 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACFNet: Attentional Class Feature Network for Semantic Segmentation
Paper and Code
Oct 18, 2019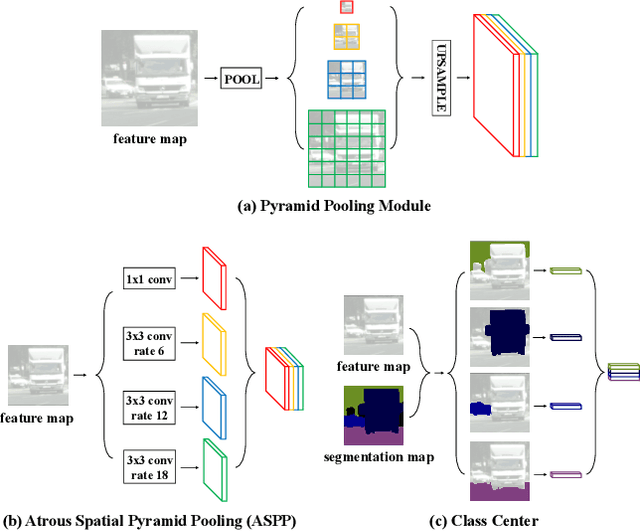
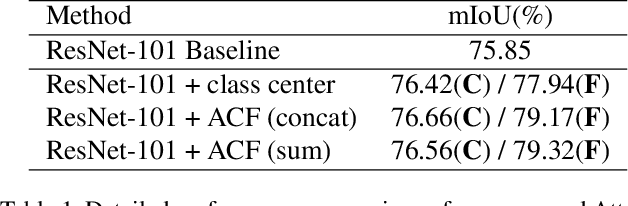
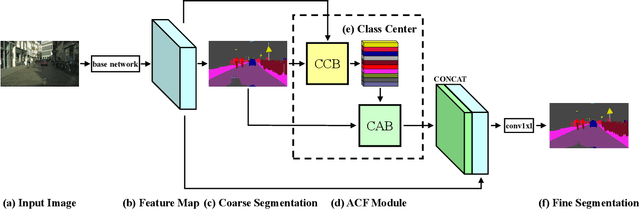
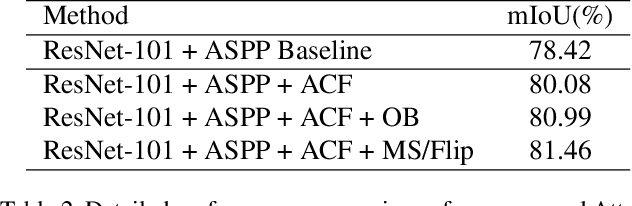
Recent works have made great progress in semantic segmentation by exploiting richer context, most of which are designed from a spatial perspective. In contrast to previous works, we present the concept of class center which extracts the global context from a categorical perspective. This class-level context describes the overall representation of each class in an image. We further propose a novel module, named Attentional Class Feature (ACF) module, to calculate and adaptively combine different class centers according to each pixel. Based on the ACF module, we introduce a coarse-to-fine segmentation network, called Attentional Class Feature Network (ACFNet), which can be composed of an ACF module and any off-the-shell segmentation network (base network). In this paper, we use two types of base networks to evaluate the effectiveness of ACFNet. We achieve new state-of-the-art performance of 81.85% mIoU on Cityscapes dataset with only finely annotated data used for training.