 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATP-Bench: Towards Agentic Tool Planning for MLLM Interleaved Generation
Mar 31, 2026Interleaved text-and-image generation represents a significant frontier for Multimodal Large Language Models (MLLMs), offering a more intuitive way to convey complex information. Current paradigms rely on either image generation or retrieval augmentation, yet they typically treat the two as mutually exclusive paths, failing to unify factuality with creativity. We argue that the next milestone in this field is Agentic Tool Planning, where the model serves as a central controller that autonomously determines when, where, and which tools to invoke to produce interleaved responses for visual-critical queries. To systematically evaluate this paradigm, we introduce ATP-Bench, a novel benchmark comprising 7,702 QA pairs (including 1,592 VQA pairs) across eight categories and 25 visual-critical intents, featuring human-verified queries and ground truths. Furthermore, to evaluate agentic planning independent of end-to-end execution and changing tool backends, we propose a Multi-Agent MLLM-as-a-Judge (MAM) system. MAM evaluates tool-call precision, identifies missed opportunities for tool use, and assesses overall response quality without requiring ground-truth references. Our extensive experiments on 10 state-of-the-art MLLMs reveal that models struggle with coherent interleaved planning and exhibit significant variations in tool-use behavior, highlighting substantial room for improvement and providing actionable guidance for advancing interleaved generation. Dataset and code are available at https://github.com/Qwen-Applications/ATP-Bench.
Grounding the Score: Explicit Visual Premise Verification for Reliable Vision-Language Process Reward Models
Mar 17, 2026Vision-language process reward models (VL-PRMs) are increasingly used to score intermediate reasoning steps and rerank candidates under test-time scaling. However, they often function as black-box judges: a low step score may reflect a genuine reasoning mistake or simply the verifier's misperception of the image. This entanglement between perception and reasoning leads to systematic false positives (rewarding hallucinated visual premises) and false negatives (penalizing correct grounded statements), undermining both reranking and error localization. We introduce Explicit Visual Premise Verification (EVPV), a lightweight verification interface that conditions step scoring on the reliability of the visual premises a step depends on. The policy is prompted to produce a step-wise visual checklist that makes required visual facts explicit, while a constraint extractor independently derives structured visual constraints from the input image. EVPV matches checklist claims against these constraints to compute a scalar visual reliability signal, and calibrates PRM step rewards via reliability gating: rewards for visually dependent steps are attenuated when reliability is low and preserved when reliability is high. This decouples perceptual uncertainty from logical evaluation without per-step tool calls. Experiments on VisualProcessBench and six multimodal reasoning benchmarks show that EVPV improves step-level verification and consistently boosts Best-of-N reranking accuracy over strong baselines. Furthermore, injecting controlled corruption into the extracted constraints produces monotonic performance degradation, providing causal evidence that the gains arise from constraint fidelity and explicit premise verification rather than incidental prompt effects. Code is available at: https://github.com/Qwen-Applications/EVPV-PRM
Rationale Matters: Learning Transferable Rubrics via Proxy-Guided Critique for VLMReward Models
Mar 17, 2026Generative reward models (GRMs) for vision-language models (VLMs) often evaluate outputs via a three-stage pipeline: rubric generation, criterion-based scoring, and a final verdict. However, the intermediate rubric is rarely optimized directly. Prior work typically either treats rubrics as incidental or relies on expensive LLM-as-judge checks that provide no differentiable signal and limited training-time guidance. We propose Proxy-GRM, which introduces proxy-guided rubric verification into Reinforcement Learning (RL) to explicitly enhance rubric quality. Concretely, we train lightweight proxy agents (Proxy-SFT and Proxy-RL) that take a candidate rubric together with the original query and preference pair, and then predict the preference ordering using only the rubric as evidence. The proxy's prediction accuracy serves as a rubric-quality reward, incentivizing the model to produce rubrics that are internally consistent and transferable. With ~50k data samples, Proxy-GRM reaches state-of-the-art results on the VL-Reward Bench, Multimodal Reward Bench, and MM-RLHF-Reward Bench, outperforming the methods trained on four times the data. Ablations show Proxy-SFT is a stronger verifier than Proxy-RL, and implicit reward aggregation performs best. Crucially, the learned rubrics transfer to unseen evaluators, improving reward accuracy at test time without additional training. Our code is available at https://github.com/Qwen-Applications/Proxy-GRM.
Diffusion-based Synthetic Data Generation for Visible-Infrared Person Re-Identification
Mar 16, 2025The performance of models is intricately linked to the abundance of training data. In Visible-Infrared person Re-IDentification (VI-ReID) tasks, collecting and annotating large-scale images of each individual under various cameras and modalities is tedious, time-expensive, costly and must comply with data protection laws, posing a severe challenge in meeting dataset requirements. Current research investigates the generation of synthetic data as an efficient and privacy-ensuring alternative to collecting real data in the field. However, a specific data synthesis technique tailored for VI-ReID models has yet to be explored. In this paper, we present a novel data generation framework, dubbed Diffusion-based VI-ReID data Expansion (DiVE), that automatically obtain massive RGB-IR paired images with identity preserving by decoupling identity and modality to improve the performance of VI-ReID models. Specifically, identity representation is acquired from a set of samples sharing the same ID, whereas the modality of images is learned by fine-tuning the Stable Diffusion (SD) on modality-specific data. DiVE extend the text-driven image synthesis to identity-preserving RGB-IR multimodal image synthesis. This approach significantly reduces data collection and annotation costs by directly incorporating synthetic data into ReID model training. Experiments have demonstrated that VI-ReID models trained on synthetic data produced by DiVE consistently exhibit notable enhancements. In particular, the state-of-the-art method, CAJ, trained with synthetic images, achieves an improvement of about $9\%$ in mAP over the baseline on the LLCM dataset. Code: https://github.com/BorgDiven/DiVE
How to Inverting the Leverage Score Distribution?
Apr 21, 2024Leverage score is a fundamental problem in machine learning and theoretical computer science. It has extensive applications in regression analysis, randomized algorithms, and neural network inversion. Despite leverage scores are widely used as a tool, in this paper, we study a novel problem, namely the inverting leverage score problem. We analyze to invert the leverage score distributions back to recover model parameters. Specifically, given a leverage score $\sigma \in \mathbb{R}^n$, the matrix $A \in \mathbb{R}^{n \times d}$, and the vector $b \in \mathbb{R}^n$, we analyze the non-convex optimization problem of finding $x \in \mathbb{R}^d$ to minimize $\| \mathrm{diag}( \sigma ) - I_n \circ (A(x) (A(x)^\top A(x) )^{-1} A(x)^\top ) \|_F$, where $A(x):= S(x)^{-1} A \in \mathbb{R}^{n \times d} $, $S(x) := \mathrm{diag}(s(x)) \in \mathbb{R}^{n \times n}$ and $s(x) : = Ax - b \in \mathbb{R}^n$. Our theoretical studies include computing the gradient and Hessian, demonstrating that the Hessian matrix is positive definite and Lipschitz, and constructing first-order and second-order algorithms to solve this regression problem. Our work combines iterative shrinking and the induction hypothesis to ensure global convergence rates for the Newton method, as well as the properties of Lipschitz and strong convexity to guarantee the performance of gradient descent. This important study on inverting statistical leverage opens up numerous new applications in interpretation, data recovery, and security.
Local Convergence of Approximate Newton Method for Two Layer Nonlinear Regression
Nov 26, 2023There have been significant advancements made by large language models (LLMs) in various aspects of our daily lives. LLMs serve as a transformative force in natural language processing, finding applications in text generation, translation, sentiment analysis, and question-answering. The accomplishments of LLMs have led to a substantial increase in research efforts in this domain. One specific two-layer regression problem has been well-studied in prior works, where the first layer is activated by a ReLU unit, and the second layer is activated by a softmax unit. While previous works provide a solid analysis of building a two-layer regression, there is still a gap in the analysis of constructing regression problems with more than two layers. In this paper, we take a crucial step toward addressing this problem: we provide an analysis of a two-layer regression problem. In contrast to previous works, our first layer is activated by a softmax unit. This sets the stage for future analyses of creating more activation functions based on the softmax function. Rearranging the softmax function leads to significantly different analyses. Our main results involve analyzing the convergence properties of an approximate Newton method used to minimize the regularized training loss. We prove that the loss function for the Hessian matrix is positive definite and Lipschitz continuous under certain assumptions. This enables us to establish local convergence guarantees for the proposed training algorithm. Specifically, with an appropriate initialization and after $O(\log(1/\epsilon))$ iterations, our algorithm can find an $\epsilon$-approximate minimizer of the training loss with high probability. Each iteration requires approximately $O(\mathrm{nnz}(C) + d^\omega)$ time, where $d$ is the model size, $C$ is the input matrix, and $\omega < 2.374$ is the matrix multiplication exponent.
Zero-th Order Algorithm for Softmax Attention Optimization
Jul 17, 2023Large language models (LLMs) have brought about significant transformations in human society. Among the crucial computations in LLMs, the softmax unit holds great importance. Its helps the model generating a probability distribution on potential subsequent words or phrases, considering a series of input words. By utilizing this distribution, the model selects the most probable next word or phrase, based on the assigned probabilities. The softmax unit assumes a vital function in LLM training as it facilitates learning from data through the adjustment of neural network weights and biases. With the development of the size of LLMs, computing the gradient becomes expensive. However, Zero-th Order method can approximately compute the gradient with only forward passes. In this paper, we present a Zero-th Order algorithm specifically tailored for Softmax optimization. We demonstrate the convergence of our algorithm, highlighting its effectiveness in efficiently computing gradients for large-scale LLMs. By leveraging the Zeroth-Order method, our work contributes to the advancement of optimization techniques in the context of complex language models.
Attention Scheme Inspired Softmax Regression
Apr 26, 2023Large language models (LLMs) have made transformed changes for human society. One of the key computation in LLMs is the softmax unit. This operation is important in LLMs because it allows the model to generate a distribution over possible next words or phrases, given a sequence of input words. This distribution is then used to select the most likely next word or phrase, based on the probabilities assigned by the model. The softmax unit plays a crucial role in training LLMs, as it allows the model to learn from the data by adjusting the weights and biases of the neural network. In the area of convex optimization such as using central path method to solve linear programming. The softmax function has been used a crucial tool for controlling the progress and stability of potential function [Cohen, Lee and Song STOC 2019, Brand SODA 2020]. In this work, inspired the softmax unit, we define a softmax regression problem. Formally speaking, given a matrix $A \in \mathbb{R}^{n \times d}$ and a vector $b \in \mathbb{R}^n$, the goal is to use greedy type algorithm to solve \begin{align*} \min_{x} \| \langle \exp(Ax), {\bf 1}_n \rangle^{-1} \exp(Ax) - b \|_2^2. \end{align*} In certain sense, our provable convergence result provides theoretical support for why we can use greedy algorithm to train softmax function in practice.
Solving Regularized Exp, Cosh and Sinh Regression Problems
Mar 28, 2023In modern machine learning, attention computation is a fundamental task for training large language models such as Transformer, GPT-4 and ChatGPT. In this work, we study exponential regression problem which is inspired by the softmax/exp unit in the attention mechanism in large language models. The standard exponential regression is non-convex. We study the regularization version of exponential regression problem which is a convex problem. We use approximate newton method to solve in input sparsity time. Formally, in this problem, one is given matrix $A \in \mathbb{R}^{n \times d}$, $b \in \mathbb{R}^n$, $w \in \mathbb{R}^n$ and any of functions $\exp, \cosh$ and $\sinh$ denoted as $f$. The goal is to find the optimal $x$ that minimize $ 0.5 \| f(Ax) - b \|_2^2 + 0.5 \| \mathrm{diag}(w) A x \|_2^2$. The straightforward method is to use the naive Newton's method. Let $\mathrm{nnz}(A)$ denote the number of non-zeros entries in matrix $A$. Let $\omega$ denote the exponent of matrix multiplication. Currently, $\omega \approx 2.373$. Let $\epsilon$ denote the accuracy error. In this paper, we make use of the input sparsity and purpose an algorithm that use $\log ( \|x_0 - x^*\|_2 / \epsilon)$ iterations and $\widetilde{O}(\mathrm{nnz}(A) + d^{\omega} )$ per iteration time to solve the problem.
Self-Supervised Modality-Aware Multiple Granularity Pre-Training for RGB-Infrared Person Re-Identification
Dec 12, 2021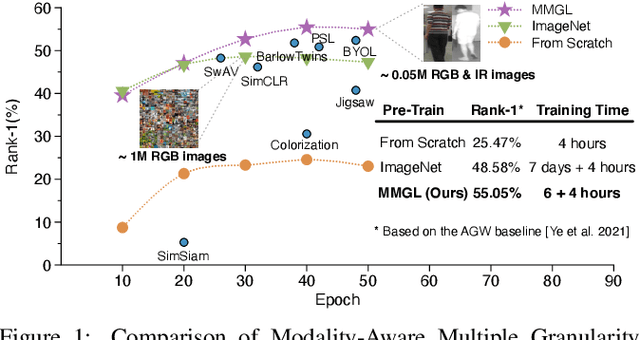
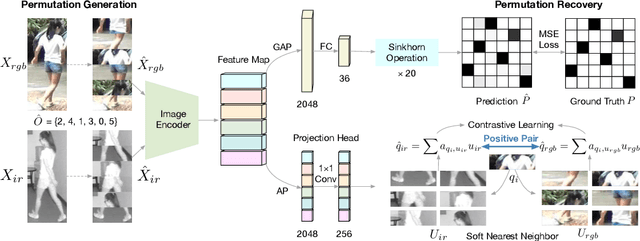
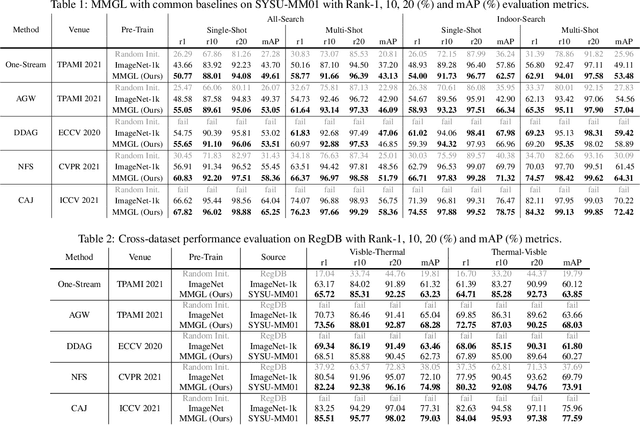
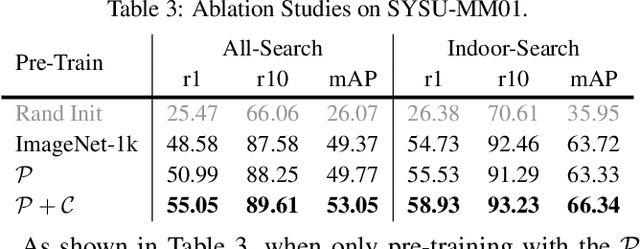
While RGB-Infrared cross-modality person re-identification (RGB-IR ReID) has enabled great progress in 24-hour intelligent surveillance, state-of-the-arts still heavily rely on fine-tuning ImageNet pre-trained networks. Due to the single-modality nature, such large-scale pre-training may yield RGB-biased representations that hinder the performance of cross-modality image retrieval. This paper presents a self-supervised pre-training alternative, named Modality-Aware Multiple Granularity Learning (MMGL), which directly trains models from scratch on multi-modality ReID datasets, but achieving competitive results without external data and sophisticated tuning tricks. Specifically, MMGL globally maps shuffled RGB-IR images into a shared latent permutation space and further improves local discriminability by maximizing agreement between cycle-consistent RGB-IR image patches. Experiments demonstrate that MMGL learns better representations (+6.47% Rank-1) with faster training speed (converge in few hours) and solider data efficiency (<5% data size) than ImageNet pre-training. The results also suggest it generalizes well to various existing models, losses and has promising transferability across datasets. The code will be released.