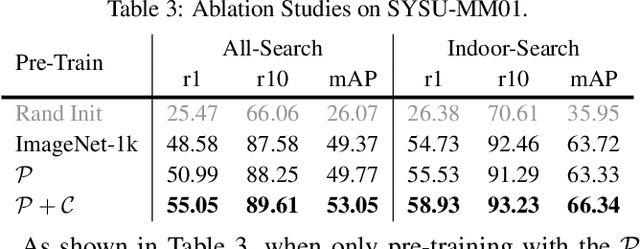
While RGB-Infrared cross-modality person re-identification (RGB-IR ReID) has enabled great progress in 24-hour intelligent surveillance, state-of-the-arts still heavily rely on fine-tuning ImageNet pre-trained networks. Due to the single-modality nature, such large-scale pre-training may yield RGB-biased representations that hinder the performance of cross-modality image retrieval. This paper presents a self-supervised pre-training alternative, named Modality-Aware Multiple Granularity Learning (MMGL), which directly trains models from scratch on multi-modality ReID datasets, but achieving competitive results without external data and sophisticated tuning tricks. Specifically, MMGL globally maps shuffled RGB-IR images into a shared latent permutation space and further improves local discriminability by maximizing agreement between cycle-consistent RGB-IR image patches. Experiments demonstrate that MMGL learns better representations (+6.47% Rank-1) with faster training speed (converge in few hours) and solider data efficiency (<5% data size) than ImageNet pre-training. The results also suggest it generalizes well to various existing models, losses and has promising transferability across datasets. The code will be released.
G$^2$DA: Geometry-Guided Dual-Alignment Learning for RGB-Infrared Person Re-Identification
Jun 15, 2021


RGB-Infrared (IR) person re-identification aims to retrieve person-of-interest between heterogeneous modalities, suffering from large modality discrepancy caused by different sensory devices. Existing methods mainly focus on global-level modality alignment, whereas neglect sample-level modality divergence to some extent, leading to performance degradation. This paper attempts to find RGB-IR ReID solutions from tackling sample-level modality difference, and presents a Geometry-Guided Dual-Alignment learning framework (G$^2$DA), which jointly enhances modality-invariance and reinforces discriminability with human topological structure in features to boost the overall matching performance. Specifically, G$^2$DA extracts accurate body part features with a pose estimator, serving as a semantic bridge complementing the missing local details in global descriptor. Based on extracted local and global features, a novel distribution constraint derived from optimal transport is introduced to mitigate the modality gap in a fine-grained sample-level manner. Beyond pair-wise relations across two modalities, it additionally measures the structural similarity of different parts, thus both multi-level features and their relations are kept consistent in the common feature space. Considering the inherent human-topology information, we further advance a geometry-guided graph learning module to refine each part features, where relevant regions can be emphasized while meaningless ones are suppressed, effectively facilitating robust feature learning. Extensive experiments on two standard benchmark datasets validate the superiority of our proposed method, yielding competitive performance over the state-of-the-art approaches.
Neural Feature Search for RGB-Infrared Person Re-Identification
Apr 06, 2021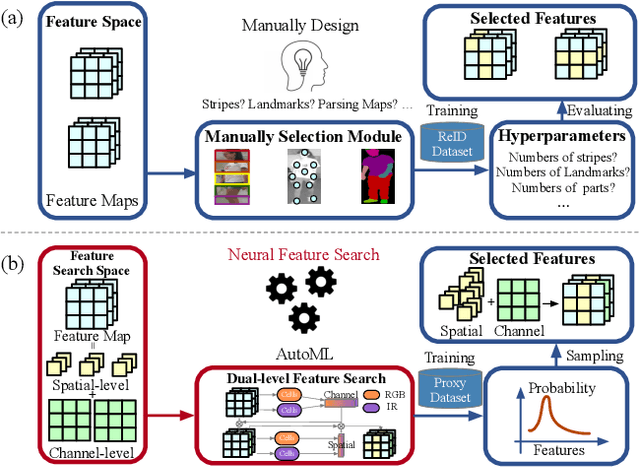



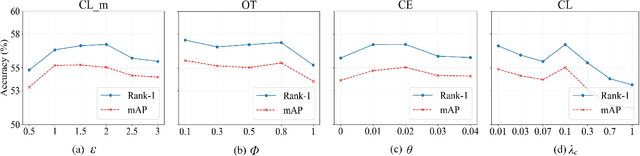
RGB-Infrared person re-identification (RGB-IR ReID) is a challenging cross-modality retrieval problem, which aims at matching the person-of-interest over visible and infrared camera views. Most existing works achieve performance gains through manually-designed feature selection modules, which often require significant domain knowledge and rich experience. In this paper, we study a general paradigm, termed Neural Feature Search (NFS), to automate the process of feature selection. Specifically, NFS combines a dual-level feature search space and a differentiable search strategy to jointly select identity-related cues in coarse-grained channels and fine-grained spatial pixels. This combination allows NFS to adaptively filter background noises and concentrate on informative parts of human bodies in a data-driven manner. Moreover, a cross-modality contrastive optimization scheme further guides NFS to search features that can minimize modality discrepancy whilst maximizing inter-class distance. Extensive experiments on mainstream benchmarks demonstrate that our method outperforms state-of-the-arts, especially achieving better performance on the RegDB dataset with significant improvement of 11.20% and 8.64% in Rank-1 and mAP, respectively.
Potential Advantages of Peak Picking Multi-Voltage Threshold Digitizer in Energy Determination in Radiation Measurement
Mar 08, 2021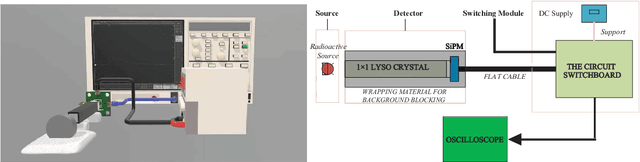
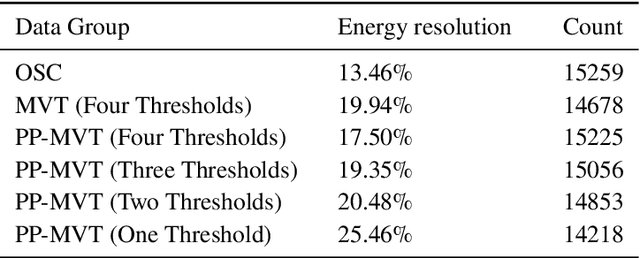
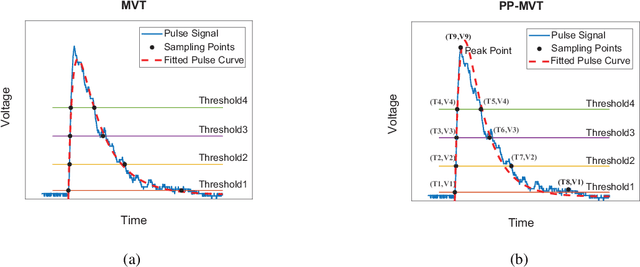
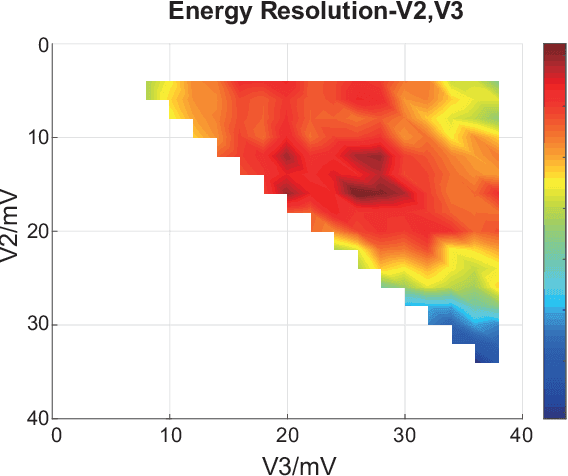
The Multi-voltage Threshold (MVT) method, which samples the signal by certain reference voltages, has been well developed as being adopted in pre-clinical and clinical digital positron emission tomography(PET) system. To improve its energy measurement performance, we propose a Peak Picking MVT(PP-MVT) Digitizer in this paper. Firstly, a sampled Peak Point(the highest point in pulse signal), which carries the values of amplitude feature voltage and amplitude arriving time, is added to traditional MVT with a simple peak sampling circuit. Secondly, an amplitude deviation statistical analysis, which compares the energy deviation of various reconstruction models, is used to select adaptive reconstruction models for signal pulses with different amplitudes. After processing 30,000 randomly-chosen pulses sampled by the oscilloscope with a 22Na point source, our method achieves an energy resolution of 17.50% within a 450-650 KeV energy window, which is 2.44% better than the result of traditional MVT with same thresholds; and we get a count number at 15225 in the same energy window while the result of MVT is at 14678. When the PP-MVT involves less thresholds than traditional MVT, the advantages of better energy resolution and larger count number can still be maintained, which shows the robustness and the flexibility of PP-MVT Digitizer. This improved method indicates that adding feature peak information could improve the performance on signal sampling and reconstruction, which canbe proved by the better performance in energy determination in radiation measurement.
Better Guider Predicts Future Better: Difference Guided Generative Adversarial Networks
Jan 07, 2019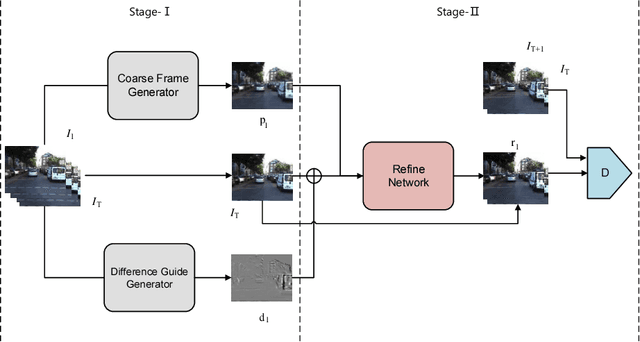
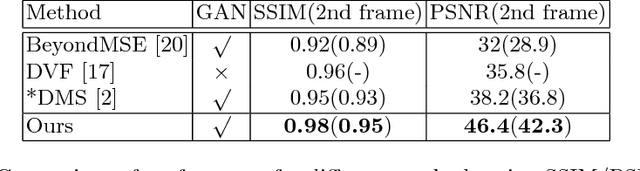
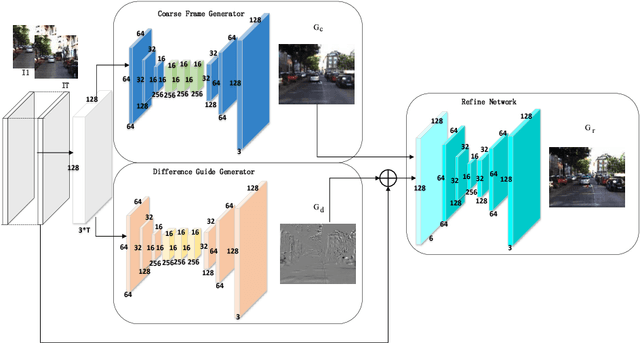
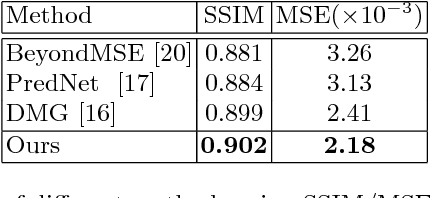
Predicting the future is a fantasy but practicality work. It is the key component to intelligent agents, such as self-driving vehicles, medical monitoring devices and robotics. In this work, we consider generating unseen future frames from previous obeservations, which is notoriously hard due to the uncertainty in frame dynamics. While recent works based on generative adversarial networks (GANs) made remarkable progress, there is still an obstacle for making accurate and realistic predictions. In this paper, we propose a novel GAN based on inter-frame difference to circumvent the difficulties. More specifically, our model is a multi-stage generative network, which is named the Difference Guided Generative Adversarial Netwok (DGGAN). The DGGAN learns to explicitly enforce future-frame predictions that is guided by synthetic inter-frame difference. Given a sequence of frames, DGGAN first uses dual paths to generate meta information. One path, called Coarse Frame Generator, predicts the coarse details about future frames, and the other path, called Difference Guide Generator, generates the difference image which include complementary fine details. Then our coarse details will then be refined via guidance of difference image under the support of GANs. With this model and novel architecture, we achieve state-of-the-art performance for future video prediction on UCF-101, KITTI.