 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Part-Informed Visual-Language Learning for Person Re-Identification
Aug 04, 2023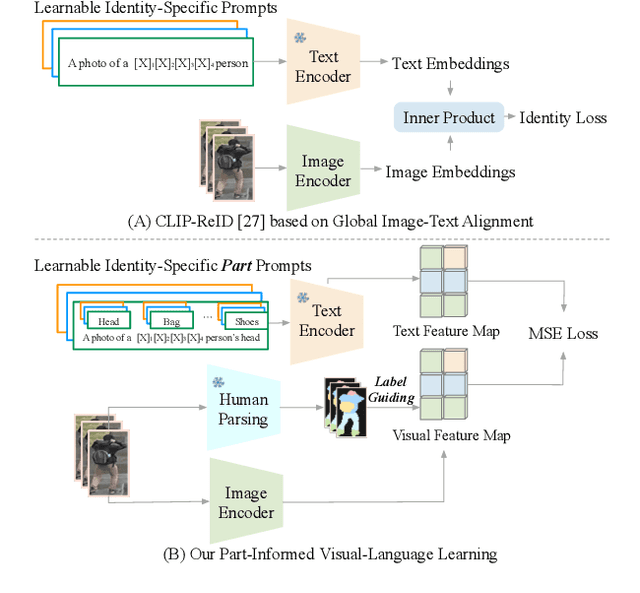
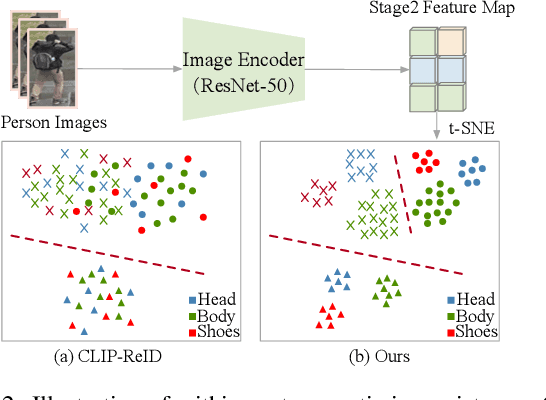
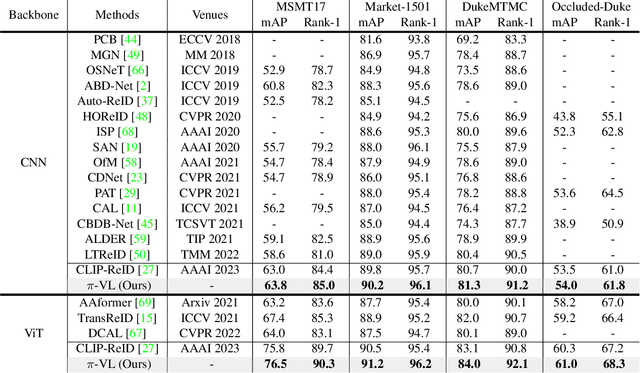
Recently, visual-language learning has shown great potential in enhancing visual-based person re-identification (ReID). Existing visual-language learning-based ReID methods often focus on whole-body scale image-text feature alignment, while neglecting supervisions on fine-grained part features. This choice simplifies the learning process but cannot guarantee within-part feature semantic consistency thus hindering the final performance. Therefore, we propose to enhance fine-grained visual features with part-informed language supervision for ReID tasks. The proposed method, named Part-Informed Visual-language Learning ($\pi$-VL), suggests that (i) a human parsing-guided prompt tuning strategy and (ii) a hierarchical fusion-based visual-language alignment paradigm play essential roles in ensuring within-part feature semantic consistency. Specifically, we combine both identity labels and parsing maps to constitute pixel-level text prompts and fuse multi-stage visual features with a light-weight auxiliary head to perform fine-grained image-text alignment. As a plug-and-play and inference-free solution, our $\pi$-VL achieves substantial improvements over previous state-of-the-arts on four common-used ReID benchmarks, especially reporting 90.3% Rank-1 and 76.5% mAP for the most challenging MSMT17 database without bells and whistles.
Self-Supervised Modality-Aware Multiple Granularity Pre-Training for RGB-Infrared Person Re-Identification
Dec 12, 2021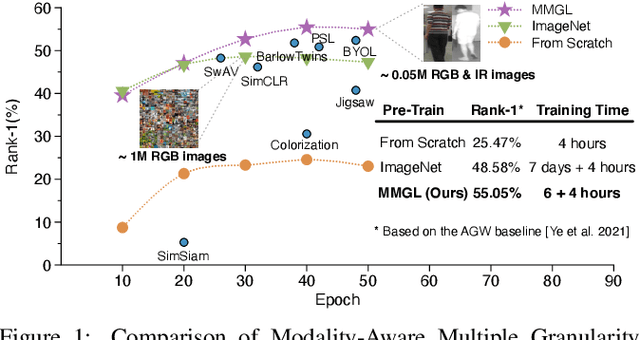
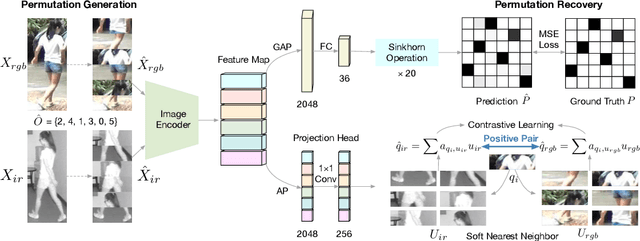
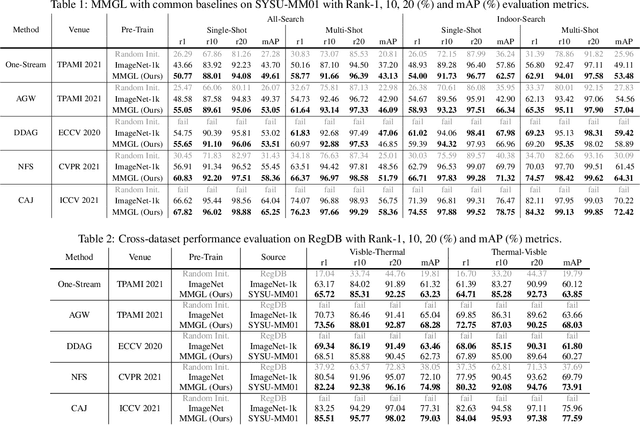
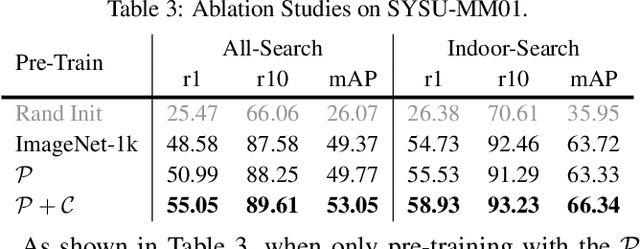
While RGB-Infrared cross-modality person re-identification (RGB-IR ReID) has enabled great progress in 24-hour intelligent surveillance, state-of-the-arts still heavily rely on fine-tuning ImageNet pre-trained networks. Due to the single-modality nature, such large-scale pre-training may yield RGB-biased representations that hinder the performance of cross-modality image retrieval. This paper presents a self-supervised pre-training alternative, named Modality-Aware Multiple Granularity Learning (MMGL), which directly trains models from scratch on multi-modality ReID datasets, but achieving competitive results without external data and sophisticated tuning tricks. Specifically, MMGL globally maps shuffled RGB-IR images into a shared latent permutation space and further improves local discriminability by maximizing agreement between cycle-consistent RGB-IR image patches. Experiments demonstrate that MMGL learns better representations (+6.47% Rank-1) with faster training speed (converge in few hours) and solider data efficiency (<5% data size) than ImageNet pre-training. The results also suggest it generalizes well to various existing models, losses and has promising transferability across datasets. The code will be released.
G$^2$DA: Geometry-Guided Dual-Alignment Learning for RGB-Infrared Person Re-Identification
Jun 15, 2021


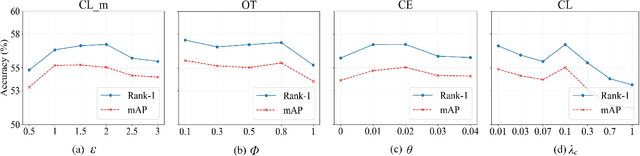
RGB-Infrared (IR) person re-identification aims to retrieve person-of-interest between heterogeneous modalities, suffering from large modality discrepancy caused by different sensory devices. Existing methods mainly focus on global-level modality alignment, whereas neglect sample-level modality divergence to some extent, leading to performance degradation. This paper attempts to find RGB-IR ReID solutions from tackling sample-level modality difference, and presents a Geometry-Guided Dual-Alignment learning framework (G$^2$DA), which jointly enhances modality-invariance and reinforces discriminability with human topological structure in features to boost the overall matching performance. Specifically, G$^2$DA extracts accurate body part features with a pose estimator, serving as a semantic bridge complementing the missing local details in global descriptor. Based on extracted local and global features, a novel distribution constraint derived from optimal transport is introduced to mitigate the modality gap in a fine-grained sample-level manner. Beyond pair-wise relations across two modalities, it additionally measures the structural similarity of different parts, thus both multi-level features and their relations are kept consistent in the common feature space. Considering the inherent human-topology information, we further advance a geometry-guided graph learning module to refine each part features, where relevant regions can be emphasized while meaningless ones are suppressed, effectively facilitating robust feature learning. Extensive experiments on two standard benchmark datasets validate the superiority of our proposed method, yielding competitive performance over the state-of-the-art approaches.
Neural Feature Search for RGB-Infrared Person Re-Identification
Apr 06, 2021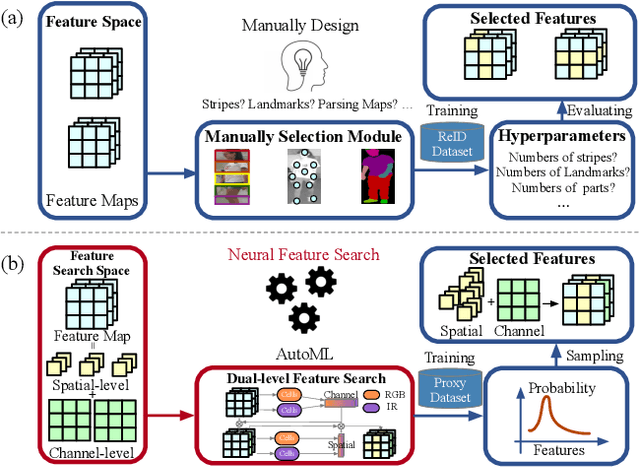



RGB-Infrared person re-identification (RGB-IR ReID) is a challenging cross-modality retrieval problem, which aims at matching the person-of-interest over visible and infrared camera views. Most existing works achieve performance gains through manually-designed feature selection modules, which often require significant domain knowledge and rich experience. In this paper, we study a general paradigm, termed Neural Feature Search (NFS), to automate the process of feature selection. Specifically, NFS combines a dual-level feature search space and a differentiable search strategy to jointly select identity-related cues in coarse-grained channels and fine-grained spatial pixels. This combination allows NFS to adaptively filter background noises and concentrate on informative parts of human bodies in a data-driven manner. Moreover, a cross-modality contrastive optimization scheme further guides NFS to search features that can minimize modality discrepancy whilst maximizing inter-class distance. Extensive experiments on mainstream benchmarks demonstrate that our method outperforms state-of-the-arts, especially achieving better performance on the RegDB dataset with significant improvement of 11.20% and 8.64% in Rank-1 and mAP, respectively.