 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInter-event Interval Microscopy for Event Cameras
Apr 08, 2025Event cameras, an innovative bio-inspired sensor, differ from traditional cameras by sensing changes in intensity rather than directly perceiving intensity and recording these variations as a continuous stream of "events". The intensity reconstruction from these sparse events has long been a challenging problem. Previous approaches mainly focused on transforming motion-induced events into videos or achieving intensity imaging for static scenes by integrating modulation devices at the event camera acquisition end. In this paper, for the first time, we achieve event-to-intensity conversion using a static event camera for both static and dynamic scenes in fluorescence microscopy. Unlike conventional methods that primarily rely on event integration, the proposed Inter-event Interval Microscopy (IEIM) quantifies the time interval between consecutive events at each pixel. With a fixed threshold in the event camera, the time interval can precisely represent the intensity. At the hardware level, the proposed IEIM integrates a pulse light modulation device within a microscope equipped with an event camera, termed Pulse Modulation-based Event-driven Fluorescence Microscopy. Additionally, we have collected IEIMat dataset under various scenes including high dynamic range and high-speed scenarios. Experimental results on the IEIMat dataset demonstrate that the proposed IEIM achieves superior spatial and temporal resolution, as well as a higher dynamic range, with lower bandwidth compared to other methods. The code and the IEIMat dataset will be made publicly available.
ACFNet: Attentional Class Feature Network for Semantic Segmentation
Oct 18, 2019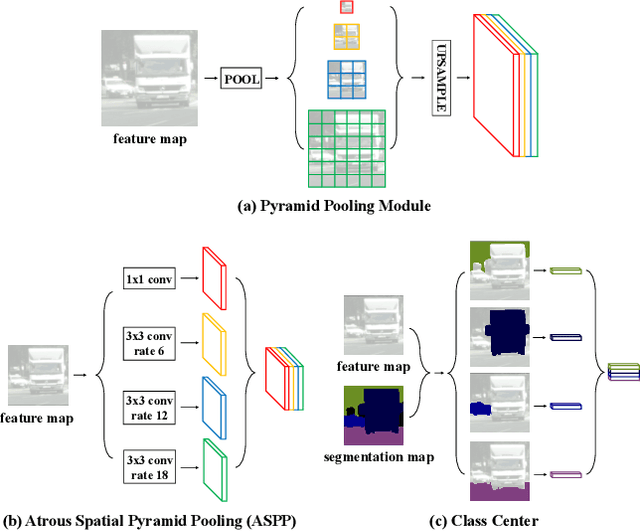
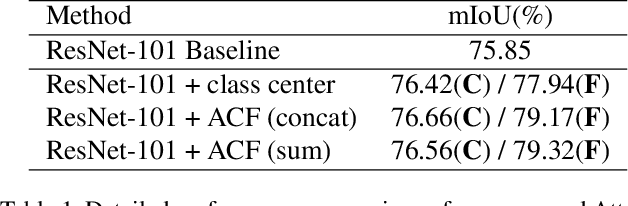
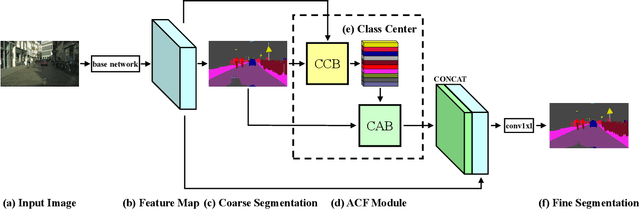
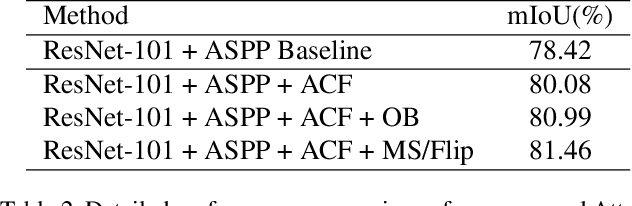
Recent works have made great progress in semantic segmentation by exploiting richer context, most of which are designed from a spatial perspective. In contrast to previous works, we present the concept of class center which extracts the global context from a categorical perspective. This class-level context describes the overall representation of each class in an image. We further propose a novel module, named Attentional Class Feature (ACF) module, to calculate and adaptively combine different class centers according to each pixel. Based on the ACF module, we introduce a coarse-to-fine segmentation network, called Attentional Class Feature Network (ACFNet), which can be composed of an ACF module and any off-the-shell segmentation network (base network). In this paper, we use two types of base networks to evaluate the effectiveness of ACFNet. We achieve new state-of-the-art performance of 81.85% mIoU on Cityscapes dataset with only finely annotated data used for training.
Grand Challenge of 106-Point Facial Landmark Localization
May 09, 2019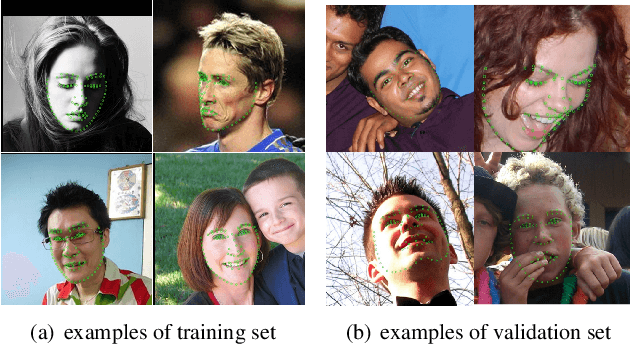
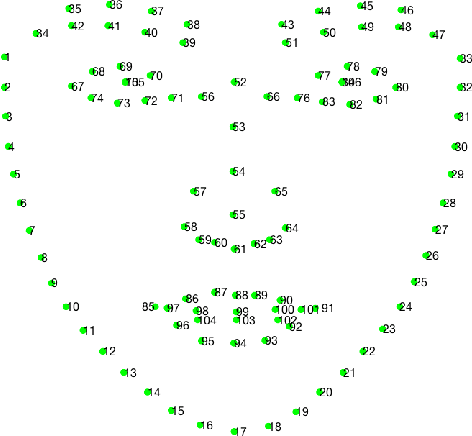

Facial landmark localization is a very crucial step in numerous face related applications, such as face recognition, facial pose estimation, face image synthesis, etc. However, previous competitions on facial landmark localization (i.e., the 300-W, 300-VW and Menpo challenges) aim to predict 68-point landmarks, which are incompetent to depict the structure of facial components. In order to overcome this problem, we construct a challenging dataset, named JD-landmark. Each image is manually annotated with 106-point landmarks. This dataset covers large variations on pose and expression, which brings a lot of difficulties to predict accurate landmarks. We hold a 106-point facial landmark localization competition1 on this dataset in conjunction with IEEE International Conference on Multimedia and Expo (ICME) 2019. The purpose of this competition is to discover effective and robust facial landmark localization approaches.