 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciVisAgentBench: A Benchmark for Evaluating Scientific Data Analysis and Visualization Agents
Mar 31, 2026Recent advances in large language models (LLMs) have enabled agentic systems that translate natural language intent into executable scientific visualization (SciVis) tasks. Despite rapid progress, the community lacks a principled and reproducible benchmark for evaluating these emerging SciVis agents in realistic, multi-step analysis settings. We present SciVisAgentBench, a comprehensive and extensible benchmark for evaluating scientific data analysis and visualization agents. Our benchmark is grounded in a structured taxonomy spanning four dimensions: application domain, data type, complexity level, and visualization operation. It currently comprises 108 expert-crafted cases covering diverse SciVis scenarios. To enable reliable assessment, we introduce a multimodal outcome-centric evaluation pipeline that combines LLM-based judging with deterministic evaluators, including image-based metrics, code checkers, rule-based verifiers, and case-specific evaluators. We also conduct a validity study with 12 SciVis experts to examine the agreement between human and LLM judges. Using this framework, we evaluate representative SciVis agents and general-purpose coding agents to establish initial baselines and reveal capability gaps. SciVisAgentBench is designed as a living benchmark to support systematic comparison, diagnose failure modes, and drive progress in agentic SciVis. The benchmark is available at https://scivisagentbench.github.io/.
Extracting Complex Topology from Multivariate Functional Approximation: Contours, Jacobi Sets, and Ridge-Valley Graphs
Aug 11, 2025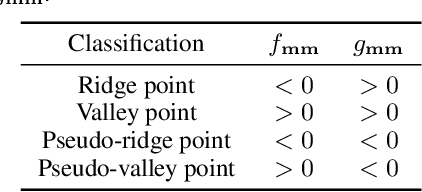
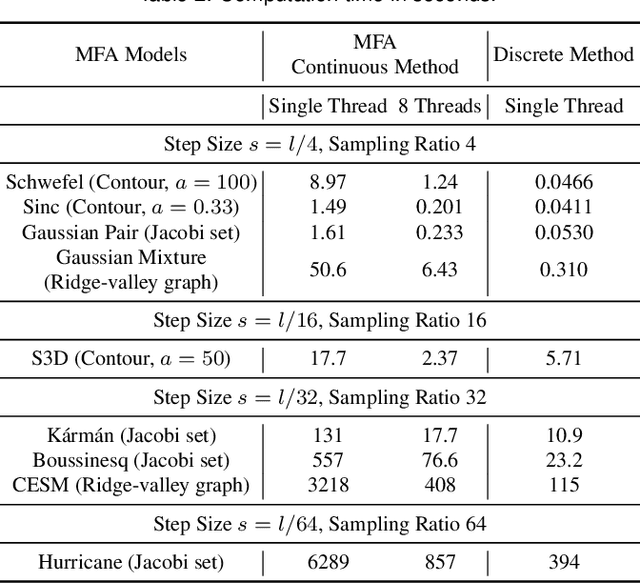
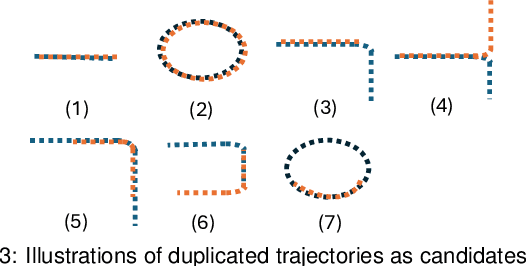
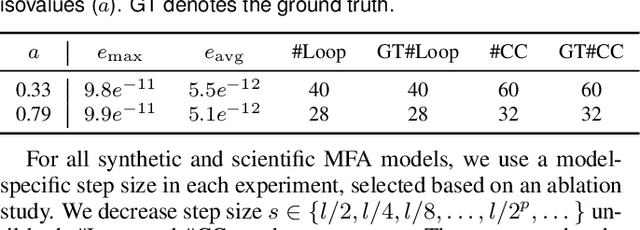
Implicit continuous models, such as functional models and implicit neural networks, are an increasingly popular method for replacing discrete data representations with continuous, high-order, and differentiable surrogates. These models offer new perspectives on the storage, transfer, and analysis of scientific data. In this paper, we introduce the first framework to directly extract complex topological features -- contours, Jacobi sets, and ridge-valley graphs -- from a type of continuous implicit model known as multivariate functional approximation (MFA). MFA replaces discrete data with continuous piecewise smooth functions. Given an MFA model as the input, our approach enables direct extraction of complex topological features from the model, without reverting to a discrete representation of the model. Our work is easily generalizable to any continuous implicit model that supports the queries of function values and high-order derivatives. Our work establishes the building blocks for performing topological data analysis and visualization on implicit continuous models.
Search is All You Need for Few-shot Anomaly Detection
Apr 16, 2025



Few-shot anomaly detection (FSAD) has emerged as a crucial yet challenging task in industrial inspection, where normal distribution modeling must be accomplished with only a few normal images. While existing approaches typically employ multi-modal foundation models combining language and vision modalities for prompt-guided anomaly detection, these methods often demand sophisticated prompt engineering and extensive manual tuning. In this paper, we demonstrate that a straightforward nearest-neighbor search framework can surpass state-of-the-art performance in both single-class and multi-class FSAD scenarios. Our proposed method, VisionAD, consists of four simple yet essential components: (1) scalable vision foundation models that extract universal and discriminative features; (2) dual augmentation strategies - support augmentation to enhance feature matching adaptability and query augmentation to address the oversights of single-view prediction; (3) multi-layer feature integration that captures both low-frequency global context and high-frequency local details with minimal computational overhead; and (4) a class-aware visual memory bank enabling efficient one-for-all multi-class detection. Extensive evaluations across MVTec-AD, VisA, and Real-IAD benchmarks demonstrate VisionAD's exceptional performance. Using only 1 normal images as support, our method achieves remarkable image-level AUROC scores of 97.4%, 94.8%, and 70.8% respectively, outperforming current state-of-the-art approaches by significant margins (+1.6%, +3.2%, and +1.4%). The training-free nature and superior few-shot capabilities of VisionAD make it particularly appealing for real-world applications where samples are scarce or expensive to obtain. Code is available at https://github.com/Qiqigeww/VisionAD.
Regularized Multi-Decoder Ensemble for an Error-Aware Scene Representation Network
Jul 26, 2024



Feature grid Scene Representation Networks (SRNs) have been applied to scientific data as compact functional surrogates for analysis and visualization. As SRNs are black-box lossy data representations, assessing the prediction quality is critical for scientific visualization applications to ensure that scientists can trust the information being visualized. Currently, existing architectures do not support inference time reconstruction quality assessment, as coordinate-level errors cannot be evaluated in the absence of ground truth data. We propose a parameter-efficient multi-decoder SRN (MDSRN) ensemble architecture consisting of a shared feature grid with multiple lightweight multi-layer perceptron decoders. MDSRN can generate a set of plausible predictions for a given input coordinate to compute the mean as the prediction of the multi-decoder ensemble and the variance as a confidence score. The coordinate-level variance can be rendered along with the data to inform the reconstruction quality, or be integrated into uncertainty-aware volume visualization algorithms. To prevent the misalignment between the quantified variance and the prediction quality, we propose a novel variance regularization loss for ensemble learning that promotes the Regularized multi-decoder SRN (RMDSRN) to obtain a more reliable variance that correlates closely to the true model error. We comprehensively evaluate the quality of variance quantification and data reconstruction of Monte Carlo Dropout, Mean Field Variational Inference, Deep Ensemble, and Predicting Variance compared to the proposed MDSRN and RMDSRN across diverse scalar field datasets. We demonstrate that RMDSRN attains the most accurate data reconstruction and competitive variance-error correlation among uncertain SRNs under the same neural network parameter budgets.
TROPHY: A Topologically Robust Physics-Informed Tracking Framework for Tropical Cyclones
Jul 28, 2023



Tropical cyclones (TCs) are among the most destructive weather systems. Realistically and efficiently detecting and tracking TCs are critical for assessing their impacts and risks. Recently, a multilevel robustness framework has been introduced to study the critical points of time-varying vector fields. The framework quantifies the robustness of critical points across varying neighborhoods. By relating the multilevel robustness with critical point tracking, the framework has demonstrated its potential in cyclone tracking. An advantage is that it identifies cyclonic features using only 2D wind vector fields, which is encouraging as most tracking algorithms require multiple dynamic and thermodynamic variables at different altitudes. A disadvantage is that the framework does not scale well computationally for datasets containing a large number of cyclones. This paper introduces a topologically robust physics-informed tracking framework (TROPHY) for TC tracking. The main idea is to integrate physical knowledge of TC to drastically improve the computational efficiency of multilevel robustness framework for large-scale climate datasets. First, during preprocessing, we propose a physics-informed feature selection strategy to filter 90% of critical points that are short-lived and have low stability, thus preserving good candidates for TC tracking. Second, during in-processing, we impose constraints during the multilevel robustness computation to focus only on physics-informed neighborhoods of TCs. We apply TROPHY to 30 years of 2D wind fields from reanalysis data in ERA5 and generate a number of TC tracks. In comparison with the observed tracks, we demonstrate that TROPHY can capture TC characteristics that are comparable to and sometimes even better than a well-validated TC tracking algorithm that requires multiple dynamic and thermodynamic scalar fields.
Neural Stream Functions
Jul 16, 2023We present a neural network approach to compute stream functions, which are scalar functions with gradients orthogonal to a given vector field. As a result, isosurfaces of the stream function extract stream surfaces, which can be visualized to analyze flow features. Our approach takes a vector field as input and trains an implicit neural representation to learn a stream function for that vector field. The network learns to map input coordinates to a stream function value by minimizing the inner product of the gradient of the neural network's output and the vector field. Since stream function solutions may not be unique, we give optional constraints for the network to learn particular stream functions of interest. Specifically, we introduce regularizing loss functions that can optionally be used to generate stream function solutions whose stream surfaces follow the flow field's curvature, or that can learn a stream function that includes a stream surface passing through a seeding rake. We also discuss considerations for properly visualizing the trained implicit network and extracting artifact-free surfaces. We compare our results with other implicit solutions and present qualitative and quantitative results for several synthetic and simulated vector fields.
Adaptively Placed Multi-Grid Scene Representation Networks for Large-Scale Data Visualization
Jul 16, 2023Scene representation networks (SRNs) have been recently proposed for compression and visualization of scientific data. However, state-of-the-art SRNs do not adapt the allocation of available network parameters to the complex features found in scientific data, leading to a loss in reconstruction quality. We address this shortcoming with an adaptively placed multi-grid SRN (APMGSRN) and propose a domain decomposition training and inference technique for accelerated parallel training on multi-GPU systems. We also release an open-source neural volume rendering application that allows plug-and-play rendering with any PyTorch-based SRN. Our proposed APMGSRN architecture uses multiple spatially adaptive feature grids that learn where to be placed within the domain to dynamically allocate more neural network resources where error is high in the volume, improving state-of-the-art reconstruction accuracy of SRNs for scientific data without requiring expensive octree refining, pruning, and traversal like previous adaptive models. In our domain decomposition approach for representing large-scale data, we train an set of APMGSRNs in parallel on separate bricks of the volume to reduce training time while avoiding overhead necessary for an out-of-core solution for volumes too large to fit in GPU memory. After training, the lightweight SRNs are used for realtime neural volume rendering in our open-source renderer, where arbitrary view angles and transfer functions can be explored. A copy of this paper, all code, all models used in our experiments, and all supplemental materials and videos are available at https://github.com/skywolf829/APMGSRN.
Multilevel Robustness for 2D Vector Field Feature Tracking, Selection, and Comparison
Sep 19, 2022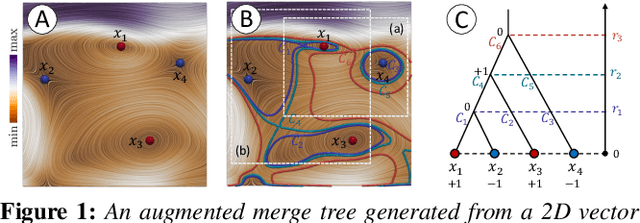
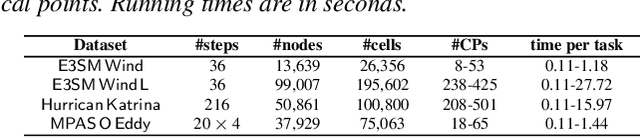
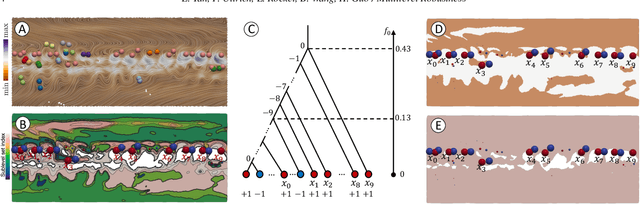
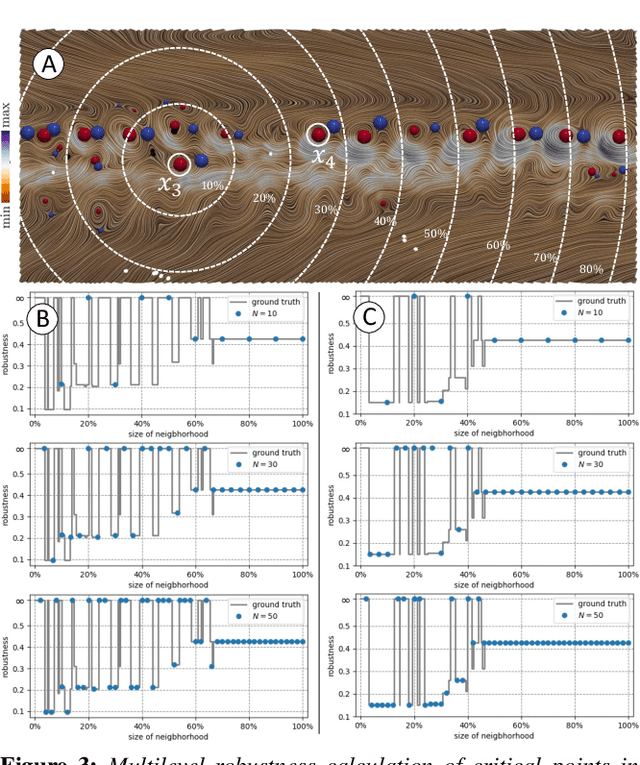
Critical point tracking is a core topic in scientific visualization for understanding the dynamic behavior of time-varying vector field data. The topological notion of robustness has been introduced recently to quantify the structural stability of critical points, that is, the robustness of a critical point is the minimum amount of perturbation to the vector field necessary to cancel it. A theoretical basis has been established previously that relates critical point tracking with the notion of robustness, in particular, critical points could be tracked based on their closeness in stability, measured by robustness, instead of just distance proximities within the domain. However, in practice, the computation of classic robustness may produce artifacts when a critical point is close to the boundary of the domain; thus, we do not have a complete picture of the vector field behavior within its local neighborhood. To alleviate these issues, we introduce a multilevel robustness framework for the study of 2D time-varying vector fields. We compute the robustness of critical points across varying neighborhoods to capture the multiscale nature of the data and to mitigate the boundary effect suffered by the classic robustness computation. We demonstrate via experiments that such a new notion of robustness can be combined seamlessly with existing feature tracking algorithms to improve the visual interpretability of vector fields in terms of feature tracking, selection, and comparison for large-scale scientific simulations. We observe, for the first time, that the minimum multilevel robustness is highly correlated with physical quantities used by domain scientists in studying a real-world tropical cyclone dataset. Such observation helps to increase the physical interpretability of robustness.
VDL-Surrogate: A View-Dependent Latent-based Model for Parameter Space Exploration of Ensemble Simulations
Jul 29, 2022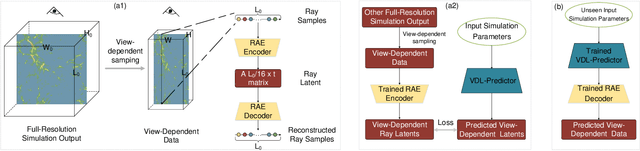
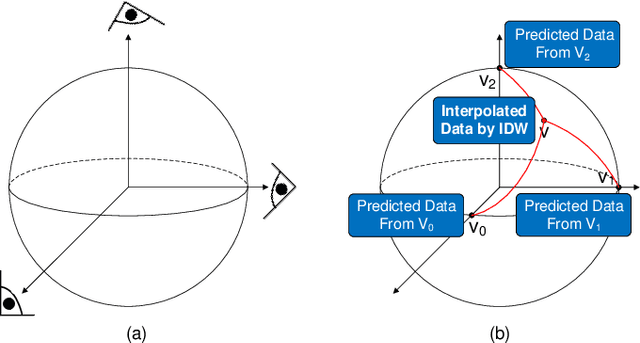
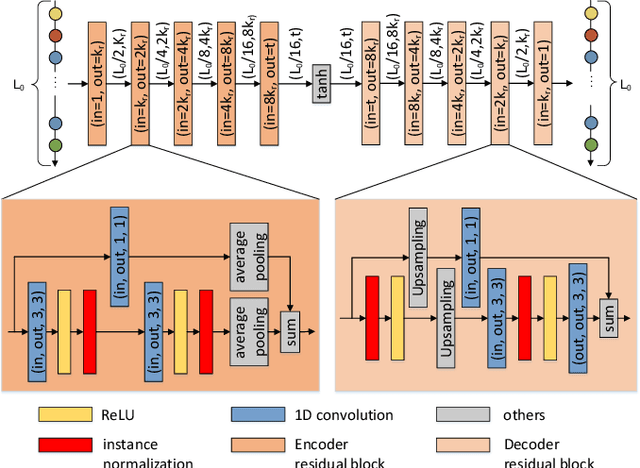

We propose VDL-Surrogate, a view-dependent neural-network-latent-based surrogate model for parameter space exploration of ensemble simulations that allows high-resolution visualizations and user-specified visual mappings. Surrogate-enabled parameter space exploration allows domain scientists to preview simulation results without having to run a large number of computationally costly simulations. Limited by computational resources, however, existing surrogate models may not produce previews with sufficient resolution for visualization and analysis. To improve the efficient use of computational resources and support high-resolution exploration, we perform ray casting from different viewpoints to collect samples and produce compact latent representations. This latent encoding process reduces the cost of surrogate model training while maintaining the output quality. In the model training stage, we select viewpoints to cover the whole viewing sphere and train corresponding VDL-Surrogate models for the selected viewpoints. In the model inference stage, we predict the latent representations at previously selected viewpoints and decode the latent representations to data space. For any given viewpoint, we make interpolations over decoded data at selected viewpoints and generate visualizations with user-specified visual mappings. We show the effectiveness and efficiency of VDL-Surrogate in cosmological and ocean simulations with quantitative and qualitative evaluations. Source code is publicly available at https://github.com/trainsn/VDL-Surrogate.
GNN-Surrogate: A Hierarchical and Adaptive Graph Neural Network for Parameter Space Exploration of Unstructured-Mesh Ocean Simulations
Feb 21, 2022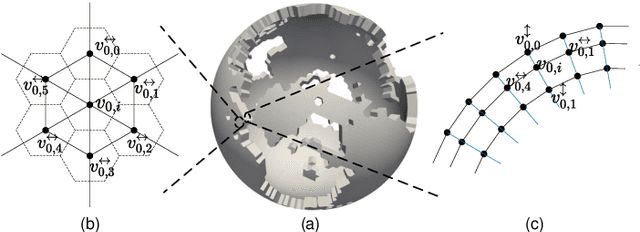

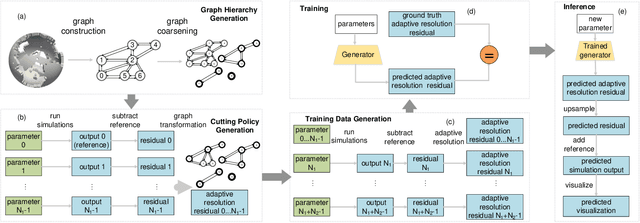
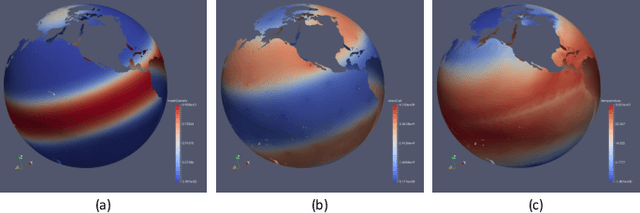
We propose GNN-Surrogate, a graph neural network-based surrogate model to explore the parameter space of ocean climate simulations. Parameter space exploration is important for domain scientists to understand the influence of input parameters (e.g., wind stress) on the simulation output (e.g., temperature). The exploration requires scientists to exhaust the complicated parameter space by running a batch of computationally expensive simulations. Our approach improves the efficiency of parameter space exploration with a surrogate model that predicts the simulation outputs accurately and efficiently. Specifically, GNN-Surrogate predicts the output field with given simulation parameters so scientists can explore the simulation parameter space with visualizations from user-specified visual mappings. Moreover, our graph-based techniques are designed for unstructured meshes, making the exploration of simulation outputs on irregular grids efficient. For efficient training, we generate hierarchical graphs and use adaptive resolutions. We give quantitative and qualitative evaluations on the MPAS-Ocean simulation to demonstrate the effectiveness and efficiency of GNN-Surrogate. Source code is publicly available at https://github.com/trainsn/GNN-Surrogate.