 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-based Synthetic Data Generation for Visible-Infrared Person Re-Identification
Mar 16, 2025The performance of models is intricately linked to the abundance of training data. In Visible-Infrared person Re-IDentification (VI-ReID) tasks, collecting and annotating large-scale images of each individual under various cameras and modalities is tedious, time-expensive, costly and must comply with data protection laws, posing a severe challenge in meeting dataset requirements. Current research investigates the generation of synthetic data as an efficient and privacy-ensuring alternative to collecting real data in the field. However, a specific data synthesis technique tailored for VI-ReID models has yet to be explored. In this paper, we present a novel data generation framework, dubbed Diffusion-based VI-ReID data Expansion (DiVE), that automatically obtain massive RGB-IR paired images with identity preserving by decoupling identity and modality to improve the performance of VI-ReID models. Specifically, identity representation is acquired from a set of samples sharing the same ID, whereas the modality of images is learned by fine-tuning the Stable Diffusion (SD) on modality-specific data. DiVE extend the text-driven image synthesis to identity-preserving RGB-IR multimodal image synthesis. This approach significantly reduces data collection and annotation costs by directly incorporating synthetic data into ReID model training. Experiments have demonstrated that VI-ReID models trained on synthetic data produced by DiVE consistently exhibit notable enhancements. In particular, the state-of-the-art method, CAJ, trained with synthetic images, achieves an improvement of about $9\%$ in mAP over the baseline on the LLCM dataset. Code: https://github.com/BorgDiven/DiVE
G$^2$DA: Geometry-Guided Dual-Alignment Learning for RGB-Infrared Person Re-Identification
Jun 15, 2021


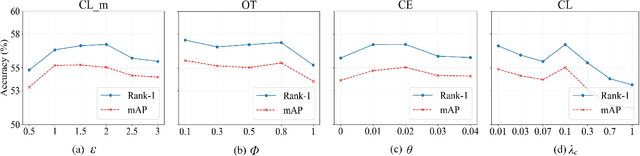
RGB-Infrared (IR) person re-identification aims to retrieve person-of-interest between heterogeneous modalities, suffering from large modality discrepancy caused by different sensory devices. Existing methods mainly focus on global-level modality alignment, whereas neglect sample-level modality divergence to some extent, leading to performance degradation. This paper attempts to find RGB-IR ReID solutions from tackling sample-level modality difference, and presents a Geometry-Guided Dual-Alignment learning framework (G$^2$DA), which jointly enhances modality-invariance and reinforces discriminability with human topological structure in features to boost the overall matching performance. Specifically, G$^2$DA extracts accurate body part features with a pose estimator, serving as a semantic bridge complementing the missing local details in global descriptor. Based on extracted local and global features, a novel distribution constraint derived from optimal transport is introduced to mitigate the modality gap in a fine-grained sample-level manner. Beyond pair-wise relations across two modalities, it additionally measures the structural similarity of different parts, thus both multi-level features and their relations are kept consistent in the common feature space. Considering the inherent human-topology information, we further advance a geometry-guided graph learning module to refine each part features, where relevant regions can be emphasized while meaningless ones are suppressed, effectively facilitating robust feature learning. Extensive experiments on two standard benchmark datasets validate the superiority of our proposed method, yielding competitive performance over the state-of-the-art approaches.