 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Modality-Aware Multiple Granularity Pre-Training for RGB-Infrared Person Re-Identification
Paper and Code
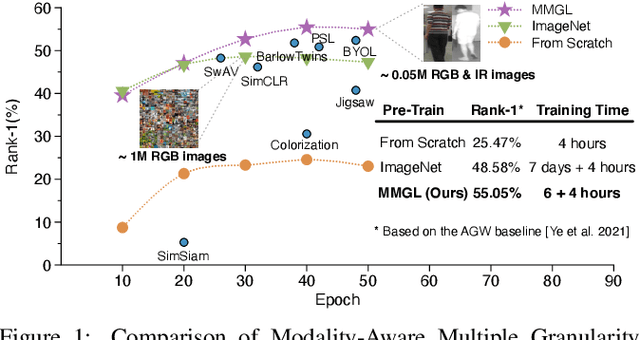
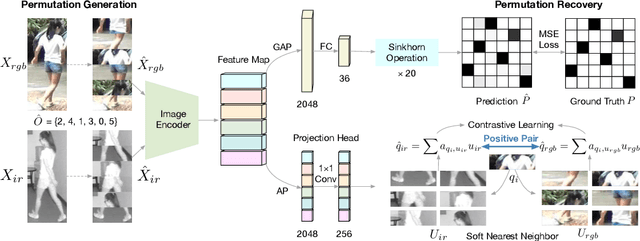
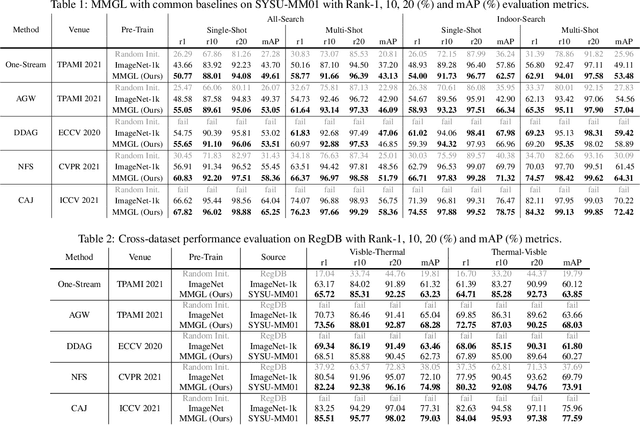
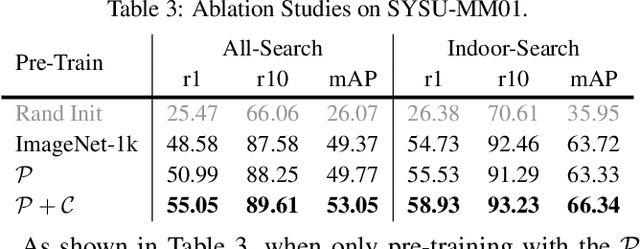
While RGB-Infrared cross-modality person re-identification (RGB-IR ReID) has enabled great progress in 24-hour intelligent surveillance, state-of-the-arts still heavily rely on fine-tuning ImageNet pre-trained networks. Due to the single-modality nature, such large-scale pre-training may yield RGB-biased representations that hinder the performance of cross-modality image retrieval. This paper presents a self-supervised pre-training alternative, named Modality-Aware Multiple Granularity Learning (MMGL), which directly trains models from scratch on multi-modality ReID datasets, but achieving competitive results without external data and sophisticated tuning tricks. Specifically, MMGL globally maps shuffled RGB-IR images into a shared latent permutation space and further improves local discriminability by maximizing agreement between cycle-consistent RGB-IR image patches. Experiments demonstrate that MMGL learns better representations (+6.47% Rank-1) with faster training speed (converge in few hours) and solider data efficiency (<5% data size) than ImageNet pre-training. The results also suggest it generalizes well to various existing models, losses and has promising transferability across datasets. The code will be released.